 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs as annotators of credibility assessment in Danish asylum decisions: evaluating classification performance and errors beyond aggregated metrics
May 13, 2026Off-the-shelf large language models (LLMs) are increasingly used to automate text annotation, yet their effectiveness remains underexplored for underrepresented languages and specialized domains where the class definition requires subtle expert understanding. We investigate LLM-based annotation for a novel legal NLP task: identifying the presence and sentiment of credibility assessments in asylum decision texts. We introduce RAB-Cred, a Danish text classification dataset featuring high-quality, expert annotations and valuable metadata such as annotator confidence and asylum case outcome. We benchmark 21 open-weight models and 30 system-user prompt combinations for this task, and systematically evaluate the effect of model and prompt choice for zero-shot and few-shot classification. We zoom in on the errors made by top-performing models and prompts, investigating error consistency across LLMs, inter-class confusion, correlation with human confidence and sample-wise difficulty and severity of LLM mistakes. Our results confirm the potential of LLMs for cost-effective labeling of asylum decisions, but highlight the imperfect and inconsistent nature of LLM annotators, and the need to look beyond the predictions of a single, arbitrarily chosen model. The RAB-Cred dataset and code are available at https://github.com/glhr/RAB-Cred
Out of Context: Reliability in Multimodal Anomaly Detection Requires Contextual Inference
Apr 14, 2026Anomaly detection aims to identify observations that deviate from expected behavior. Because anomalous events are inherently sparse, most frameworks are trained exclusively on normal data to learn a single reference model of normality. This implicitly assumes that normal behavior can be captured by a single, unconditional reference distribution. In practice, however, anomalies are often context-dependent: A specific observation may be normal under one operating condition, yet anomalous under another. As machine learning systems are deployed in dynamic and heterogeneous environments, these fixed-context assumptions introduce structural ambiguity, i.e., the inability to distinguish contextual variation from genuine abnormality under marginal modeling, leading to unstable performance and unreliable anomaly assessments. While modern sensing systems frequently collect multimodal data capturing complementary aspects of both system behavior and operating conditions, existing methods treat all data streams equally, without distinguishing contextual information from anomaly-relevant signals. As a result, abnormality is often evaluated without explicitly conditioning on operating conditions. We argue that multimodal anomaly detection should be reframed as a cross-modal contextual inference problem, in which modalities play asymmetric roles, separating context from observation, to define abnormality conditionally rather than relative to a single global reference. This perspective has implications for model design, evaluation protocols, and benchmark construction, and outline open research challenges toward robust, context-aware multimodal anomaly detection.
Only Whats Necessary: Pareto Optimal Data Minimization for Privacy Preserving Video Anomaly Detection
Mar 27, 2026Video anomaly detection (VAD) systems are increasingly deployed in safety critical environments and require a large amount of data for accurate detection. However, such data may contain personally identifiable information (PII), including facial cues and sensitive demographic attributes, creating compliance challenges under the EU General Data Protection Regulation (GDPR). In particular, GDPR requires that personal data be limited to what is strictly necessary for a specified processing purpose. To address this, we introduce Only What's Necessary, a privacy-by-design framework for VAD that explicitly controls the amount and type of visual information exposed to the detection pipeline. The framework combines breadth based and depth based data minimization mechanisms to suppress PII while preserving cues relevant to anomaly detection. We evaluate a range of minimization configurations by feeding the minimized videos to both a VAD model and a privacy inference model. We employ two ranking based methods, along with Pareto analysis, to characterize the resulting trade off between privacy and utility. From the non-dominated frontier, we identify sweet spot operating points that minimize personal data exposure with limited degradation in detection performance. Extensive experiments on publicly available datasets demonstrate the effectiveness of the proposed framework.
A Hyperbolic Perspective on Hierarchical Structure in Object-Centric Scene Representations
Mar 14, 2026Slot attention has emerged as a powerful framework for unsupervised object-centric learning, decomposing visual scenes into a small set of compact vector representations called \emph{slots}, each capturing a distinct region or object. However, these slots are learned in Euclidean space, which provides no geometric inductive bias for the hierarchical relationships that naturally structure visual scenes. In this work, we propose a simple post-hoc pipeline to project Euclidean slot embeddings onto the Lorentz hyperboloid of hyperbolic space, without modifying the underlying training pipeline. We construct five-level visual hierarchies directly from slot attention masks and analyse whether hyperbolic geometry reveals latent hierarchical structure that remains invisible in Euclidean space. Integrating our pipeline with SPOT (images), VideoSAUR (video), and SlotContrast (video), We find that hyperbolic projection exposes a consistent scene-level to object-level organisation, where coarse slots occupy greater manifold depth than fine slots, which is absent in Euclidean space. We further identify a "curvature--task tradeoff": low curvature ($c{=}0.2$) matches or outperforms Euclidean on parent slot retrieval, while moderate curvature ($c{=}0.5$) achieves better inter-level separation. Together, these findings suggest that slot representations already encode latent hierarchy that hyperbolic geometry reveals, motivating end-to-end hyperbolic training as a natural next step. Code and models are available at \href{https://github.com/NeeluMadan/HHS}{github.com/NeeluMadan/HHS}.
AdaSpot: Spend Resolution Where It Matters for Precise Event Spotting
Feb 25, 2026Precise Event Spotting aims to localize fast-paced actions or events in videos with high temporal precision, a key task for applications in sports analytics, robotics, and autonomous systems. Existing methods typically process all frames uniformly, overlooking the inherent spatio-temporal redundancy in video data. This leads to redundant computation on non-informative regions while limiting overall efficiency. To remain tractable, they often spatially downsample inputs, losing fine-grained details crucial for precise localization. To address these limitations, we propose \textbf{AdaSpot}, a simple yet effective framework that processes low-resolution videos to extract global task-relevant features while adaptively selecting the most informative region-of-interest in each frame for high-resolution processing. The selection is performed via an unsupervised, task-aware strategy that maintains spatio-temporal consistency across frames and avoids the training instability of learnable alternatives. This design preserves essential fine-grained visual cues with a marginal computational overhead compared to low-resolution-only baselines, while remaining far more efficient than uniform high-resolution processing. Experiments on standard PES benchmarks demonstrate that \textbf{AdaSpot} achieves state-of-the-art performance under strict evaluation metrics (\eg, $+3.96$ and $+2.26$ mAP$@0$ frames on Tennis and FineDiving), while also maintaining strong results under looser metrics. Code is available at: \href{https://github.com/arturxe2/AdaSpot}{https://github.com/arturxe2/AdaSpot}.
How to Sample High Quality 3D Fractals for Action Recognition Pre-Training?
Feb 12, 2026Synthetic datasets are being recognized in the deep learning realm as a valuable alternative to exhaustively labeled real data. One such synthetic data generation method is Formula Driven Supervised Learning (FDSL), which can provide an infinite number of perfectly labeled data through a formula driven approach, such as fractals or contours. FDSL does not have common drawbacks like manual labor, privacy and other ethical concerns. In this work we generate 3D fractals using 3D Iterated Function Systems (IFS) for pre-training an action recognition model. The fractals are temporally transformed to form a video that is used as a pre-training dataset for downstream task of action recognition. We find that standard methods of generating fractals are slow and produce degenerate 3D fractals. Therefore, we systematically explore alternative ways of generating fractals and finds that overly-restrictive approaches, while generating aesthetically pleasing fractals, are detrimental for downstream task performance. We propose a novel method, Targeted Smart Filtering, to address both the generation speed and fractal diversity issue. The method reports roughly 100 times faster sampling speed and achieves superior downstream performance against other 3D fractal filtering methods.
Comparing Euclidean and Hyperbolic K-Means for Generalized Category Discovery
Feb 04, 2026Hyperbolic representation learning has been widely used to extract implicit hierarchies within data, and recently it has found its way to the open-world classification task of Generalized Category Discovery (GCD). However, prior hyperbolic GCD methods only use hyperbolic geometry for representation learning and transform back to Euclidean geometry when clustering. We hypothesize this is suboptimal. Therefore, we present Hyperbolic Clustered GCD (HC-GCD), which learns embeddings in the Lorentz Hyperboloid model of hyperbolic geometry, and clusters these embeddings directly in hyperbolic space using a hyperbolic K-Means algorithm. We test our model on the Semantic Shift Benchmark datasets, and demonstrate that HC-GCD is on par with the previous state-of-the-art hyperbolic GCD method. Furthermore, we show that using hyperbolic K-Means leads to better accuracy than Euclidean K-Means. We carry out ablation studies showing that clipping the norm of the Euclidean embeddings leads to decreased accuracy in clustering unseen classes, and increased accuracy for seen classes, while the overall accuracy is dataset dependent. We also show that using hyperbolic K-Means leads to more consistent clusters when varying the label granularity.
Sea-ing Through Scattered Rays: Revisiting the Image Formation Model for Realistic Underwater Image Generation
Sep 18, 2025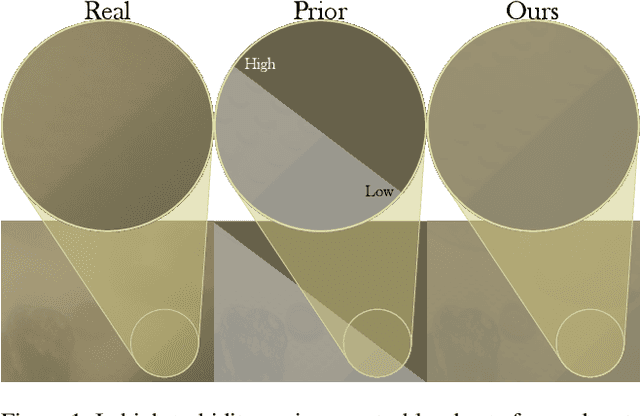



In recent years, the underwater image formation model has found extensive use in the generation of synthetic underwater data. Although many approaches focus on scenes primarily affected by discoloration, they often overlook the model's ability to capture the complex, distance-dependent visibility loss present in highly turbid environments. In this work, we propose an improved synthetic data generation pipeline that includes the commonly omitted forward scattering term, while also considering a nonuniform medium. Additionally, we collected the BUCKET dataset under controlled turbidity conditions to acquire real turbid footage with the corresponding reference images. Our results demonstrate qualitative improvements over the reference model, particularly under increasing turbidity, with a selection rate of 82. 5\% by survey participants. Data and code can be accessed on the project page: vap.aau.dk/sea-ing-through-scattered-rays.
SoccerNet 2025 Challenges Results
Aug 26, 2025The SoccerNet 2025 Challenges mark the fifth annual edition of the SoccerNet open benchmarking effort, dedicated to advancing computer vision research in football video understanding. This year's challenges span four vision-based tasks: (1) Team Ball Action Spotting, focused on detecting ball-related actions in football broadcasts and assigning actions to teams; (2) Monocular Depth Estimation, targeting the recovery of scene geometry from single-camera broadcast clips through relative depth estimation for each pixel; (3) Multi-View Foul Recognition, requiring the analysis of multiple synchronized camera views to classify fouls and their severity; and (4) Game State Reconstruction, aimed at localizing and identifying all players from a broadcast video to reconstruct the game state on a 2D top-view of the field. Across all tasks, participants were provided with large-scale annotated datasets, unified evaluation protocols, and strong baselines as starting points. This report presents the results of each challenge, highlights the top-performing solutions, and provides insights into the progress made by the community. The SoccerNet Challenges continue to serve as a driving force for reproducible, open research at the intersection of computer vision, artificial intelligence, and sports. Detailed information about the tasks, challenges, and leaderboards can be found at https://www.soccer-net.org, with baselines and development kits available at https://github.com/SoccerNet.
COOkeD: Ensemble-based OOD detection in the era of zero-shot CLIP
Jul 30, 2025Out-of-distribution (OOD) detection is an important building block in trustworthy image recognition systems as unknown classes may arise at test-time. OOD detection methods typically revolve around a single classifier, leading to a split in the research field between the classical supervised setting (e.g. ResNet18 classifier trained on CIFAR100) vs. the zero-shot setting (class names fed as prompts to CLIP). In both cases, an overarching challenge is that the OOD detection performance is implicitly constrained by the classifier's capabilities on in-distribution (ID) data. In this work, we show that given a little open-mindedness from both ends, remarkable OOD detection can be achieved by instead creating a heterogeneous ensemble - COOkeD combines the predictions of a closed-world classifier trained end-to-end on a specific dataset, a zero-shot CLIP classifier, and a linear probe classifier trained on CLIP image features. While bulky at first sight, this approach is modular, post-hoc and leverages the availability of pre-trained VLMs, thus introduces little overhead compared to training a single standard classifier. We evaluate COOkeD on popular CIFAR100 and ImageNet benchmarks, but also consider more challenging, realistic settings ranging from training-time label noise, to test-time covariate shift, to zero-shot shift which has been previously overlooked. Despite its simplicity, COOkeD achieves state-of-the-art performance and greater robustness compared to both classical and CLIP-based OOD detection methods. Code is available at https://github.com/glhr/COOkeD