 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Anomaly Detection with Contours - A Study
Mar 25, 2025In Pose-based Video Anomaly Detection prior art is rooted on the assumption that abnormal events can be mostly regarded as a result of uncommon human behavior. Opposed to utilizing skeleton representations of humans, however, we investigate the potential of learning recurrent motion patterns of normal human behavior using 2D contours. Keeping all advantages of pose-based methods, such as increased object anonymization, the shift from human skeletons to contours is hypothesized to leave the opportunity to cover more object categories open for future research. We propose formulating the problem as a regression and a classification task, and additionally explore two distinct data representation techniques for contours. To further reduce the computational complexity of Pose-based Video Anomaly Detection solutions, all methods in this study are based on shallow Neural Networks from the field of Deep Learning, and evaluated on the three most prominent benchmark datasets within Video Anomaly Detection and their human-related counterparts, totaling six datasets. Our results indicate that this novel perspective on Pose-based Video Anomaly Detection marks a promising direction for future research.
Bounding Boxes and Probabilistic Graphical Models: Video Anomaly Detection Simplified
Jul 08, 2024
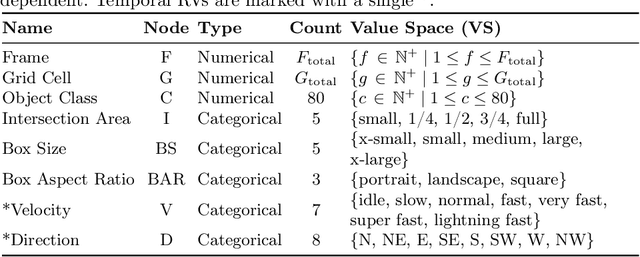
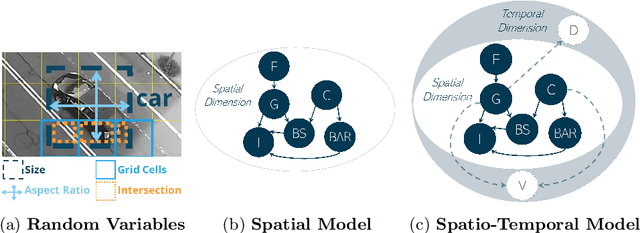
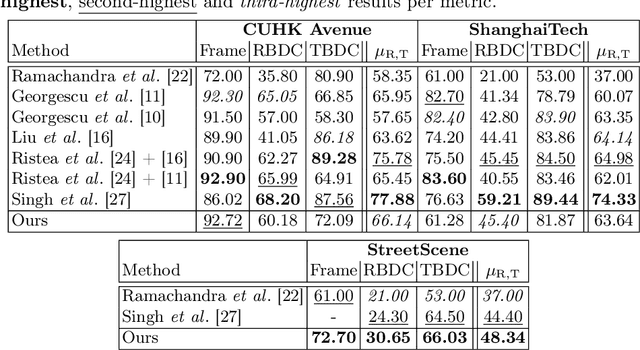
In this study, we formulate the task of Video Anomaly Detection as a probabilistic analysis of object bounding boxes. We hypothesize that the representation of objects via their bounding boxes only, can be sufficient to successfully identify anomalous events in a scene. The implied value of this approach is increased object anonymization, faster model training and fewer computational resources. This can particularly benefit applications within video surveillance running on edge devices such as cameras. We design our model based on human reasoning which lends itself to explaining model output in human-understandable terms. Meanwhile, the slowest model trains within less than 7 seconds on a 11th Generation Intel Core i9 Processor. While our approach constitutes a drastic reduction of problem feature space in comparison with prior art, we show that this does not result in a reduction in performance: the results we report are highly competitive on the benchmark datasets CUHK Avenue and ShanghaiTech, and significantly exceed on the latest State-of-the-Art results on StreetScene, which has so far proven to be the most challenging VAD dataset.