 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hyperbolic Perspective on Hierarchical Structure in Object-Centric Scene Representations
Mar 14, 2026Slot attention has emerged as a powerful framework for unsupervised object-centric learning, decomposing visual scenes into a small set of compact vector representations called \emph{slots}, each capturing a distinct region or object. However, these slots are learned in Euclidean space, which provides no geometric inductive bias for the hierarchical relationships that naturally structure visual scenes. In this work, we propose a simple post-hoc pipeline to project Euclidean slot embeddings onto the Lorentz hyperboloid of hyperbolic space, without modifying the underlying training pipeline. We construct five-level visual hierarchies directly from slot attention masks and analyse whether hyperbolic geometry reveals latent hierarchical structure that remains invisible in Euclidean space. Integrating our pipeline with SPOT (images), VideoSAUR (video), and SlotContrast (video), We find that hyperbolic projection exposes a consistent scene-level to object-level organisation, where coarse slots occupy greater manifold depth than fine slots, which is absent in Euclidean space. We further identify a "curvature--task tradeoff": low curvature ($c{=}0.2$) matches or outperforms Euclidean on parent slot retrieval, while moderate curvature ($c{=}0.5$) achieves better inter-level separation. Together, these findings suggest that slot representations already encode latent hierarchy that hyperbolic geometry reveals, motivating end-to-end hyperbolic training as a natural next step. Code and models are available at \href{https://github.com/NeeluMadan/HHS}{github.com/NeeluMadan/HHS}.
Towards a Multi-Agent Vision-Language System for Zero-Shot Novel Hazardous Object Detection for Autonomous Driving Safety
Apr 18, 2025Detecting anomalous hazards in visual data, particularly in video streams, is a critical challenge in autonomous driving. Existing models often struggle with unpredictable, out-of-label hazards due to their reliance on predefined object categories. In this paper, we propose a multimodal approach that integrates vision-language reasoning with zero-shot object detection to improve hazard identification and explanation. Our pipeline consists of a Vision-Language Model (VLM), a Large Language Model (LLM), in order to detect hazardous objects within a traffic scene. We refine object detection by incorporating OpenAI's CLIP model to match predicted hazards with bounding box annotations, improving localization accuracy. To assess model performance, we create a ground truth dataset by denoising and extending the foundational COOOL (Challenge-of-Out-of-Label) anomaly detection benchmark dataset with complete natural language descriptions for hazard annotations. We define a means of hazard detection and labeling evaluation on the extended dataset using cosine similarity. This evaluation considers the semantic similarity between the predicted hazard description and the annotated ground truth for each video. Additionally, we release a set of tools for structuring and managing large-scale hazard detection datasets. Our findings highlight the strengths and limitations of current vision-language-based approaches, offering insights into future improvements in autonomous hazard detection systems. Our models, scripts, and data can be found at https://github.com/mi3labucm/COOOLER.git
Can Vision-Language Models Understand and Interpret Dynamic Gestures from Pedestrians? Pilot Datasets and Exploration Towards Instructive Nonverbal Commands for Cooperative Autonomous Vehicles
Apr 15, 2025



In autonomous driving, it is crucial to correctly interpret traffic gestures (TGs), such as those of an authority figure providing orders or instructions, or a pedestrian signaling the driver, to ensure a safe and pleasant traffic environment for all road users. This study investigates the capabilities of state-of-the-art vision-language models (VLMs) in zero-shot interpretation, focusing on their ability to caption and classify human gestures in traffic contexts. We create and publicly share two custom datasets with varying formal and informal TGs, such as 'Stop', 'Reverse', 'Hail', etc. The datasets are "Acted TG (ATG)" and "Instructive TG In-The-Wild (ITGI)". They are annotated with natural language, describing the pedestrian's body position and gesture. We evaluate models using three methods utilizing expert-generated captions as baseline and control: (1) caption similarity, (2) gesture classification, and (3) pose sequence reconstruction similarity. Results show that current VLMs struggle with gesture understanding: sentence similarity averages below 0.59, and classification F1 scores reach only 0.14-0.39, well below the expert baseline of 0.70. While pose reconstruction shows potential, it requires more data and refined metrics to be reliable. Our findings reveal that although some SOTA VLMs can interpret zero-shot human traffic gestures, none are accurate and robust enough to be trustworthy, emphasizing the need for further research in this domain.
Multi-modal classification of forest biodiversity potential from 2D orthophotos and 3D airborne laser scanning point clouds
Jan 03, 2025
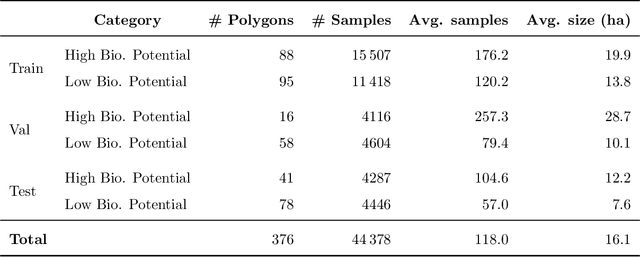
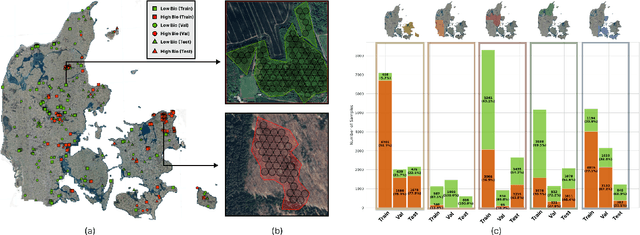
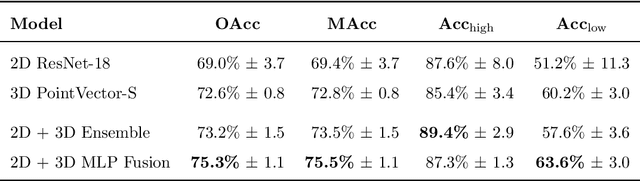
Accurate assessment of forest biodiversity is crucial for ecosystem management and conservation. While traditional field surveys provide high-quality assessments, they are labor-intensive and spatially limited. This study investigates whether deep learning-based fusion of close-range sensing data from 2D orthophotos (12.5 cm resolution) and 3D airborne laser scanning (ALS) point clouds (8 points/m^2) can enhance biodiversity assessment. We introduce the BioVista dataset, comprising 44.378 paired samples of orthophotos and ALS point clouds from temperate forests in Denmark, designed to explore multi-modal fusion approaches for biodiversity potential classification. Using deep neural networks (ResNet for orthophotos and PointVector for ALS point clouds), we investigate each data modality's ability to assess forest biodiversity potential, achieving mean accuracies of 69.4% and 72.8%, respectively. We explore two fusion approaches: a confidence-based ensemble method and a feature-level concatenation strategy, with the latter achieving a mean accuracy of 75.5%. Our results demonstrate that spectral information from orthophotos and structural information from ALS point clouds effectively complement each other in forest biodiversity assessment.
Driver Activity Classification Using Generalizable Representations from Vision-Language Models
Apr 23, 2024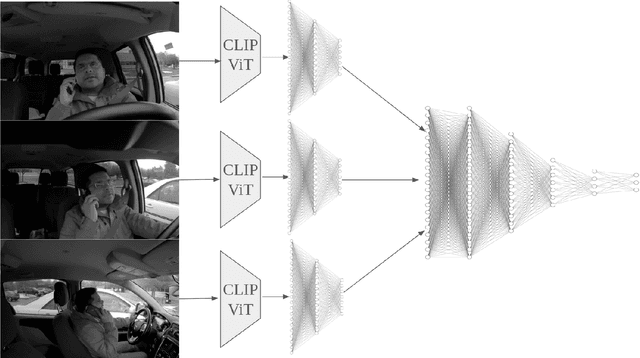
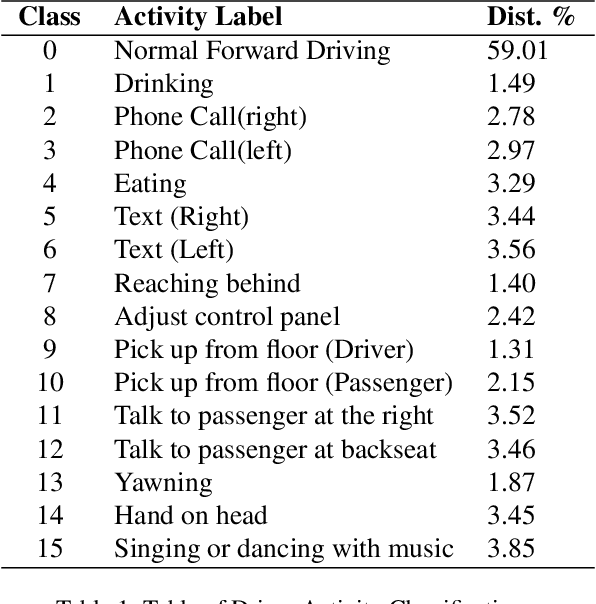

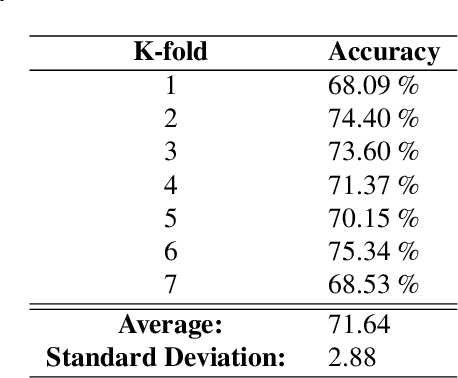
Driver activity classification is crucial for ensuring road safety, with applications ranging from driver assistance systems to autonomous vehicle control transitions. In this paper, we present a novel approach leveraging generalizable representations from vision-language models for driver activity classification. Our method employs a Semantic Representation Late Fusion Neural Network (SRLF-Net) to process synchronized video frames from multiple perspectives. Each frame is encoded using a pretrained vision-language encoder, and the resulting embeddings are fused to generate class probability predictions. By leveraging contrastively-learned vision-language representations, our approach achieves robust performance across diverse driver activities. We evaluate our method on the Naturalistic Driving Action Recognition Dataset, demonstrating strong accuracy across many classes. Our results suggest that vision-language representations offer a promising avenue for driver monitoring systems, providing both accuracy and interpretability through natural language descriptors.
Language-Driven Active Learning for Diverse Open-Set 3D Object Detection
Apr 19, 2024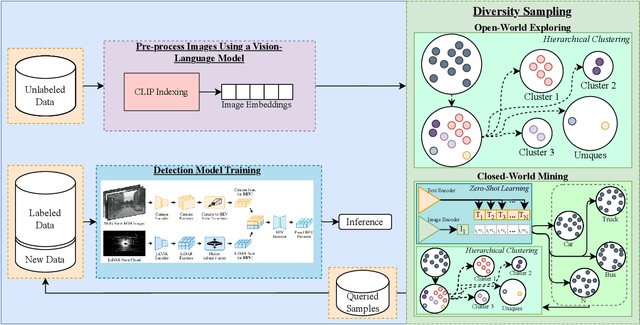
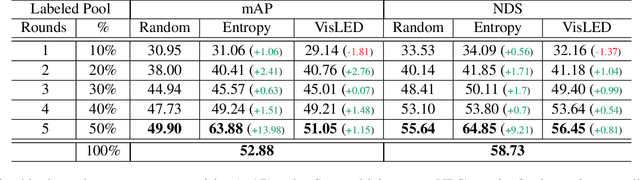
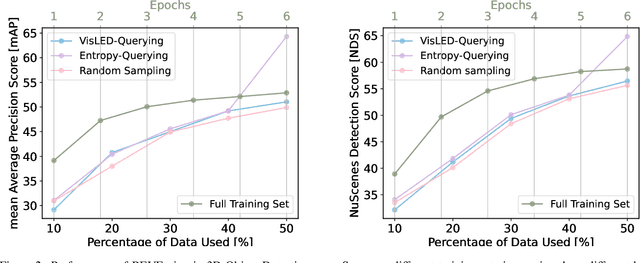
Object detection is crucial for ensuring safe autonomous driving. However, data-driven approaches face challenges when encountering minority or novel objects in the 3D driving scene. In this paper, we propose VisLED, a language-driven active learning framework for diverse open-set 3D Object Detection. Our method leverages active learning techniques to query diverse and informative data samples from an unlabeled pool, enhancing the model's ability to detect underrepresented or novel objects. Specifically, we introduce the Vision-Language Embedding Diversity Querying (VisLED-Querying) algorithm, which operates in both open-world exploring and closed-world mining settings. In open-world exploring, VisLED-Querying selects data points most novel relative to existing data, while in closed-world mining, it mines new instances of known classes. We evaluate our approach on the nuScenes dataset and demonstrate its effectiveness compared to random sampling and entropy-querying methods. Our results show that VisLED-Querying consistently outperforms random sampling and offers competitive performance compared to entropy-querying despite the latter's model-optimality, highlighting the potential of VisLED for improving object detection in autonomous driving scenarios.
OpenTrench3D: A Photogrammetric 3D Point Cloud Dataset for Semantic Segmentation of Underground Utilities
Apr 11, 2024



Identifying and classifying underground utilities is an important task for efficient and effective urban planning and infrastructure maintenance. We present OpenTrench3D, a novel and comprehensive 3D Semantic Segmentation point cloud dataset, designed to advance research and development in underground utility surveying and mapping. OpenTrench3D covers a completely novel domain for public 3D point cloud datasets and is unique in its focus, scope, and cost-effective capturing method. The dataset consists of 310 point clouds collected across 7 distinct areas. These include 5 water utility areas and 2 district heating utility areas. The inclusion of different geographical areas and main utilities (water and district heating utilities) makes OpenTrench3D particularly valuable for inter-domain transfer learning experiments. We provide benchmark results for the dataset using three state-of-the-art semantic segmentation models, PointNeXt, PointVector and PointMetaBase. Benchmarks are conducted by training on data from water areas, fine-tuning on district heating area 1 and evaluating on district heating area 2. The dataset is publicly available. With OpenTrench3D, we seek to foster innovation and progress in the field of 3D semantic segmentation in applications related to detection and documentation of underground utilities as well as in transfer learning methods in general.
Raw Instinct: Trust Your Classifiers and Skip the Conversion
Mar 21, 2024



Using RAW-images in computer vision problems is surprisingly underexplored considering that converting from RAW to RGB does not introduce any new capture information. In this paper, we show that a sufficiently advanced classifier can yield equivalent results on RAW input compared to RGB and present a new public dataset consisting of RAW images and the corresponding converted RGB images. Classifying images directly from RAW is attractive, as it allows for skipping the conversion to RGB, lowering computation time significantly. Two CNN classifiers are used to classify the images in both formats, confirming that classification performance can indeed be preserved. We furthermore show that the total computation time from RAW image data to classification results for RAW images can be up to 8.46 times faster than RGB. These results contribute to the evidence found in related works, that using RAW images as direct input to computer vision algorithms looks very promising.
* https://www.kaggle.com/datasets/mathiasviborg/raw-instinct
Learning to Find Missing Video Frames with Synthetic Data Augmentation: A General Framework and Application in Generating Thermal Images Using RGB Cameras
Feb 29, 2024
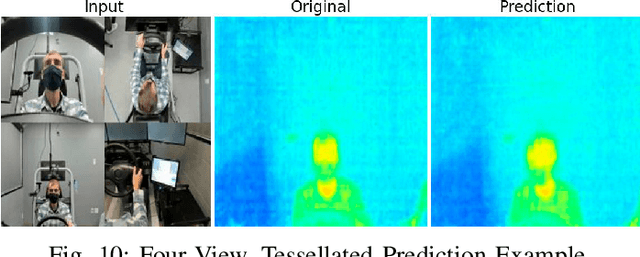
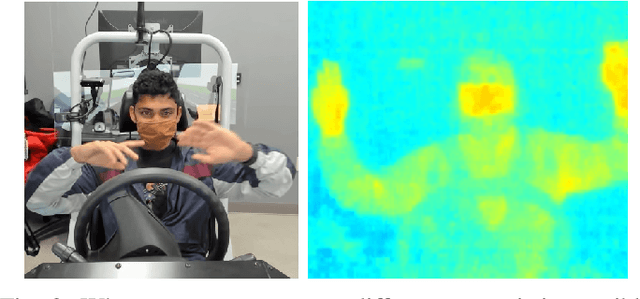
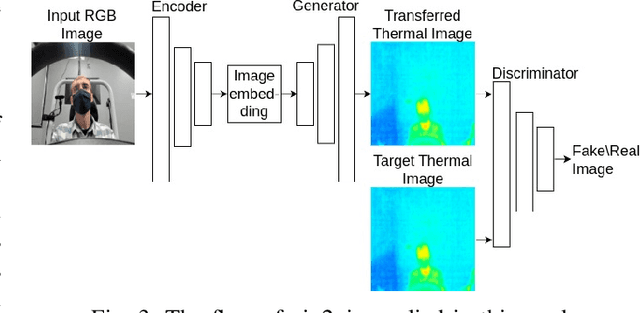
Advanced Driver Assistance Systems (ADAS) in intelligent vehicles rely on accurate driver perception within the vehicle cabin, often leveraging a combination of sensing modalities. However, these modalities operate at varying rates, posing challenges for real-time, comprehensive driver state monitoring. This paper addresses the issue of missing data due to sensor frame rate mismatches, introducing a generative model approach to create synthetic yet realistic thermal imagery. We propose using conditional generative adversarial networks (cGANs), specifically comparing the pix2pix and CycleGAN architectures. Experimental results demonstrate that pix2pix outperforms CycleGAN, and utilizing multi-view input styles, especially stacked views, enhances the accuracy of thermal image generation. Moreover, the study evaluates the model's generalizability across different subjects, revealing the importance of individualized training for optimal performance. The findings suggest the potential of generative models in addressing missing frames, advancing driver state monitoring for intelligent vehicles, and underscoring the need for continued research in model generalization and customization.
ActiveAnno3D -- An Active Learning Framework for Multi-Modal 3D Object Detection
Feb 05, 2024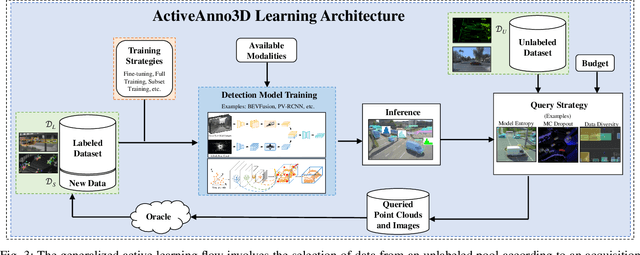
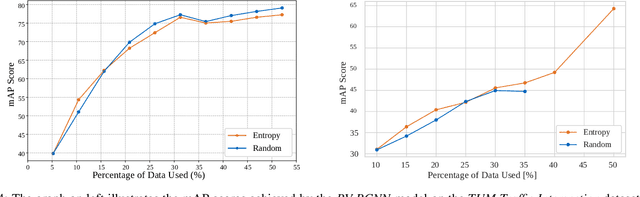
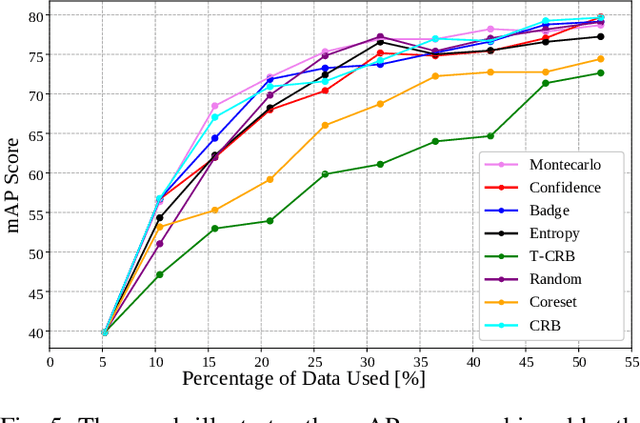

The curation of large-scale datasets is still costly and requires much time and resources. Data is often manually labeled, and the challenge of creating high-quality datasets remains. In this work, we fill the research gap using active learning for multi-modal 3D object detection. We propose ActiveAnno3D, an active learning framework to select data samples for labeling that are of maximum informativeness for training. We explore various continuous training methods and integrate the most efficient method regarding computational demand and detection performance. Furthermore, we perform extensive experiments and ablation studies with BEVFusion and PV-RCNN on the nuScenes and TUM Traffic Intersection dataset. We show that we can achieve almost the same performance with PV-RCNN and the entropy-based query strategy when using only half of the training data (77.25 mAP compared to 83.50 mAP) of the TUM Traffic Intersection dataset. BEVFusion achieved an mAP of 64.31 when using half of the training data and 75.0 mAP when using the complete nuScenes dataset. We integrate our active learning framework into the proAnno labeling tool to enable AI-assisted data selection and labeling and minimize the labeling costs. Finally, we provide code, weights, and visualization results on our website: https://active3d-framework.github.io/active3d-framework.