 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVerifying Machine Unlearning with Explainable AI
Nov 20, 2024
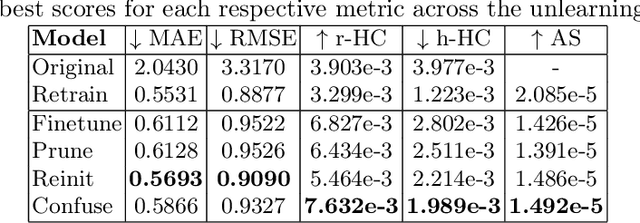
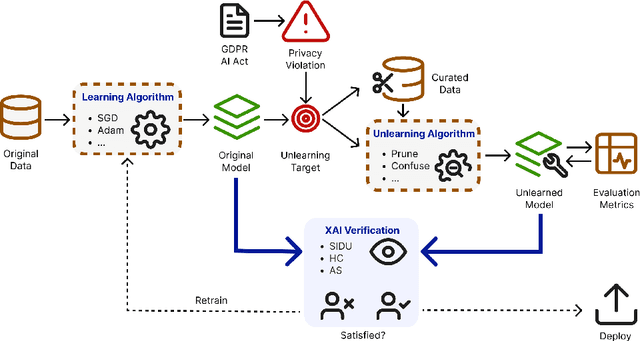

We investigate the effectiveness of Explainable AI (XAI) in verifying Machine Unlearning (MU) within the context of harbor front monitoring, focusing on data privacy and regulatory compliance. With the increasing need to adhere to privacy legislation such as the General Data Protection Regulation (GDPR), traditional methods of retraining ML models for data deletions prove impractical due to their complexity and resource demands. MU offers a solution by enabling models to selectively forget specific learned patterns without full retraining. We explore various removal techniques, including data relabeling, and model perturbation. Then, we leverage attribution-based XAI to discuss the effects of unlearning on model performance. Our proof-of-concept introduces feature importance as an innovative verification step for MU, expanding beyond traditional metrics and demonstrating techniques' ability to reduce reliance on undesired patterns. Additionally, we propose two novel XAI-based metrics, Heatmap Coverage (HC) and Attention Shift (AS), to evaluate the effectiveness of these methods. This approach not only highlights how XAI can complement MU by providing effective verification, but also sets the stage for future research to enhance their joint integration.
Video Transformers: A Survey
Jan 16, 2022
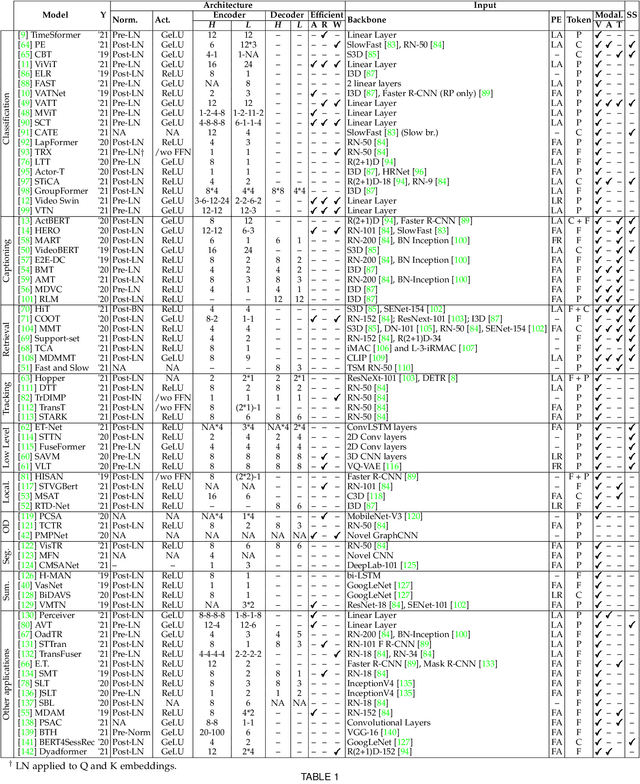
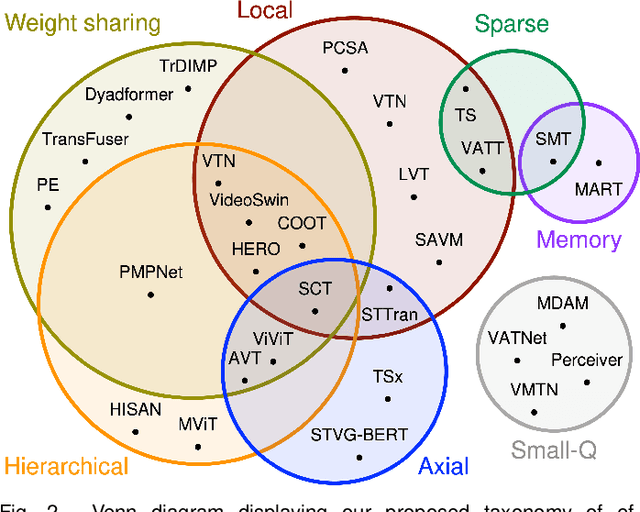
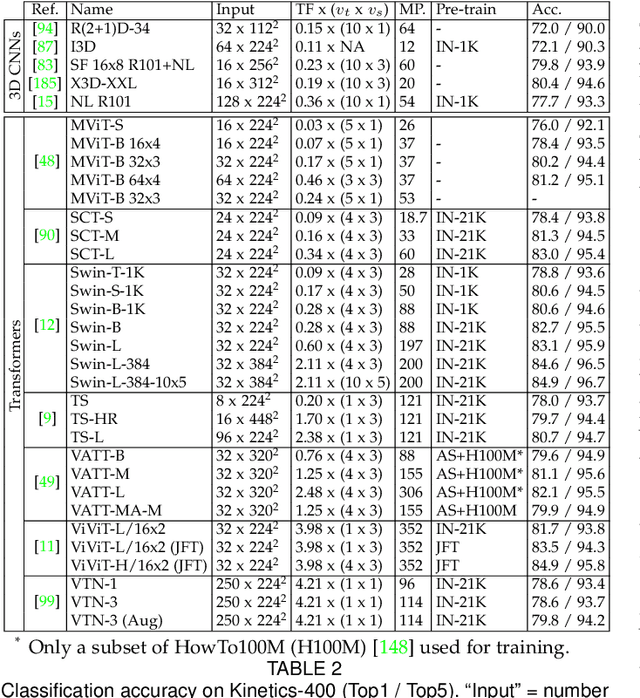
Transformer models have shown great success modeling long-range interactions. Nevertheless, they scale quadratically with input length and lack inductive biases. These limitations can be further exacerbated when dealing with the high dimensionality of video. Proper modeling of video, which can span from seconds to hours, requires handling long-range interactions. This makes Transformers a promising tool for solving video related tasks, but some adaptations are required. While there are previous works that study the advances of Transformers for vision tasks, there is none that focus on in-depth analysis of video-specific designs. In this survey we analyse and summarize the main contributions and trends for adapting Transformers to model video data. Specifically, we delve into how videos are embedded and tokenized, finding a very widspread use of large CNN backbones to reduce dimensionality and a predominance of patches and frames as tokens. Furthermore, we study how the Transformer layer has been tweaked to handle longer sequences, generally by reducing the number of tokens in single attention operation. Also, we analyse the self-supervised losses used to train Video Transformers, which to date are mostly constrained to contrastive approaches. Finally, we explore how other modalities are integrated with video and conduct a performance comparison on the most common benchmark for Video Transformers (i.e., action classification), finding them to outperform 3D CNN counterparts with equivalent FLOPs and no significant parameter increase.