 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoundation Models for Video Understanding: A Survey
May 06, 2024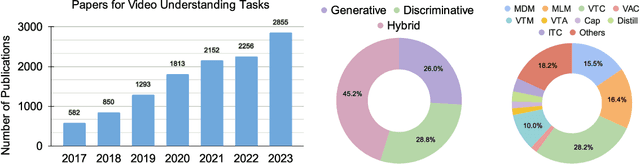
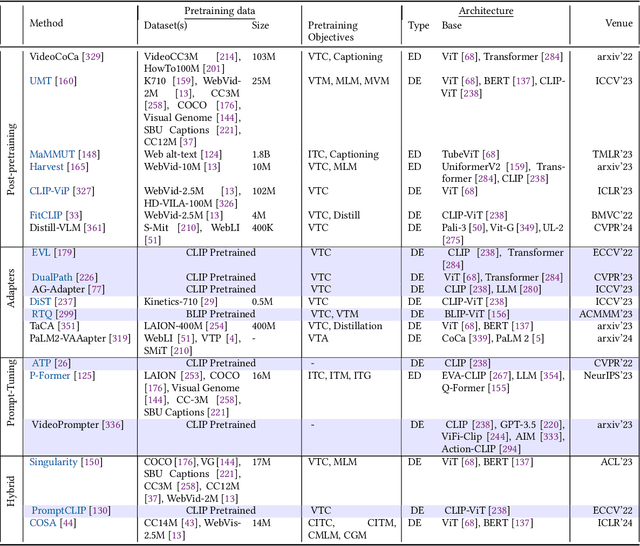
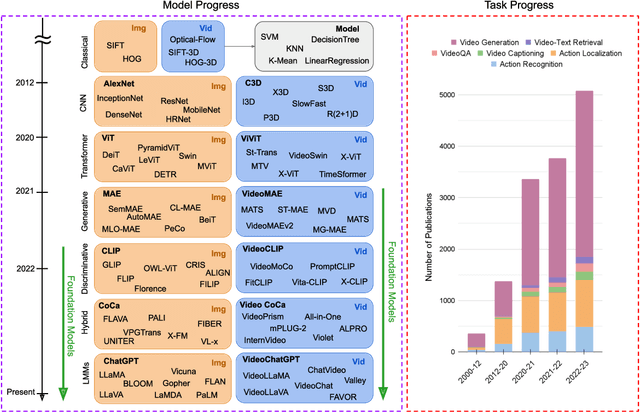
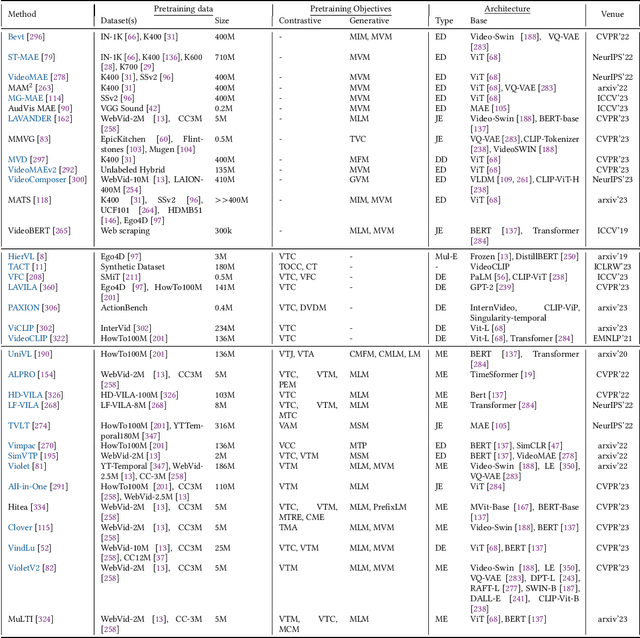
Video Foundation Models (ViFMs) aim to learn a general-purpose representation for various video understanding tasks. Leveraging large-scale datasets and powerful models, ViFMs achieve this by capturing robust and generic features from video data. This survey analyzes over 200 video foundational models, offering a comprehensive overview of benchmarks and evaluation metrics across 14 distinct video tasks categorized into 3 main categories. Additionally, we offer an in-depth performance analysis of these models for the 6 most common video tasks. We categorize ViFMs into three categories: 1) Image-based ViFMs, which adapt existing image models for video tasks, 2) Video-Based ViFMs, which utilize video-specific encoding methods, and 3) Universal Foundational Models (UFMs), which combine multiple modalities (image, video, audio, and text etc.) within a single framework. By comparing the performance of various ViFMs on different tasks, this survey offers valuable insights into their strengths and weaknesses, guiding future advancements in video understanding. Our analysis surprisingly reveals that image-based foundation models consistently outperform video-based models on most video understanding tasks. Additionally, UFMs, which leverage diverse modalities, demonstrate superior performance on video tasks. We share the comprehensive list of ViFMs studied in this work at: \url{https://github.com/NeeluMadan/ViFM_Survey.git}
CL-MAE: Curriculum-Learned Masked Autoencoders
Aug 31, 2023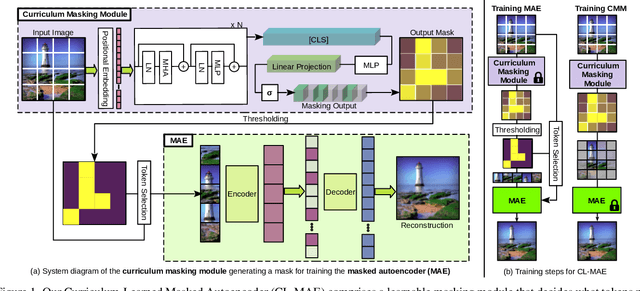
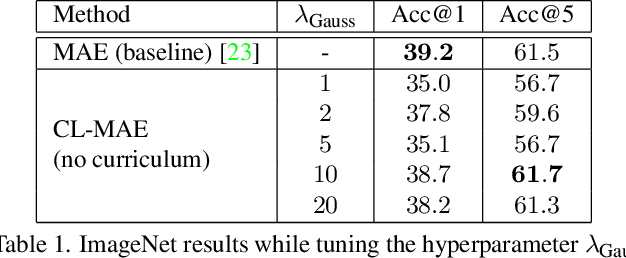
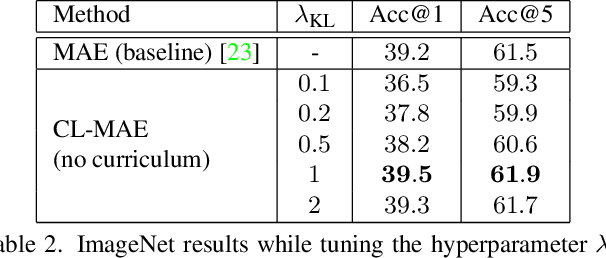

Masked image modeling has been demonstrated as a powerful pretext task for generating robust representations that can be effectively generalized across multiple downstream tasks. Typically, this approach involves randomly masking patches (tokens) in input images, with the masking strategy remaining unchanged during training. In this paper, we propose a curriculum learning approach that updates the masking strategy to continually increase the complexity of the self-supervised reconstruction task. We conjecture that, by gradually increasing the task complexity, the model can learn more sophisticated and transferable representations. To facilitate this, we introduce a novel learnable masking module that possesses the capability to generate masks of different complexities, and integrate the proposed module into masked autoencoders (MAE). Our module is jointly trained with the MAE, while adjusting its behavior during training, transitioning from a partner to the MAE (optimizing the same reconstruction loss) to an adversary (optimizing the opposite loss), while passing through a neutral state. The transition between these behaviors is smooth, being regulated by a factor that is multiplied with the reconstruction loss of the masking module. The resulting training procedure generates an easy-to-hard curriculum. We train our Curriculum-Learned Masked Autoencoder (CL-MAE) on ImageNet and show that it exhibits superior representation learning capabilities compared to MAE. The empirical results on five downstream tasks confirm our conjecture, demonstrating that curriculum learning can be successfully used to self-supervise masked autoencoders.
Self-Supervised Masked Convolutional Transformer Block for Anomaly Detection
Sep 25, 2022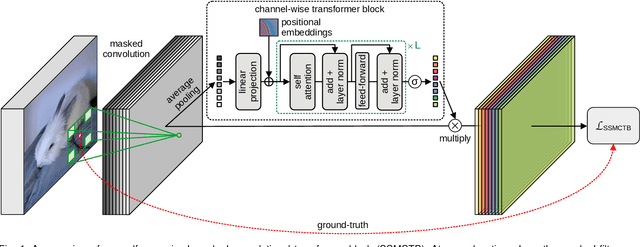

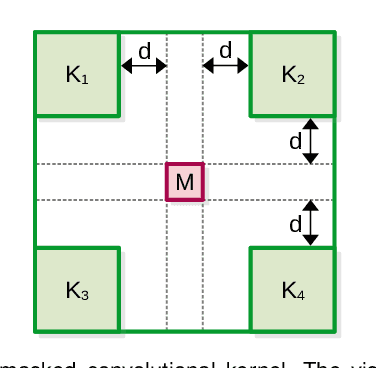
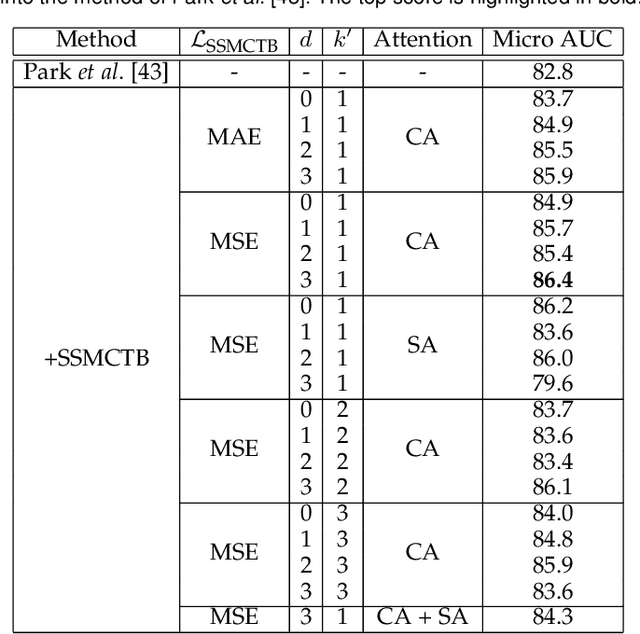
Anomaly detection has recently gained increasing attention in the field of computer vision, likely due to its broad set of applications ranging from product fault detection on industrial production lines and impending event detection in video surveillance to finding lesions in medical scans. Regardless of the domain, anomaly detection is typically framed as a one-class classification task, where the learning is conducted on normal examples only. An entire family of successful anomaly detection methods is based on learning to reconstruct masked normal inputs (e.g. patches, future frames, etc.) and exerting the magnitude of the reconstruction error as an indicator for the abnormality level. Unlike other reconstruction-based methods, we present a novel self-supervised masked convolutional transformer block (SSMCTB) that comprises the reconstruction-based functionality at a core architectural level. The proposed self-supervised block is extremely flexible, enabling information masking at any layer of a neural network and being compatible with a wide range of neural architectures. In this work, we extend our previous self-supervised predictive convolutional attentive block (SSPCAB) with a 3D masked convolutional layer, as well as a transformer for channel-wise attention. Furthermore, we show that our block is applicable to a wider variety of tasks, adding anomaly detection in medical images and thermal videos to the previously considered tasks based on RGB images and surveillance videos. We exhibit the generality and flexibility of SSMCTB by integrating it into multiple state-of-the-art neural models for anomaly detection, bringing forth empirical results that confirm considerable performance improvements on five benchmarks: MVTec AD, BRATS, Avenue, ShanghaiTech, and Thermal Rare Event. We release our code and data as open source at https://github.com/ristea/ssmctb.
Self-Supervised Predictive Convolutional Attentive Block for Anomaly Detection
Nov 19, 2021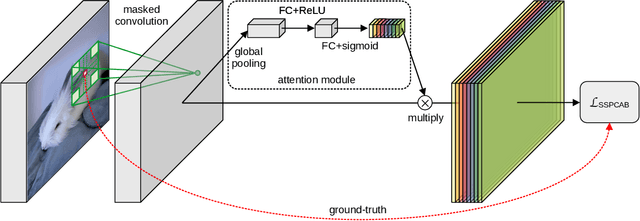
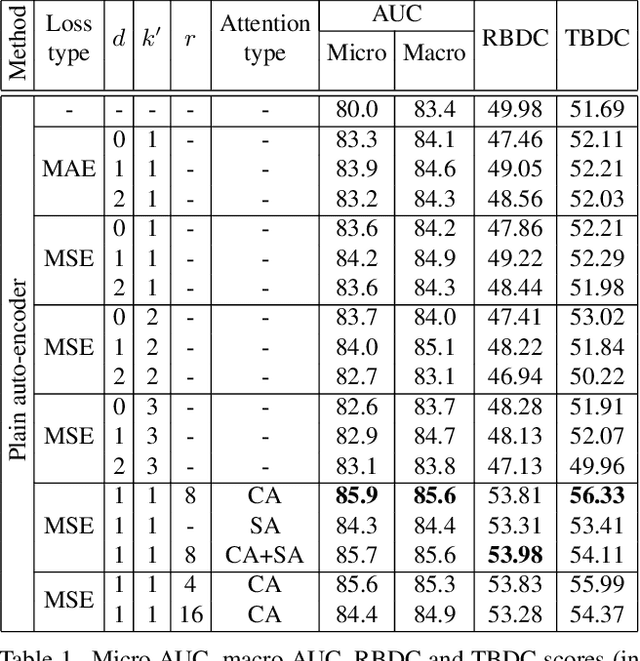
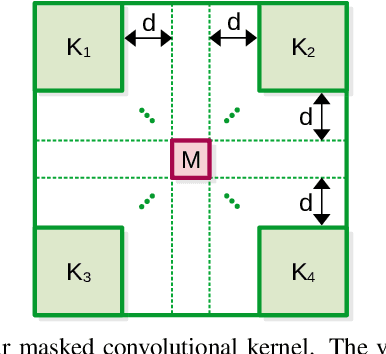
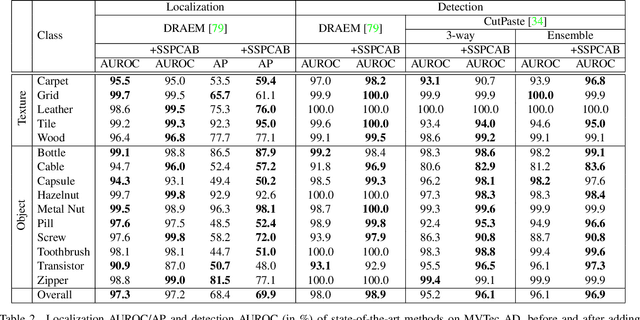
Anomaly detection is commonly pursued as a one-class classification problem, where models can only learn from normal training samples, while being evaluated on both normal and abnormal test samples. Among the successful approaches for anomaly detection, a distinguished category of methods relies on predicting masked information (e.g. patches, future frames, etc.) and leveraging the reconstruction error with respect to the masked information as an abnormality score. Different from related methods, we propose to integrate the reconstruction-based functionality into a novel self-supervised predictive architectural building block. The proposed self-supervised block is generic and can easily be incorporated into various state-of-the-art anomaly detection methods. Our block starts with a convolutional layer with dilated filters, where the center area of the receptive field is masked. The resulting activation maps are passed through a channel attention module. Our block is equipped with a loss that minimizes the reconstruction error with respect to the masked area in the receptive field. We demonstrate the generality of our block by integrating it into several state-of-the-art frameworks for anomaly detection on image and video, providing empirical evidence that shows considerable performance improvements on MVTec AD, Avenue, and ShanghaiTech.