 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSky2Ground: A Benchmark for Site Modeling under Varying Altitude
Mar 14, 2026We introduce Sky2Ground, a three-view dataset designed for varying altitude camera localization, correspondence learning, and reconstruction. The dataset combines structured synthetic imagery with real, in-the-wild images, providing both controlled multi-view geometry and realistic scene noise. Each of the 51 sites contains thousands of satellite, aerial, and ground images spanning wide altitude ranges and nearly orthogonal viewing angles, enabling rigorous evaluation across global-to-local contexts. We benchmark state of the art pose estimation models, including MASt3R, DUSt3R, Map Anything, and VGGT, and observe that the use of satellite imagery often degrades performance, highlighting the challenges under large altitude variations. We also examine reconstruction methods, highlighting the challenges introduced by sparse geometric overlap, varying perspectives, and the use of real imagery, which often introduces noise and reduces rendering quality. To address some of these challenges, we propose SkyNet, a model which enhances cross-view consistency when incorporating satellite imagery with a curriculum-based training strategy to progressively incorporate more satellite views. SkyNet significantly strengthens multi-view alignment and outperforms existing methods by 9.6% on RRA@5 and 18.1% on RTA@5 in terms of absolute performance. Sky2Ground and SkyNet together establish a comprehensive testbed and baseline for advancing large-scale, multi-altitude 3D perception and generalizable camera localization. Code and models will be released publicly for future research.
Asynchronous Perception Machine For Efficient Test-Time-Training
Oct 27, 2024In this work, we propose Asynchronous Perception Machine (APM), a computationally-efficient architecture for test-time-training (TTT). APM can process patches of an image one at a time in any order \textit{asymmetrically,} and \textit{still encode} semantic-awareness in the net. We demonstrate APM's ability to recognize out-of-distribution images \textit{without} dataset-specific pre-training, augmentation or any-pretext task. APM offers competitive performance over existing TTT approaches. To perform TTT, APM just distills test sample's representation \textit{once}. APM possesses a unique property: it can learn using just this single representation and starts predicting semantically-aware features. APM demostrates potential applications beyond test-time-training: APM can scale up to a dataset of 2D images and yield semantic-clusterings in a single forward pass. APM also provides first empirical evidence towards validating GLOM's insight, i.e. input percept is a field. Therefore, APM helps us converge towards an implementation which can do \textit{both} interpolation and perception on a \textit{shared}-connectionist hardware. Our code is publicly available at this link: https://github.com/rajatmodi62/apm.
On Occlusions in Video Action Detection: Benchmark Datasets And Training Recipes
Oct 25, 2024



This paper explores the impact of occlusions in video action detection. We facilitate this study by introducing five new benchmark datasets namely O-UCF and O-JHMDB consisting of synthetically controlled static/dynamic occlusions, OVIS-UCF and OVIS-JHMDB consisting of occlusions with realistic motions and Real-OUCF for occlusions in realistic-world scenarios. We formally confirm an intuitive expectation: existing models suffer a lot as occlusion severity is increased and exhibit different behaviours when occluders are static vs when they are moving. We discover several intriguing phenomenon emerging in neural nets: 1) transformers can naturally outperform CNN models which might have even used occlusion as a form of data augmentation during training 2) incorporating symbolic-components like capsules to such backbones allows them to bind to occluders never even seen during training and 3) Islands of agreement can emerge in realistic images/videos without instance-level supervision, distillation or contrastive-based objectives2(eg. video-textual training). Such emergent properties allow us to derive simple yet effective training recipes which lead to robust occlusion models inductively satisfying the first two stages of the binding mechanism (grouping/segregation). Models leveraging these recipes outperform existing video action-detectors under occlusion by 32.3% on O-UCF, 32.7% on O-JHMDB & 2.6% on Real-OUCF in terms of the vMAP metric. The code for this work has been released at https://github.com/rajatmodi62/OccludedActionBenchmark.
Foundation Models for Video Understanding: A Survey
May 06, 2024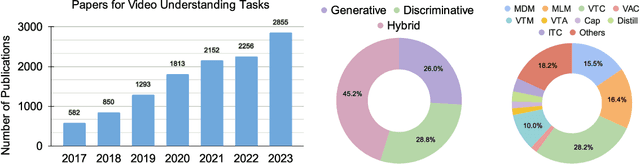
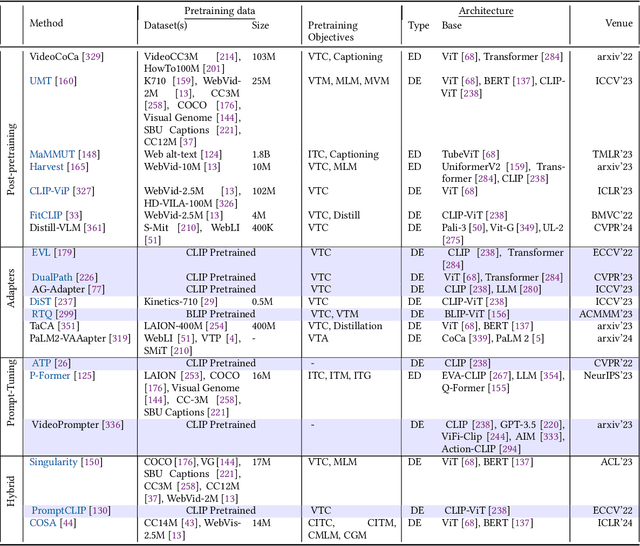
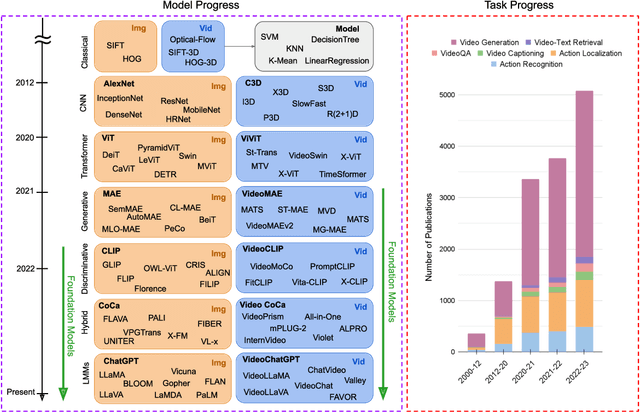
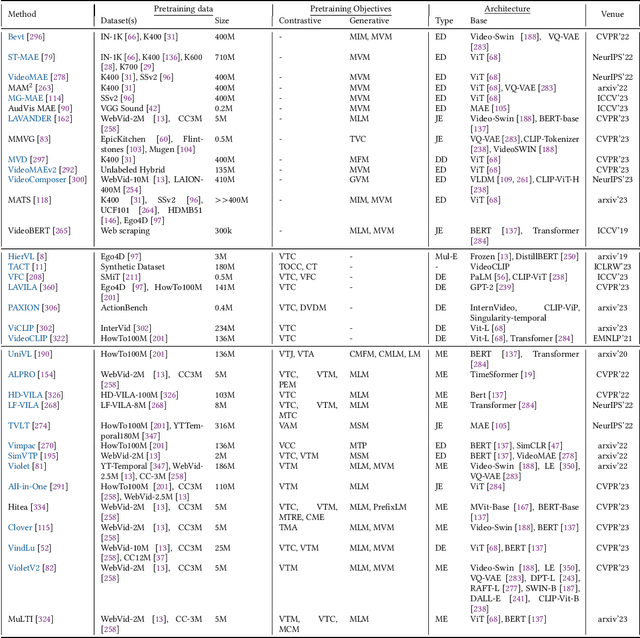
Video Foundation Models (ViFMs) aim to learn a general-purpose representation for various video understanding tasks. Leveraging large-scale datasets and powerful models, ViFMs achieve this by capturing robust and generic features from video data. This survey analyzes over 200 video foundational models, offering a comprehensive overview of benchmarks and evaluation metrics across 14 distinct video tasks categorized into 3 main categories. Additionally, we offer an in-depth performance analysis of these models for the 6 most common video tasks. We categorize ViFMs into three categories: 1) Image-based ViFMs, which adapt existing image models for video tasks, 2) Video-Based ViFMs, which utilize video-specific encoding methods, and 3) Universal Foundational Models (UFMs), which combine multiple modalities (image, video, audio, and text etc.) within a single framework. By comparing the performance of various ViFMs on different tasks, this survey offers valuable insights into their strengths and weaknesses, guiding future advancements in video understanding. Our analysis surprisingly reveals that image-based foundation models consistently outperform video-based models on most video understanding tasks. Additionally, UFMs, which leverage diverse modalities, demonstrate superior performance on video tasks. We share the comprehensive list of ViFMs studied in this work at: \url{https://github.com/NeeluMadan/ViFM_Survey.git}
Video Action Detection: Analysing Limitations and Challenges
Apr 17, 2022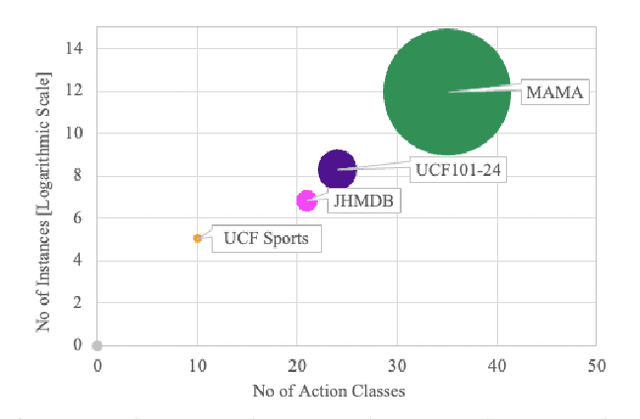
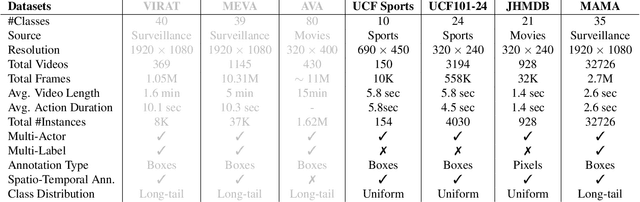

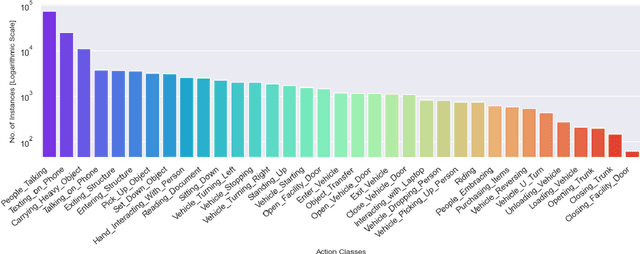
Beyond possessing large enough size to feed data hungry machines (eg, transformers), what attributes measure the quality of a dataset? Assuming that the definitions of such attributes do exist, how do we quantify among their relative existences? Our work attempts to explore these questions for video action detection. The task aims to spatio-temporally localize an actor and assign a relevant action class. We first analyze the existing datasets on video action detection and discuss their limitations. Next, we propose a new dataset, Multi Actor Multi Action (MAMA) which overcomes these limitations and is more suitable for real world applications. In addition, we perform a biasness study which analyzes a key property differentiating videos from static images: the temporal aspect. This reveals if the actions in these datasets really need the motion information of an actor, or whether they predict the occurrence of an action even by looking at a single frame. Finally, we investigate the widely held assumptions on the importance of temporal ordering: is temporal ordering important for detecting these actions? Such extreme experiments show existence of biases which have managed to creep into existing methods inspite of careful modeling.