 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Action Detection: Analysing Limitations and Challenges
Paper and Code
Apr 17, 2022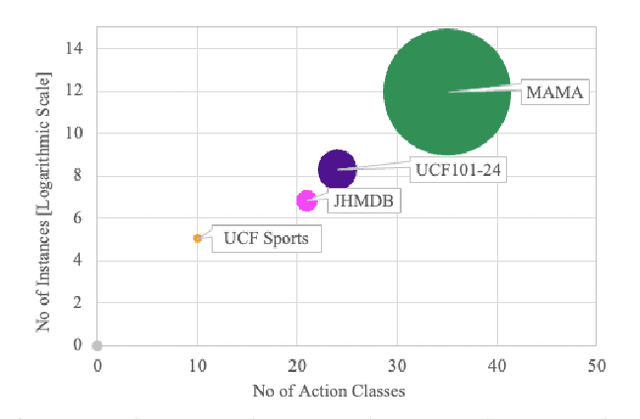
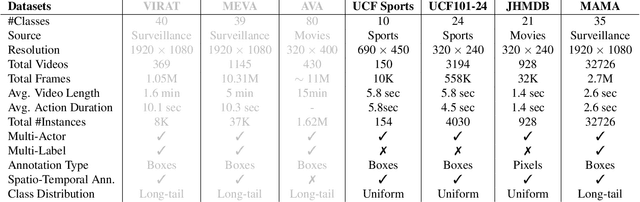

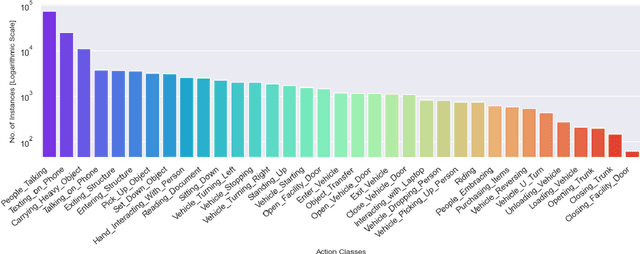
Beyond possessing large enough size to feed data hungry machines (eg, transformers), what attributes measure the quality of a dataset? Assuming that the definitions of such attributes do exist, how do we quantify among their relative existences? Our work attempts to explore these questions for video action detection. The task aims to spatio-temporally localize an actor and assign a relevant action class. We first analyze the existing datasets on video action detection and discuss their limitations. Next, we propose a new dataset, Multi Actor Multi Action (MAMA) which overcomes these limitations and is more suitable for real world applications. In addition, we perform a biasness study which analyzes a key property differentiating videos from static images: the temporal aspect. This reveals if the actions in these datasets really need the motion information of an actor, or whether they predict the occurrence of an action even by looking at a single frame. Finally, we investigate the widely held assumptions on the importance of temporal ordering: is temporal ordering important for detecting these actions? Such extreme experiments show existence of biases which have managed to creep into existing methods inspite of careful modeling.