 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLaDe: Unified Multi-Layered Graphic Media Generation and Decomposition
Mar 18, 2026Media design layer generation enables the creation of fully editable, layered design documents such as posters, flyers, and logos using only natural language prompts. Existing methods either restrict outputs to a fixed number of layers or require each layer to contain only spatially continuous regions, causing the layer count to scale linearly with design complexity. We propose LaDe (Layered Media Design), a latent diffusion framework that generates a flexible number of semantically meaningful layers. LaDe combines three components: an LLM-based prompt expander that transforms a short user intent into structured per-layer descriptions that guide the generation, a Latent Diffusion Transformer with a 4D RoPE positional encoding mechanism that jointly generates the full media design and its constituent RGBA layers, and an RGBA VAE that decodes each layer with full alpha-channel support. By conditioning on layer samples during training, our unified framework supports three tasks: text-to-image generation, text-to-layers media design generation, and media design decomposition. We compare LaDe to Qwen-Image-Layered on text-to-layers and image-to-layers tasks on the Crello test set. LaDe outperforms Qwen-Image-Layered in text-to-layers generation by improving text-to-layer alignment, as validated by two VLM-as-a-judge evaluators (GPT-4o mini and Qwen3-VL).
X-Aligner: Composed Visual Retrieval without the Bells and Whistles
Jan 23, 2026Composed Video Retrieval (CoVR) facilitates video retrieval by combining visual and textual queries. However, existing CoVR frameworks typically fuse multimodal inputs in a single stage, achieving only marginal gains over initial baseline. To address this, we propose a novel CoVR framework that leverages the representational power of Vision Language Models (VLMs). Our framework incorporates a novel cross-attention module X-Aligner, composed of cross-attention layers that progressively fuse visual and textual inputs and align their multimodal representation with that of the target video. To further enhance the representation of the multimodal query, we incorporate the caption of the visual query as an additional input. The framework is trained in two stages to preserve the pretrained VLM representation. In the first stage, only the newly introduced module is trained, while in the second stage, the textual query encoder is also fine-tuned. We implement our framework on top of BLIP-family architecture, namely BLIP and BLIP-2, and train it on the Webvid-CoVR data set. In addition to in-domain evaluation on Webvid-CoVR-Test, we perform zero-shot evaluations on the Composed Image Retrieval (CIR) data sets CIRCO and Fashion-IQ. Our framework achieves state-of-the-art performance on CoVR obtaining a Recall@1 of 63.93% on Webvid-CoVR-Test, and demonstrates strong zero-shot generalization on CIR tasks.
Road Obstacle Video Segmentation
Sep 16, 2025With the growing deployment of autonomous driving agents, the detection and segmentation of road obstacles have become critical to ensure safe autonomous navigation. However, existing road-obstacle segmentation methods are applied on individual frames, overlooking the temporal nature of the problem, leading to inconsistent prediction maps between consecutive frames. In this work, we demonstrate that the road-obstacle segmentation task is inherently temporal, since the segmentation maps for consecutive frames are strongly correlated. To address this, we curate and adapt four evaluation benchmarks for road-obstacle video segmentation and evaluate 11 state-of-the-art image- and video-based segmentation methods on these benchmarks. Moreover, we introduce two strong baseline methods based on vision foundation models. Our approach establishes a new state-of-the-art in road-obstacle video segmentation for long-range video sequences, providing valuable insights and direction for future research.
FLAIR: VLM with Fine-grained Language-informed Image Representations
Dec 04, 2024
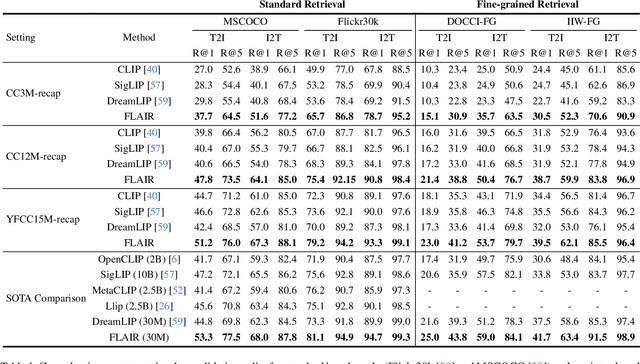
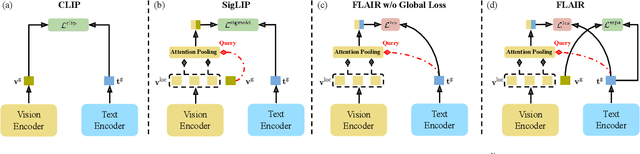
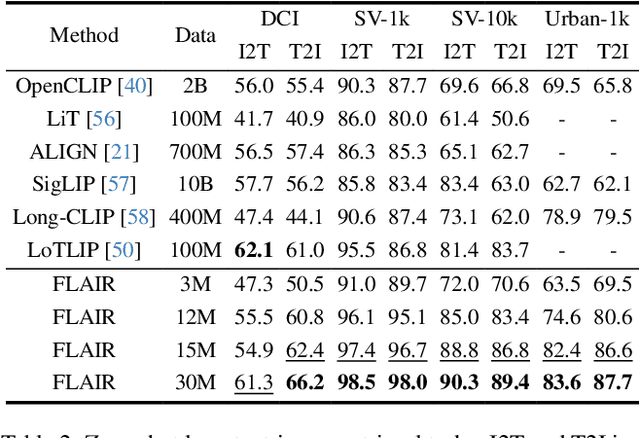
CLIP has shown impressive results in aligning images and texts at scale. However, its ability to capture detailed visual features remains limited because CLIP matches images and texts at a global level. To address this issue, we propose FLAIR, Fine-grained Language-informed Image Representations, an approach that utilizes long and detailed image descriptions to learn localized image embeddings. By sampling diverse sub-captions that describe fine-grained details about an image, we train our vision-language model to produce not only global embeddings but also text-specific image representations. Our model introduces text-conditioned attention pooling on top of local image tokens to produce fine-grained image representations that excel at retrieving detailed image content. We achieve state-of-the-art performance on both, existing multimodal retrieval benchmarks, as well as, our newly introduced fine-grained retrieval task which evaluates vision-language models' ability to retrieve partial image content. Furthermore, our experiments demonstrate the effectiveness of FLAIR trained on 30M image-text pairs in capturing fine-grained visual information, including zero-shot semantic segmentation, outperforming models trained on billions of pairs. Code is available at https://github.com/ExplainableML/flair .
COSMOS: Cross-Modality Self-Distillation for Vision Language Pre-training
Dec 02, 2024
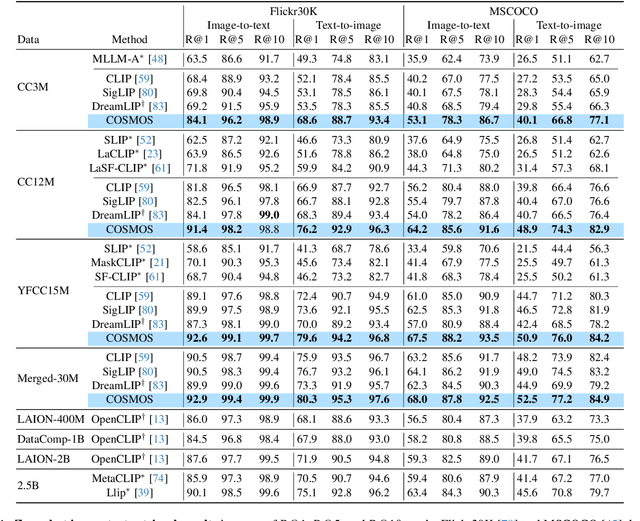
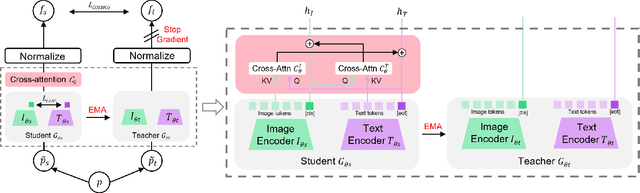
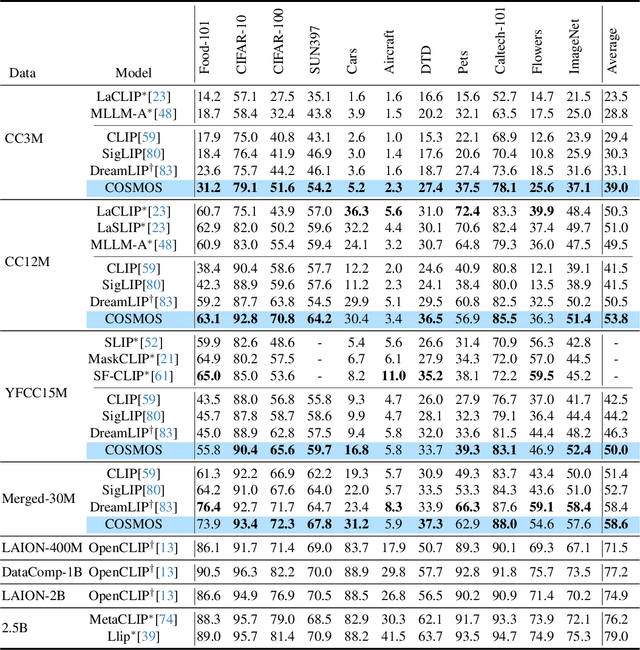
Vision-Language Models (VLMs) trained with contrastive loss have achieved significant advancements in various vision and language tasks. However, the global nature of contrastive loss makes VLMs focus predominantly on foreground objects, neglecting other crucial information in the image, which limits their effectiveness in downstream tasks. To address these challenges, we propose COSMOS: CrOSs-MOdality Self-distillation for vision-language pre-training that integrates a novel text-cropping strategy and cross-attention module into a self-supervised learning framework. We create global and local views of images and texts (i.e., multi-modal augmentations), which are essential for self-distillation in VLMs. We further introduce a cross-attention module, enabling COSMOS to learn comprehensive cross-modal representations optimized via a cross-modality self-distillation loss. COSMOS consistently outperforms previous strong baselines on various zero-shot downstream tasks, including retrieval, classification, and semantic segmentation. Additionally, it surpasses CLIP-based models trained on larger datasets in visual perception and contextual understanding tasks.
EgoCVR: An Egocentric Benchmark for Fine-Grained Composed Video Retrieval
Jul 23, 2024In Composed Video Retrieval, a video and a textual description which modifies the video content are provided as inputs to the model. The aim is to retrieve the relevant video with the modified content from a database of videos. In this challenging task, the first step is to acquire large-scale training datasets and collect high-quality benchmarks for evaluation. In this work, we introduce EgoCVR, a new evaluation benchmark for fine-grained Composed Video Retrieval using large-scale egocentric video datasets. EgoCVR consists of 2,295 queries that specifically focus on high-quality temporal video understanding. We find that existing Composed Video Retrieval frameworks do not achieve the necessary high-quality temporal video understanding for this task. To address this shortcoming, we adapt a simple training-free method, propose a generic re-ranking framework for Composed Video Retrieval, and demonstrate that this achieves strong results on EgoCVR. Our code and benchmark are freely available at https://github.com/ExplainableML/EgoCVR.
Weight Copy and Low-Rank Adaptation for Few-Shot Distillation of Vision Transformers
Apr 17, 2024
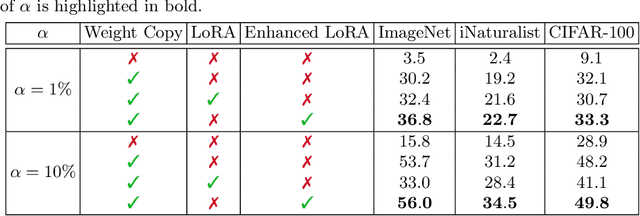


Few-shot knowledge distillation recently emerged as a viable approach to harness the knowledge of large-scale pre-trained models, using limited data and computational resources. In this paper, we propose a novel few-shot feature distillation approach for vision transformers. Our approach is based on two key steps. Leveraging the fact that vision transformers have a consistent depth-wise structure, we first copy the weights from intermittent layers of existing pre-trained vision transformers (teachers) into shallower architectures (students), where the intermittence factor controls the complexity of the student transformer with respect to its teacher. Next, we employ an enhanced version of Low-Rank Adaptation (LoRA) to distill knowledge into the student in a few-shot scenario, aiming to recover the information processing carried out by the skipped teacher layers. We present comprehensive experiments with supervised and self-supervised transformers as teachers, on five data sets from various domains, including natural, medical and satellite images. The empirical results confirm the superiority of our approach over competitive baselines. Moreover, the ablation results demonstrate the usefulness of each component of the proposed pipeline.
Sea-Land-Cloud Segmentation in Satellite Hyperspectral Imagery by Deep Learning
Oct 24, 2023



Satellites are increasingly adopting on-board Artificial Intelligence (AI) techniques to enhance platforms' autonomy through edge inference. In this context, the utilization of deep learning (DL) techniques for segmentation in HS satellite imagery offers advantages for remote sensing applications, and therefore, we train 16 different models, whose codes are made available through our study, which we consider to be relevant for on-board multi-class segmentation of HS imagery, focusing on classifying oceanic (sea), terrestrial (land), and cloud formations. We employ the HYPSO-1 mission as an illustrative case for sea-land-cloud segmentation, and to demonstrate the utility of the segments, we introduce a novel sea-land-cloud ranking application scenario. Our system prioritizes HS image downlink based on sea, land, and cloud coverage levels from the segmented images. We comparatively evaluate the models for in-orbit deployment, considering performance, parameter count, and inference time. The models include both shallow and deep models, and after we propose four new DL models, we demonstrate that segmenting single spectral signatures (1D) outperforms 3D data processing comprising both spectral (1D) and spatial (2D) contexts. We conclude that our lightweight DL model, called 1D-Justo-LiuNet, consistently surpasses state-of-the-art models for sea-land-cloud segmentation, such as U-Net and its variations, in terms of performance (0.93 accuracy) and parameter count (4,563). However, the 1D models present longer inference time (15s) in the tested processing architecture, which is clearly suboptimal. Finally, after demonstrating that in-orbit image segmentation should occur post L1b radiance calibration rather than on raw data, we additionally show that reducing spectral channels down to 3 lowers models' parameters and inference time, at the cost of weaker segmentation performance.
Learning Using Generated Privileged Information by Text-to-Image Diffusion Models
Sep 26, 2023



Learning Using Privileged Information is a particular type of knowledge distillation where the teacher model benefits from an additional data representation during training, called privileged information, improving the student model, which does not see the extra representation. However, privileged information is rarely available in practice. To this end, we propose a text classification framework that harnesses text-to-image diffusion models to generate artificial privileged information. The generated images and the original text samples are further used to train multimodal teacher models based on state-of-the-art transformer-based architectures. Finally, the knowledge from multimodal teachers is distilled into a text-based (unimodal) student. Hence, by employing a generative model to produce synthetic data as privileged information, we guide the training of the student model. Our framework, called Learning Using Generated Privileged Information (LUGPI), yields noticeable performance gains on four text classification data sets, demonstrating its potential in text classification without any additional cost during inference.
Masked Autoencoders for Unsupervised Anomaly Detection in Medical Images
Jul 14, 2023



Pathological anomalies exhibit diverse appearances in medical imaging, making it difficult to collect and annotate a representative amount of data required to train deep learning models in a supervised setting. Therefore, in this work, we tackle anomaly detection in medical images training our framework using only healthy samples. We propose to use the Masked Autoencoder model to learn the structure of the normal samples, then train an anomaly classifier on top of the difference between the original image and the reconstruction provided by the masked autoencoder. We train the anomaly classifier in a supervised manner using as negative samples the reconstruction of the healthy scans, while as positive samples, we use pseudo-abnormal scans obtained via our novel pseudo-abnormal module. The pseudo-abnormal module alters the reconstruction of the normal samples by changing the intensity of several regions. We conduct experiments on two medical image data sets, namely BRATS2020 and LUNA16 and compare our method with four state-of-the-art anomaly detection frameworks, namely AST, RD4AD, AnoVAEGAN and f-AnoGAN.