 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeight Copy and Low-Rank Adaptation for Few-Shot Distillation of Vision Transformers
Apr 17, 2024
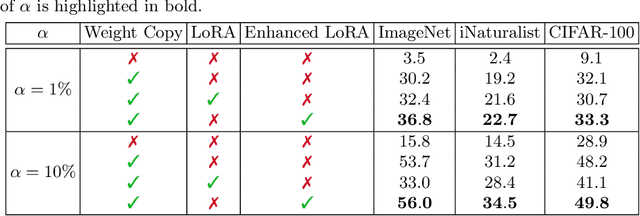


Few-shot knowledge distillation recently emerged as a viable approach to harness the knowledge of large-scale pre-trained models, using limited data and computational resources. In this paper, we propose a novel few-shot feature distillation approach for vision transformers. Our approach is based on two key steps. Leveraging the fact that vision transformers have a consistent depth-wise structure, we first copy the weights from intermittent layers of existing pre-trained vision transformers (teachers) into shallower architectures (students), where the intermittence factor controls the complexity of the student transformer with respect to its teacher. Next, we employ an enhanced version of Low-Rank Adaptation (LoRA) to distill knowledge into the student in a few-shot scenario, aiming to recover the information processing carried out by the skipped teacher layers. We present comprehensive experiments with supervised and self-supervised transformers as teachers, on five data sets from various domains, including natural, medical and satellite images. The empirical results confirm the superiority of our approach over competitive baselines. Moreover, the ablation results demonstrate the usefulness of each component of the proposed pipeline.
Onboard Processing of Hyperspectral Imagery: Deep Learning Advancements, Methodologies, Challenges, and Emerging Trends
Apr 09, 2024Recent advancements in deep learning techniques have spurred considerable interest in their application to hyperspectral imagery processing. This paper provides a comprehensive review of the latest developments in this field, focusing on methodologies, challenges, and emerging trends. Deep learning architectures such as Convolutional Neural Networks (CNNs), Autoencoders, Deep Belief Networks (DBNs), Generative Adversarial Networks (GANs), and Recurrent Neural Networks (RNNs) are examined for their suitability in processing hyperspectral data. Key challenges, including limited training data and computational constraints, are identified, along with strategies such as data augmentation and noise reduction using GANs. The paper discusses the efficacy of different network architectures, highlighting the advantages of lightweight CNN models and 1D CNNs for onboard processing. Moreover, the potential of hardware accelerators, particularly Field Programmable Gate Arrays (FPGAs), for enhancing processing efficiency is explored. The review concludes with insights into ongoing research trends, including the integration of deep learning techniques into Earth observation missions such as the CHIME mission, and emphasizes the need for further exploration and refinement of deep learning methodologies to address the evolving demands of hyperspectral image processing.
Deep Learning for In-Orbit Cloud Segmentation and Classification in Hyperspectral Satellite Data
Mar 13, 2024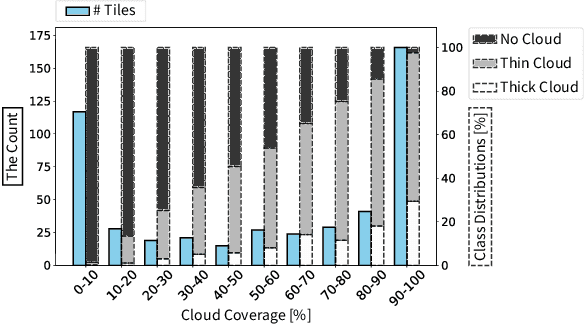
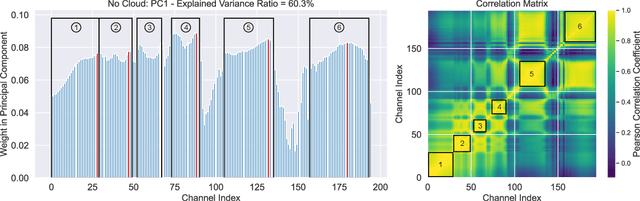
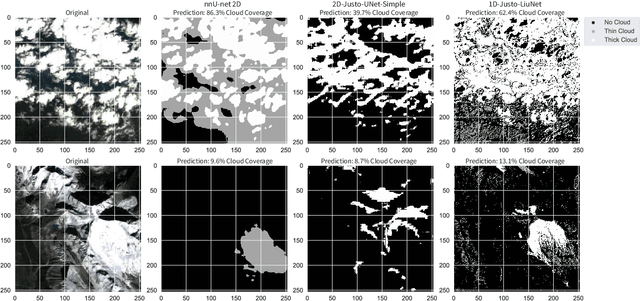
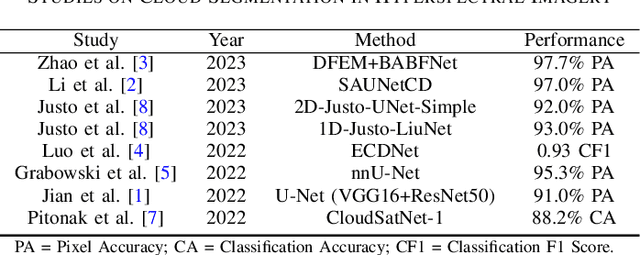
This article explores the latest Convolutional Neural Networks (CNNs) for cloud detection aboard hyperspectral satellites. The performance of the latest 1D CNN (1D-Justo-LiuNet) and two recent 2D CNNs (nnU-net and 2D-Justo-UNet-Simple) for cloud segmentation and classification is assessed. Evaluation criteria include precision and computational efficiency for in-orbit deployment. Experiments utilize NASA's EO-1 Hyperion data, with varying spectral channel numbers after Principal Component Analysis. Results indicate that 1D-Justo-LiuNet achieves the highest accuracy, outperforming 2D CNNs, while maintaining compactness with larger spectral channel sets, albeit with increased inference times. However, the performance of 1D CNN degrades with significant channel reduction. In this context, the 2D-Justo-UNet-Simple offers the best balance for in-orbit deployment, considering precision, memory, and time costs. While nnU-net is suitable for on-ground processing, deployment of lightweight 1D-Justo-LiuNet is recommended for high-precision applications. Alternatively, lightweight 2D-Justo-UNet-Simple is recommended for balanced costs between timing and precision in orbit.
Study of the gOMP Algorithm for Recovery of Compressed Sensed Hyperspectral Images
Jan 26, 2024Hyperspectral Imaging (HSI) is used in a wide range of applications such as remote sensing, yet the transmission of the HS images by communication data links becomes challenging due to the large number of spectral bands that the HS images contain together with the limited data bandwidth available in real applications. Compressive Sensing reduces the images by randomly subsampling the spectral bands of each spatial pixel and then it performs the image reconstruction of all the bands using recovery algorithms which impose sparsity in a certain transform domain. Since the image pixels are not strictly sparse, this work studies a data sparsification pre-processing stage prior to compression to ensure the sparsity of the pixels. The sparsified images are compressed $2.5\times$ and then recovered using the Generalized Orthogonal Matching Pursuit algorithm (gOMP) characterized by high accuracy, low computational requirements and fast convergence. The experiments are performed in five conventional hyperspectral images where the effect of different sparsification levels in the quality of the uncompressed as well as the recovered images is studied. It is concluded that the gOMP algorithm reconstructs the hyperspectral images with higher accuracy as well as faster convergence when the pixels are highly sparsified and hence at the expense of reducing the quality of the recovered images with respect to the original images.
A Comparative Study of Compressive Sensing Algorithms for Hyperspectral Imaging Reconstruction
Jan 26, 2024
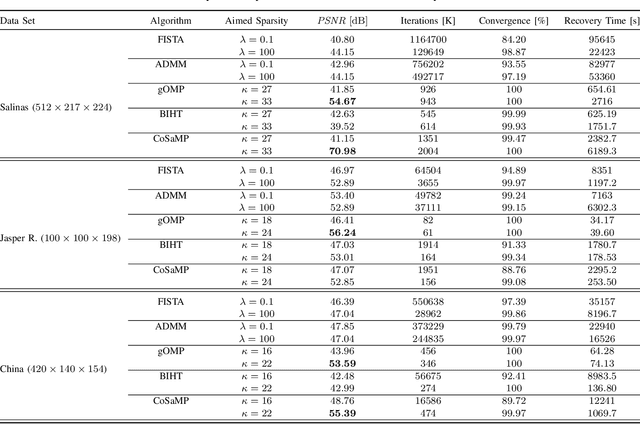
Hyperspectral Imaging comprises excessive data consequently leading to significant challenges for data processing, storage and transmission. Compressive Sensing has been used in the field of Hyperspectral Imaging as a technique to compress the large amount of data. This work addresses the recovery of hyperspectral images 2.5x compressed. A comparative study in terms of the accuracy and the performance of the convex FISTA/ADMM in addition to the greedy gOMP/BIHT/CoSaMP recovery algorithms is presented. The results indicate that the algorithms recover successfully the compressed data, yet the gOMP algorithm achieves superior accuracy and faster recovery in comparison to the other algorithms at the expense of high dependence on unknown sparsity level of the data to recover.
Sea-Land-Cloud Segmentation in Satellite Hyperspectral Imagery by Deep Learning
Oct 24, 2023



Satellites are increasingly adopting on-board Artificial Intelligence (AI) techniques to enhance platforms' autonomy through edge inference. In this context, the utilization of deep learning (DL) techniques for segmentation in HS satellite imagery offers advantages for remote sensing applications, and therefore, we train 16 different models, whose codes are made available through our study, which we consider to be relevant for on-board multi-class segmentation of HS imagery, focusing on classifying oceanic (sea), terrestrial (land), and cloud formations. We employ the HYPSO-1 mission as an illustrative case for sea-land-cloud segmentation, and to demonstrate the utility of the segments, we introduce a novel sea-land-cloud ranking application scenario. Our system prioritizes HS image downlink based on sea, land, and cloud coverage levels from the segmented images. We comparatively evaluate the models for in-orbit deployment, considering performance, parameter count, and inference time. The models include both shallow and deep models, and after we propose four new DL models, we demonstrate that segmenting single spectral signatures (1D) outperforms 3D data processing comprising both spectral (1D) and spatial (2D) contexts. We conclude that our lightweight DL model, called 1D-Justo-LiuNet, consistently surpasses state-of-the-art models for sea-land-cloud segmentation, such as U-Net and its variations, in terms of performance (0.93 accuracy) and parameter count (4,563). However, the 1D models present longer inference time (15s) in the tested processing architecture, which is clearly suboptimal. Finally, after demonstrating that in-orbit image segmentation should occur post L1b radiance calibration rather than on raw data, we additionally show that reducing spectral channels down to 3 lowers models' parameters and inference time, at the cost of weaker segmentation performance.