 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSMTL++: Revisiting Self-Supervised Multi-Task Learning for Video Anomaly Detection
Jul 16, 2022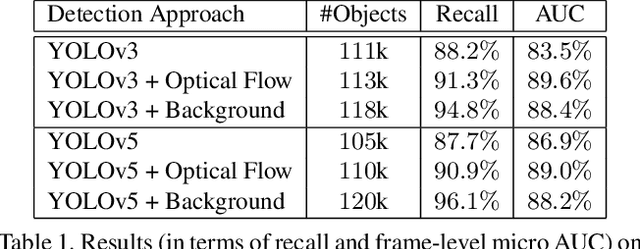
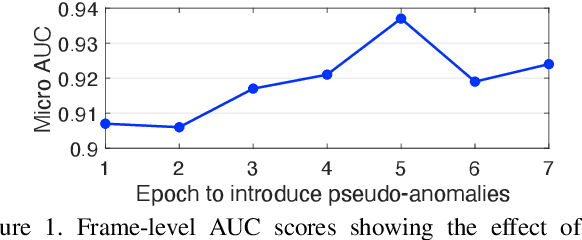
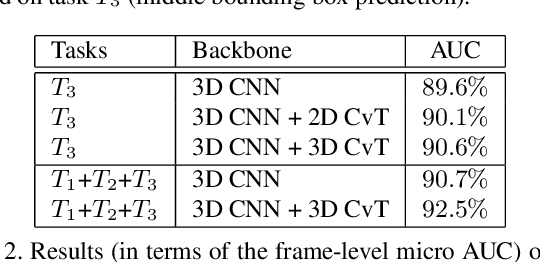
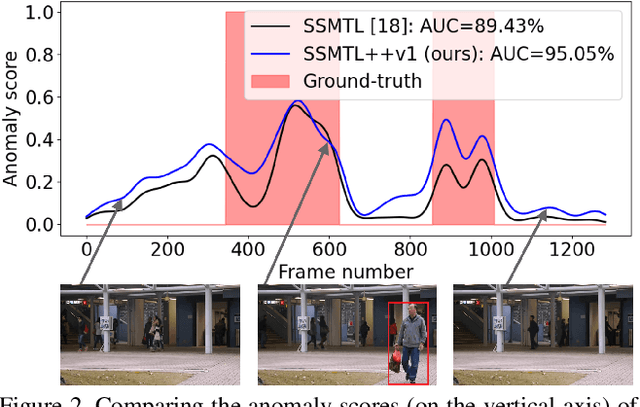
A self-supervised multi-task learning (SSMTL) framework for video anomaly detection was recently introduced in literature. Due to its highly accurate results, the method attracted the attention of many researchers. In this work, we revisit the self-supervised multi-task learning framework, proposing several updates to the original method. First, we study various detection methods, e.g. based on detecting high-motion regions using optical flow or background subtraction, since we believe the currently used pre-trained YOLOv3 is suboptimal, e.g. objects in motion or objects from unknown classes are never detected. Second, we modernize the 3D convolutional backbone by introducing multi-head self-attention modules, inspired by the recent success of vision transformers. As such, we alternatively introduce both 2D and 3D convolutional vision transformer (CvT) blocks. Third, in our attempt to further improve the model, we study additional self-supervised learning tasks, such as predicting segmentation maps through knowledge distillation, solving jigsaw puzzles, estimating body pose through knowledge distillation, predicting masked regions (inpainting), and adversarial learning with pseudo-anomalies. We conduct experiments to assess the performance impact of the introduced changes. Upon finding more promising configurations of the framework, dubbed SSMTL++v1 and SSMTL++v2, we extend our preliminary experiments to more data sets, demonstrating that our performance gains are consistent across all data sets. In most cases, our results on Avenue, ShanghaiTech and UBnormal raise the state-of-the-art performance to a new level.
Consistency Regularization with Generative Adversarial Networks for Semi-Supervised Image Classification
Jul 08, 2020
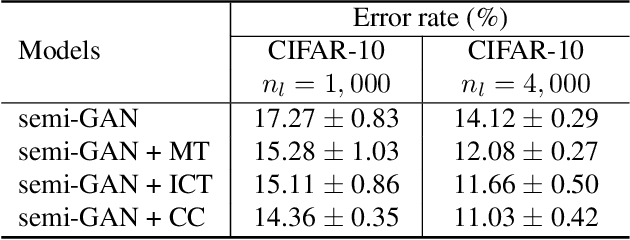
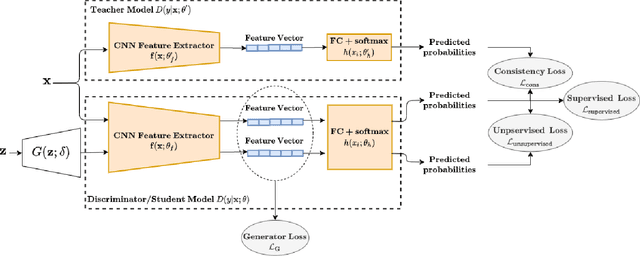

Generative Adversarial Networks (GANs) based semi-supervised learning (SSL) approaches are shown to improve classification performance by utilizing a large number of unlabeled samples in conjunction with limited labeled samples. However, their performance still lags behind the state-of-the-art non-GAN based SSL approaches. One main reason we identify is the lack of consistency in class probability predictions on the same image under local perturbations. This problem was addressed in the past in a generic setting using the label consistency regularization, which enforces the class probability predictions for an input image to be unchanged under various semantic-preserving perturbations. In this work, we incorporate the consistency regularization in the vanilla semi-GAN to address this critical limitation. In particular, we present a new composite consistency regularization method which, in spirit, combines two well-known consistency-based techniques -- Mean Teacher and Interpolation Consistency Training. We demonstrate the efficacy of our approach on two SSL image classification benchmark datasets, SVHN and CIFAR-10. Our experiments show that this new composite consistency regularization based semi-GAN significantly improves its performance and achieves new state-of-the-art performance among GAN-based SSL approaches.
Local Clustering with Mean Teacher for Semi-supervised Learning
Apr 20, 2020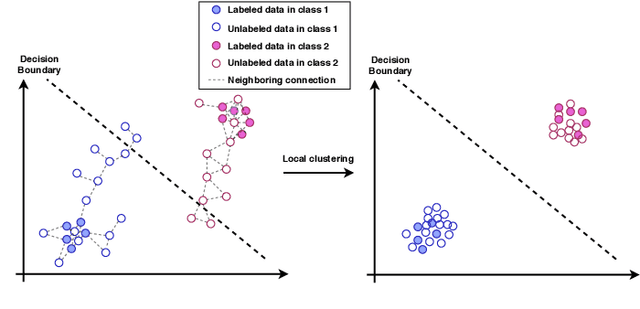
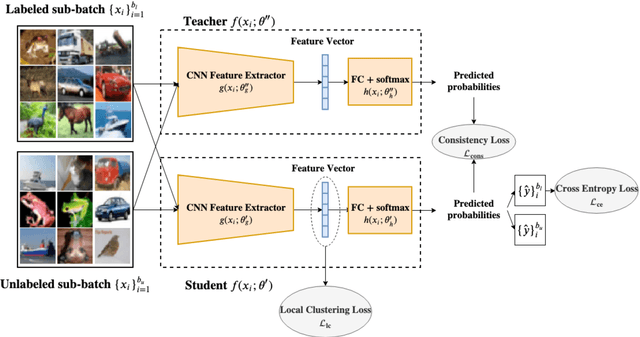
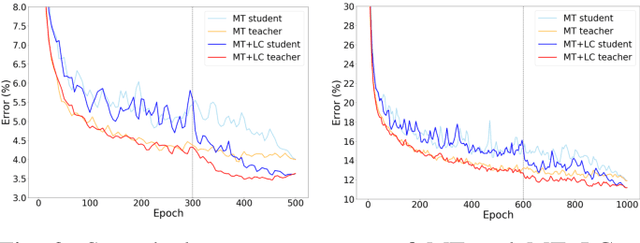

The Mean Teacher (MT) model of Tarvainen and Valpola has shown favorable performance on several semi-supervised benchmark datasets. MT maintains a teacher model's weights as the exponential moving average of a student model's weights and minimizes the divergence between their probability predictions under diverse perturbations of the inputs. However, MT is known to suffer from confirmation bias, that is, reinforcing incorrect teacher model predictions. In this work, we propose a simple yet effective method called Local Clustering (LC) to mitigate the effect of confirmation bias. In MT, each data point is considered independent of other points during training; however, data points are likely to be close to each other in feature space if they share similar features. Motivated by this, we cluster data points locally by minimizing the pairwise distance between neighboring data points in feature space. Combined with a standard classification cross-entropy objective on labeled data points, the misclassified unlabeled data points are pulled towards high-density regions of their correct class with the help of their neighbors, thus improving model performance. We demonstrate on semi-supervised benchmark datasets SVHN and CIFAR-10 that adding our LC loss to MT yields significant improvements compared to MT and performance comparable to the state of the art in semi-supervised learning.
A Survey of Single-Scene Video Anomaly Detection
Apr 13, 2020


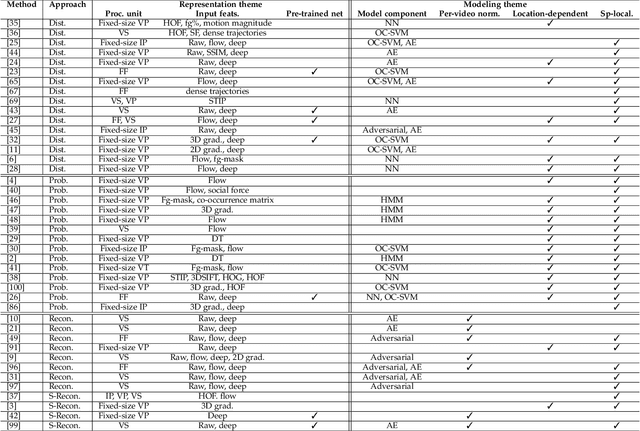
This survey article summarizes research trends on the topic of anomaly detection in video feeds of a single scene. We discuss the various problem formulations, publicly available datasets and evaluation criteria. We categorize and situate past research into an intuitive taxonomy. Finally, we also provide best practices and suggest some possible directions for future research.
Learning a distance function with a Siamese network to localize anomalies in videos
Jan 24, 2020


This work introduces a new approach to localize anomalies in surveillance video. The main novelty is the idea of using a Siamese convolutional neural network (CNN) to learn a distance function between a pair of video patches (spatio-temporal regions of video). The learned distance function, which is not specific to the target video, is used to measure the distance between each video patch in the testing video and the video patches found in normal training video. If a testing video patch is not similar to any normal video patch then it must be anomalous. We compare our approach to previously published algorithms using 4 evaluation measures and 3 challenging target benchmark datasets. Experiments show that our approach either surpasses or performs comparably to current state-of-the-art methods.
Estimating a Manifold from a Tangent Bundle Learner
Jun 18, 2019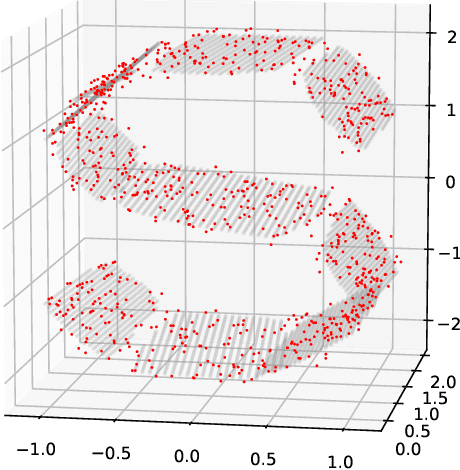
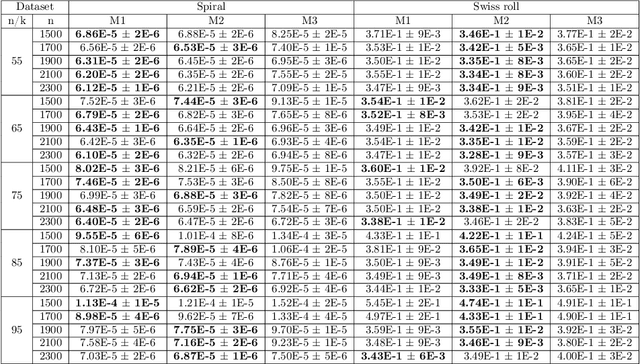
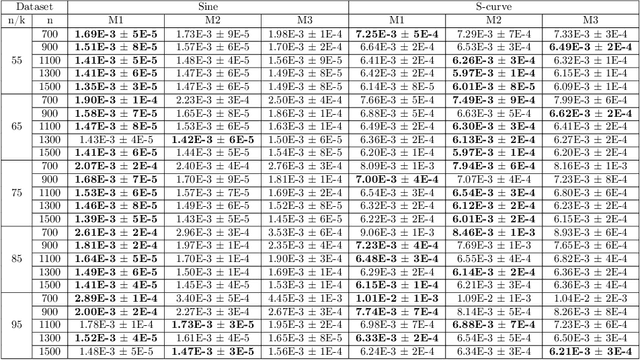
Manifold hypotheses are typically used for tasks such as dimensionality reduction, interpolation, or improving classification performance. In the less common problem of manifold estimation, the task is to characterize the geometric structure of the manifold in the original ambient space from a sample. We focus on the role that tangent bundle learners (TBL) can play in estimating the underlying manifold from which data is assumed to be sampled. Since the unbounded tangent spaces natively represent a poor manifold estimate, the problem reduces to one of estimating regions in the tangent space where it acts as a relatively faithful linear approximator to the surface of the manifold. Local PCA methods, such as the Mixtures of Probabilistic Principal Component Analyzers method of Tipping and Bishop produce a subset of the tangent bundle of the manifold along with an assignment function that assigns points in the training data used by the TBL to elements of the estimated tangent bundle. We formulate three methods that use the data assigned to each tangent space to estimate the underlying bounded subspaces for which the tangent space is a faithful estimate of the manifold and offer thoughts on how this perspective is theoretically grounded in the manifold assumption. We seek to explore the conceptual and technical challenges that arise in trying to utilize simple TBL methods to arrive at reliable estimates of the underlying manifold.
Relational Long Short-Term Memory for Video Action Recognition
Nov 16, 2018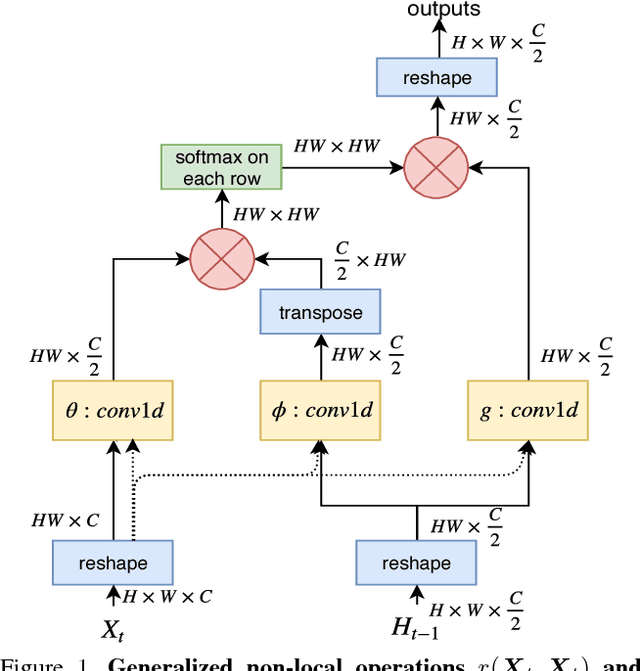
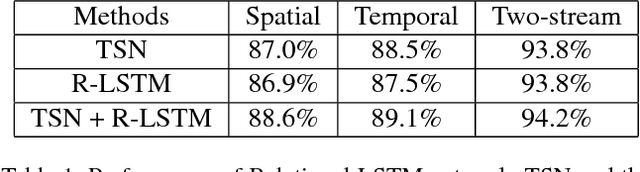
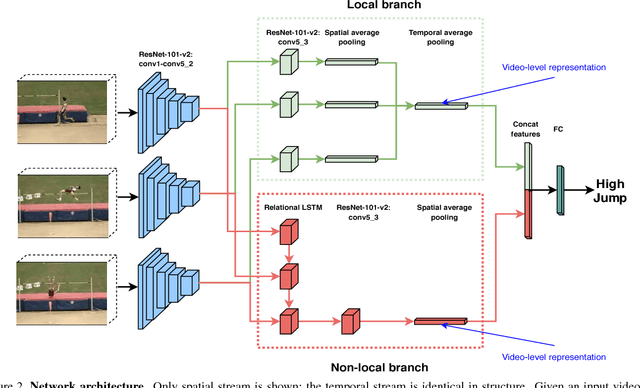
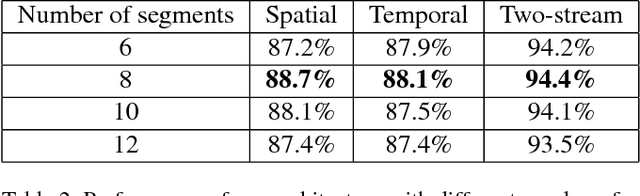
Spatial and temporal relationships, both short-range and long-range, between objects in videos are key cues for recognizing actions. It is a challenging problem to model them jointly. In this paper, we first present a new variant of Long Short-Term Memory, namely Relational LSTM to address the challenge for relation reasoning across space and time between objects. In our Relational LSTM module, we utilize a non-local operation similar in spirit to the recently proposed non-local network to substitute the fully connected operation in the vanilla LSTM. By doing this, our Relational LSTM is capable of capturing long and short-range spatio-temporal relations between objects in videos in a principled way. Then, we propose a two-branch neural architecture consisting of the Relational LSTM module as the non-local branch and a spatio-temporal pooling based local branch. The local branch is introduced for capturing local spatial appearance and/or short-term motion features. The two-branch modules are concatenated to learn video-level features from snippet-level ones end-to-end. Experimental results on UCF-101 and HMDB-51 datasets show that our model achieves state-of-the-art results among LSTM-based methods, while obtaining comparable performance with other state-of-the-art methods (which use not directly comparable schema). Our code will be released.