 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRAG: Generic Response-Augmented Generation Framework for Personalized Conversational Systems
Jun 24, 2026Deploying highly capable personalized conversational agents in resource-constrained or privacy-sensitive environments remains a significant challenge. We identify a fundamental bottleneck in the existing approaches: current training paradigms treat personalization and grounding as a single monolithic learning problem. Under these paradigms, language models are forced to simultaneously address what to say (content grounding) and how to say it in a user-specific way (personalization), which introduces significant computational and optimization challenges. Consequently, contextual grounding is often sacrificed for persona adherence, or vice versa, resulting in responses that are either weakly grounded in the conversational history or insufficiently personalized. In this work, we propose the Generic Response-Augmented Generation (GRAG) framework that decouples these competing objectives by leveraging offline, generic responses from high-capacity, general-purpose LLMs as a semantic and structural scaffold to guide the fine-tuning of smaller, task-specialized models seamlessly in resource-limited environments. By decoupling the content grounding from personalization, GRAG allows the model to focus exclusively on persona injection while remaining firmly anchored to the conversational context. We instantiate the GRAG in two post- and pre-fusion-based architectural variants and evaluate them on multiple benchmark conversational datasets that cover diverse personalization structures. Our results demonstrate that GRAG significantly outperforms state-of-the-art methods that do not use auxiliary scaffolding, yielding up to 47% improvements in ROUGE-2 and 36% in BLEU scores. Ultimately, GRAG offers a generalizable blueprint for building grounding-aware personalized conversational systems in resource-limited environments.
CoMAC: Conversational Agent for Multi-Source Auxiliary Context with Sparse and Symmetric Latent Interactions
Mar 25, 2025Recent advancements in AI-driven conversational agents have exhibited immense potential of AI applications. Effective response generation is crucial to the success of these agents. While extensive research has focused on leveraging multiple auxiliary data sources (e.g., knowledge bases and personas) to enhance response generation, existing methods often struggle to efficiently extract relevant information from these sources. There are still clear limitations in the ability to combine versatile conversational capabilities with adherence to known facts and adaptation to large variations in user preferences and belief systems, which continues to hinder the wide adoption of conversational AI tools. This paper introduces a novel method, Conversational Agent for Multi-Source Auxiliary Context with Sparse and Symmetric Latent Interactions (CoMAC), for conversation generation, which employs specialized encoding streams and post-fusion grounding networks for multiple data sources to identify relevant persona and knowledge information for the conversation. CoMAC also leverages a novel text similarity metric that allows bi-directional information sharing among multiple sources and focuses on a selective subset of meaningful words. Our experiments show that CoMAC improves the relevant persona and knowledge prediction accuracies and response generation quality significantly over two state-of-the-art methods.
Context Retrieval via Normalized Contextual Latent Interaction for Conversational Agent
Dec 01, 2023Conversational agents leveraging AI, particularly deep learning, are emerging in both academic research and real-world applications. However, these applications still face challenges, including disrespecting knowledge and facts, not personalizing to user preferences, and enormous demand for computational resources during training and inference. Recent research efforts have been focused on addressing these challenges from various aspects, including supplementing various types of auxiliary information to the conversational agents. However, existing methods are still not able to effectively and efficiently exploit relevant information from these auxiliary supplements to further unleash the power of the conversational agents and the language models they use. In this paper, we present a novel method, PK-NCLI, that is able to accurately and efficiently identify relevant auxiliary information to improve the quality of conversational responses by learning the relevance among persona, chat history, and knowledge background through low-level normalized contextual latent interaction. Our experimental results indicate that PK-NCLI outperforms the state-of-the-art method, PK-FoCus, by 47.80%/30.61%/24.14% in terms of perplexity, knowledge grounding, and training efficiency, respectively, and maintained the same level of persona grounding performance. We also provide a detailed analysis of how different factors, including language model choices and trade-offs on training weights, would affect the performance of PK-NCLI.
Persona-Coded Poly-Encoder: Persona-Guided Multi-Stream Conversational Sentence Scoring
Sep 28, 2023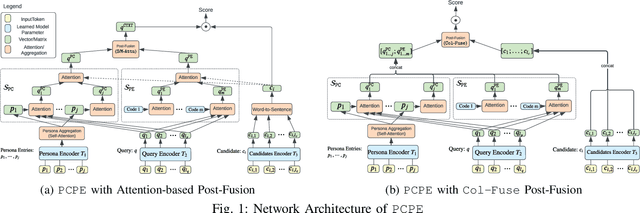
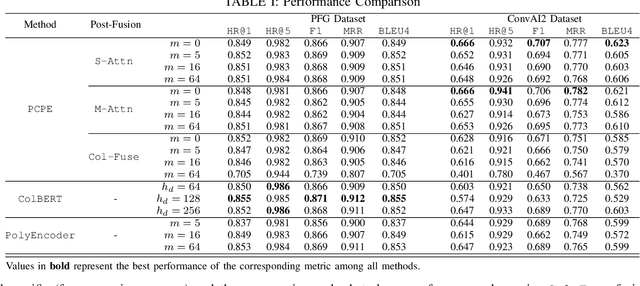
Recent advances in machine learning and deep learning have led to the widespread use of Conversational AI in many practical applications. However, it is still very challenging to leverage auxiliary information that can provide conversational context or personalized tuning to improve the quality of conversations. For example, there has only been limited research on using an individuals persona information to improve conversation quality, and even state-of-the-art conversational AI techniques are unable to effectively leverage signals from heterogeneous sources of auxiliary data, such as multi-modal interaction data, demographics, SDOH data, etc. In this paper, we present a novel Persona-Coded Poly-Encoder method that leverages persona information in a multi-stream encoding scheme to improve the quality of response generation for conversations. To show the efficacy of the proposed method, we evaluate our method on two different persona-based conversational datasets, and compared against two state-of-the-art methods. Our experimental results and analysis demonstrate that our method can improve conversation quality over the baseline method Poly-Encoder by 3.32% and 2.94% in terms of BLEU score and HR@1, respectively. More significantly, our method offers a path to better utilization of multi-modal data in conversational tasks. Lastly, our study outlines several challenges and future research directions for advancing personalized conversational AI technology.
Persona-Based Conversational AI: State of the Art and Challenges
Dec 04, 2022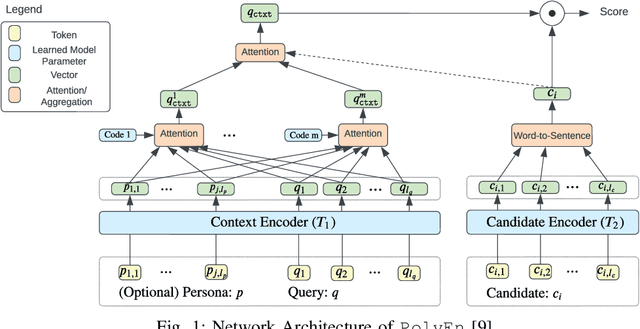
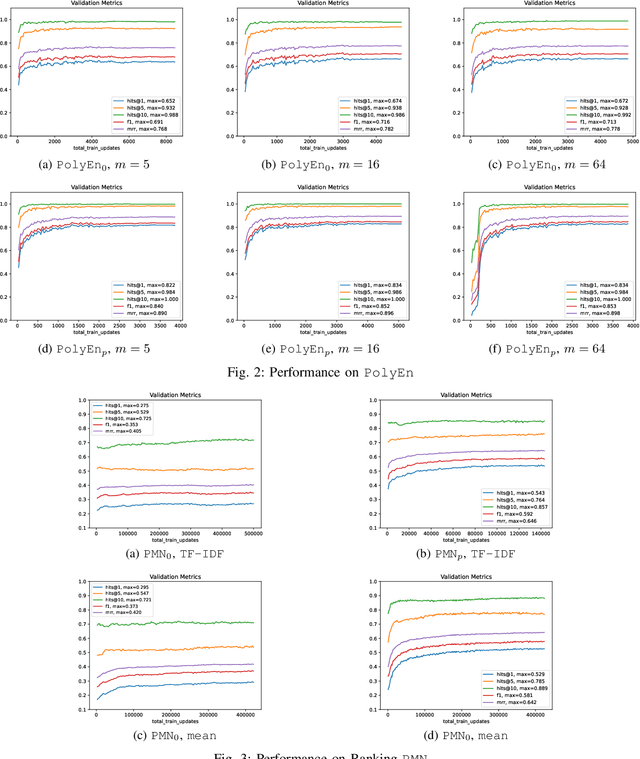
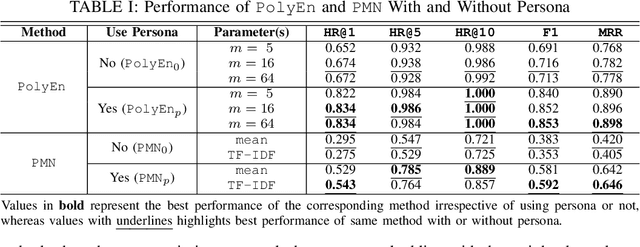
Conversational AI has become an increasingly prominent and practical application of machine learning. However, existing conversational AI techniques still suffer from various limitations. One such limitation is a lack of well-developed methods for incorporating auxiliary information that could help a model understand conversational context better. In this paper, we explore how persona-based information could help improve the quality of response generation in conversations. First, we provide a literature review focusing on the current state-of-the-art methods that utilize persona information. We evaluate two strong baseline methods, the Ranking Profile Memory Network and the Poly-Encoder, on the NeurIPS ConvAI2 benchmark dataset. Our analysis elucidates the importance of incorporating persona information into conversational systems. Additionally, our study highlights several limitations with current state-of-the-art methods and outlines challenges and future research directions for advancing personalized conversational AI technology.
On the Unreasonable Efficiency of State Space Clustering in Personalization Tasks
Dec 24, 2021



In this effort we consider a reinforcement learning (RL) technique for solving personalization tasks with complex reward signals. In particular, our approach is based on state space clustering with the use of a simplistic $k$-means algorithm as well as conventional choices of the network architectures and optimization algorithms. Numerical examples demonstrate the efficiency of different RL procedures and are used to illustrate that this technique accelerates the agent's ability to learn and does not restrict the agent's performance.
Consistency Regularization with Generative Adversarial Networks for Semi-Supervised Image Classification
Jul 08, 2020
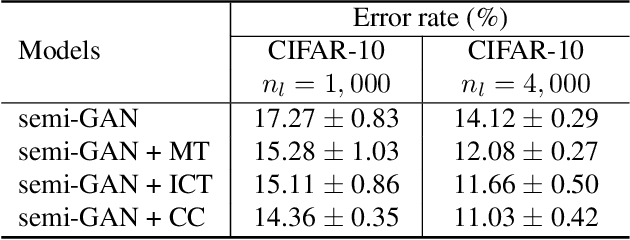
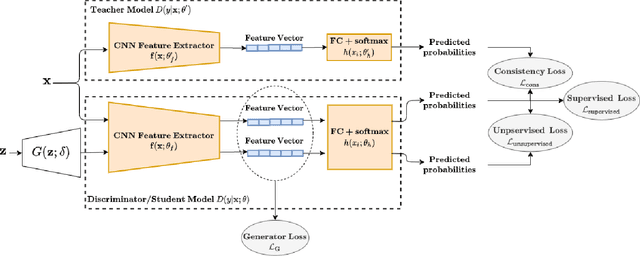

Generative Adversarial Networks (GANs) based semi-supervised learning (SSL) approaches are shown to improve classification performance by utilizing a large number of unlabeled samples in conjunction with limited labeled samples. However, their performance still lags behind the state-of-the-art non-GAN based SSL approaches. One main reason we identify is the lack of consistency in class probability predictions on the same image under local perturbations. This problem was addressed in the past in a generic setting using the label consistency regularization, which enforces the class probability predictions for an input image to be unchanged under various semantic-preserving perturbations. In this work, we incorporate the consistency regularization in the vanilla semi-GAN to address this critical limitation. In particular, we present a new composite consistency regularization method which, in spirit, combines two well-known consistency-based techniques -- Mean Teacher and Interpolation Consistency Training. We demonstrate the efficacy of our approach on two SSL image classification benchmark datasets, SVHN and CIFAR-10. Our experiments show that this new composite consistency regularization based semi-GAN significantly improves its performance and achieves new state-of-the-art performance among GAN-based SSL approaches.
Local Clustering with Mean Teacher for Semi-supervised Learning
Apr 20, 2020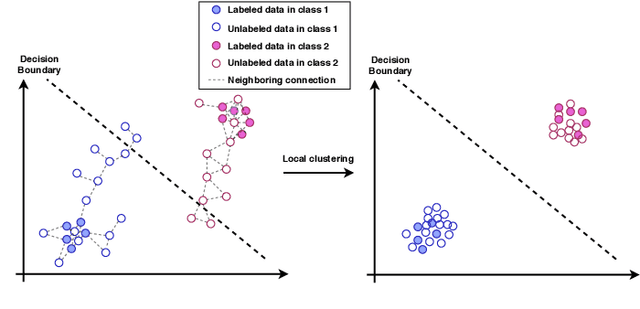
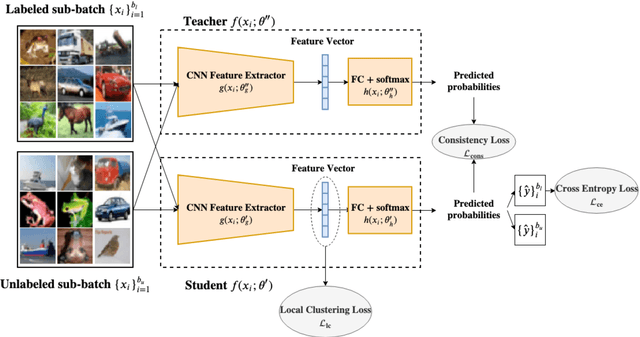
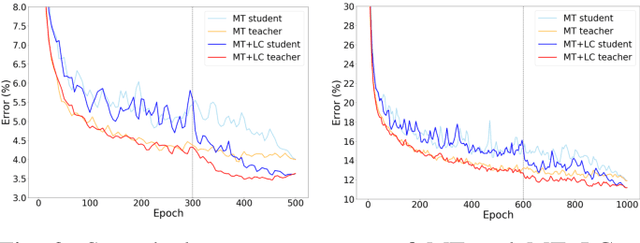

The Mean Teacher (MT) model of Tarvainen and Valpola has shown favorable performance on several semi-supervised benchmark datasets. MT maintains a teacher model's weights as the exponential moving average of a student model's weights and minimizes the divergence between their probability predictions under diverse perturbations of the inputs. However, MT is known to suffer from confirmation bias, that is, reinforcing incorrect teacher model predictions. In this work, we propose a simple yet effective method called Local Clustering (LC) to mitigate the effect of confirmation bias. In MT, each data point is considered independent of other points during training; however, data points are likely to be close to each other in feature space if they share similar features. Motivated by this, we cluster data points locally by minimizing the pairwise distance between neighboring data points in feature space. Combined with a standard classification cross-entropy objective on labeled data points, the misclassified unlabeled data points are pulled towards high-density regions of their correct class with the help of their neighbors, thus improving model performance. We demonstrate on semi-supervised benchmark datasets SVHN and CIFAR-10 that adding our LC loss to MT yields significant improvements compared to MT and performance comparable to the state of the art in semi-supervised learning.
A Survey of Single-Scene Video Anomaly Detection
Apr 13, 2020


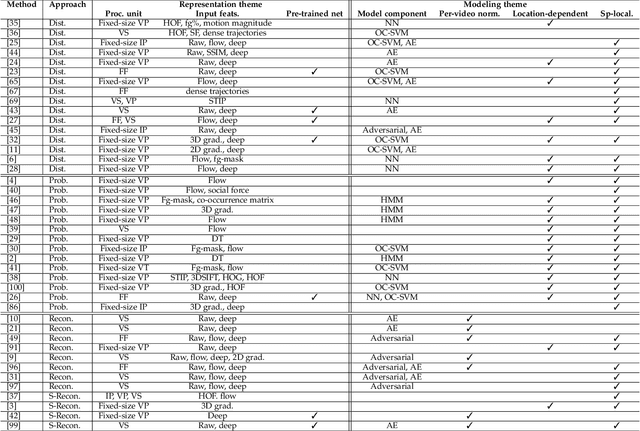
This survey article summarizes research trends on the topic of anomaly detection in video feeds of a single scene. We discuss the various problem formulations, publicly available datasets and evaluation criteria. We categorize and situate past research into an intuitive taxonomy. Finally, we also provide best practices and suggest some possible directions for future research.
Learning a distance function with a Siamese network to localize anomalies in videos
Jan 24, 2020


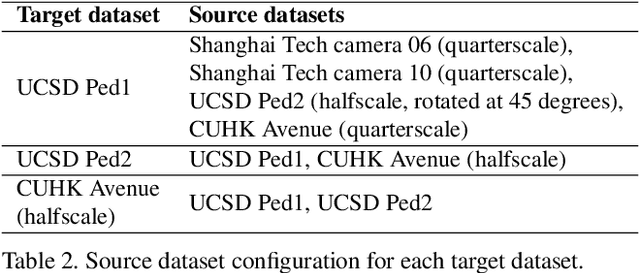
This work introduces a new approach to localize anomalies in surveillance video. The main novelty is the idea of using a Siamese convolutional neural network (CNN) to learn a distance function between a pair of video patches (spatio-temporal regions of video). The learned distance function, which is not specific to the target video, is used to measure the distance between each video patch in the testing video and the video patches found in normal training video. If a testing video patch is not similar to any normal video patch then it must be anomalous. We compare our approach to previously published algorithms using 4 evaluation measures and 3 challenging target benchmark datasets. Experiments show that our approach either surpasses or performs comparably to current state-of-the-art methods.