 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Clustering with Mean Teacher for Semi-supervised Learning
Paper and Code
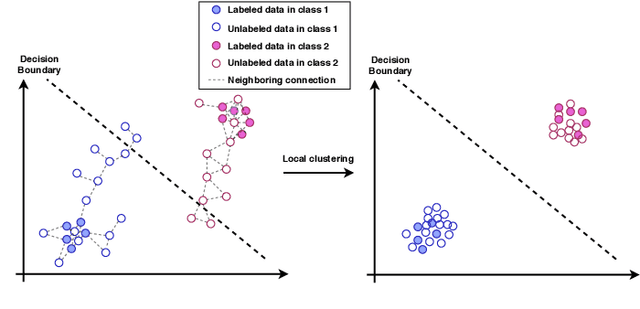
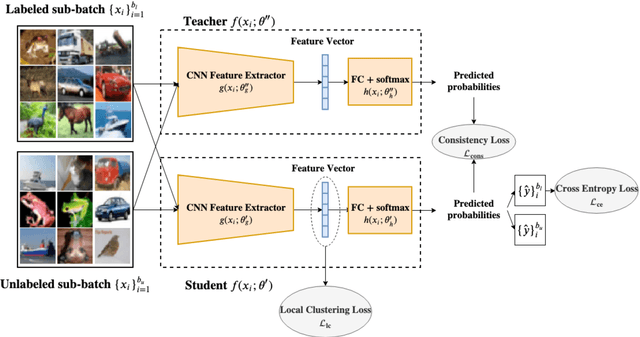
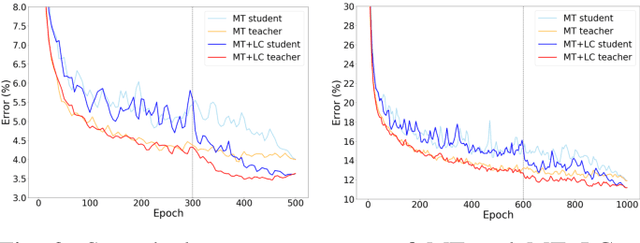

The Mean Teacher (MT) model of Tarvainen and Valpola has shown favorable performance on several semi-supervised benchmark datasets. MT maintains a teacher model's weights as the exponential moving average of a student model's weights and minimizes the divergence between their probability predictions under diverse perturbations of the inputs. However, MT is known to suffer from confirmation bias, that is, reinforcing incorrect teacher model predictions. In this work, we propose a simple yet effective method called Local Clustering (LC) to mitigate the effect of confirmation bias. In MT, each data point is considered independent of other points during training; however, data points are likely to be close to each other in feature space if they share similar features. Motivated by this, we cluster data points locally by minimizing the pairwise distance between neighboring data points in feature space. Combined with a standard classification cross-entropy objective on labeled data points, the misclassified unlabeled data points are pulled towards high-density regions of their correct class with the help of their neighbors, thus improving model performance. We demonstrate on semi-supervised benchmark datasets SVHN and CIFAR-10 that adding our LC loss to MT yields significant improvements compared to MT and performance comparable to the state of the art in semi-supervised learning.