 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic AI-Empowered Dynamic Survey Framework
Feb 03, 2026Survey papers play a central role in synthesizing and organizing scientific knowledge, yet they are increasingly strained by the rapid growth of research output. As new work continues to appear after publication, surveys quickly become outdated, contributing to redundancy and fragmentation in the literature. We reframe survey writing as a long-horizon maintenance problem rather than a one-time generation task, treating surveys as living documents that evolve alongside the research they describe. We propose an agentic Dynamic Survey Framework that supports the continuous updating of existing survey papers by incrementally integrating new work while preserving survey structure and minimizing unnecessary disruption. Using a retrospective experimental setup, we demonstrate that the proposed framework effectively identifies and incorporates emerging research while preserving the coherence and structure of existing surveys.
Programmatic Video Prediction Using Large Language Models
May 20, 2025The task of estimating the world model describing the dynamics of a real world process assumes immense importance for anticipating and preparing for future outcomes. For applications such as video surveillance, robotics applications, autonomous driving, etc. this objective entails synthesizing plausible visual futures, given a few frames of a video to set the visual context. Towards this end, we propose ProgGen, which undertakes the task of video frame prediction by representing the dynamics of the video using a set of neuro-symbolic, human-interpretable set of states (one per frame) by leveraging the inductive biases of Large (Vision) Language Models (LLM/VLM). In particular, ProgGen utilizes LLM/VLM to synthesize programs: (i) to estimate the states of the video, given the visual context (i.e. the frames); (ii) to predict the states corresponding to future time steps by estimating the transition dynamics; (iii) to render the predicted states as visual RGB-frames. Empirical evaluations reveal that our proposed method outperforms competing techniques at the task of video frame prediction in two challenging environments: (i) PhyWorld (ii) Cart Pole. Additionally, ProgGen permits counter-factual reasoning and interpretable video generation attesting to its effectiveness and generalizability for video generation tasks.
Improving Open-World Object Localization by Discovering Background
Apr 24, 2025



Our work addresses the problem of learning to localize objects in an open-world setting, i.e., given the bounding box information of a limited number of object classes during training, the goal is to localize all objects, belonging to both the training and unseen classes in an image, during inference. Towards this end, recent work in this area has focused on improving the characterization of objects either explicitly by proposing new objective functions (localization quality) or implicitly using object-centric auxiliary-information, such as depth information, pixel/region affinity map etc. In this work, we address this problem by incorporating background information to guide the learning of the notion of objectness. Specifically, we propose a novel framework to discover background regions in an image and train an object proposal network to not detect any objects in these regions. We formulate the background discovery task as that of identifying image regions that are not discriminative, i.e., those that are redundant and constitute low information content. We conduct experiments on standard benchmarks to showcase the effectiveness of our proposed approach and observe significant improvements over the previous state-of-the-art approaches for this task.
ComplexVAD: Detecting Interaction Anomalies in Video
Jan 16, 2025Existing video anomaly detection datasets are inadequate for representing complex anomalies that occur due to the interactions between objects. The absence of complex anomalies in previous video anomaly detection datasets affects research by shifting the focus onto simple anomalies. To address this problem, we introduce a new large-scale dataset: ComplexVAD. In addition, we propose a novel method to detect complex anomalies via modeling the interactions between objects using a scene graph with spatio-temporal attributes. With our proposed method and two other state-of-the-art video anomaly detection methods, we obtain baseline scores on ComplexVAD and demonstrate that our new method outperforms existing works.
Equivariant Spatio-Temporal Self-Supervision for LiDAR Object Detection
Apr 17, 2024



Popular representation learning methods encourage feature invariance under transformations applied at the input. However, in 3D perception tasks like object localization and segmentation, outputs are naturally equivariant to some transformations, such as rotation. Using pre-training loss functions that encourage equivariance of features under certain transformations provides a strong self-supervision signal while also retaining information of geometric relationships between transformed feature representations. This can enable improved performance in downstream tasks that are equivariant to such transformations. In this paper, we propose a spatio-temporal equivariant learning framework by considering both spatial and temporal augmentations jointly. Our experiments show that the best performance arises with a pre-training approach that encourages equivariance to translation, scaling, and flip, rotation and scene flow. For spatial augmentations, we find that depending on the transformation, either a contrastive objective or an equivariance-by-classification objective yields best results. To leverage real-world object deformations and motion, we consider sequential LiDAR scene pairs and develop a novel 3D scene flow-based equivariance objective that leads to improved performance overall. We show our pre-training method for 3D object detection which outperforms existing equivariant and invariant approaches in many settings.
Multimodal 3D Object Detection on Unseen Domains
Apr 17, 2024LiDAR datasets for autonomous driving exhibit biases in properties such as point cloud density, range, and object dimensions. As a result, object detection networks trained and evaluated in different environments often experience performance degradation. Domain adaptation approaches assume access to unannotated samples from the test distribution to address this problem. However, in the real world, the exact conditions of deployment and access to samples representative of the test dataset may be unavailable while training. We argue that the more realistic and challenging formulation is to require robustness in performance to unseen target domains. We propose to address this problem in a two-pronged manner. First, we leverage paired LiDAR-image data present in most autonomous driving datasets to perform multimodal object detection. We suggest that working with multimodal features by leveraging both images and LiDAR point clouds for scene understanding tasks results in object detectors more robust to unseen domain shifts. Second, we train a 3D object detector to learn multimodal object features across different distributions and promote feature invariance across these source domains to improve generalizability to unseen target domains. To this end, we propose CLIX$^\text{3D}$, a multimodal fusion and supervised contrastive learning framework for 3D object detection that performs alignment of object features from same-class samples of different domains while pushing the features from different classes apart. We show that CLIX$^\text{3D}$ yields state-of-the-art domain generalization performance under multiple dataset shifts.
Robust Frame-to-Frame Camera Rotation Estimation in Crowded Scenes
Sep 15, 2023



We present an approach to estimating camera rotation in crowded, real-world scenes from handheld monocular video. While camera rotation estimation is a well-studied problem, no previous methods exhibit both high accuracy and acceptable speed in this setting. Because the setting is not addressed well by other datasets, we provide a new dataset and benchmark, with high-accuracy, rigorously verified ground truth, on 17 video sequences. Methods developed for wide baseline stereo (e.g., 5-point methods) perform poorly on monocular video. On the other hand, methods used in autonomous driving (e.g., SLAM) leverage specific sensor setups, specific motion models, or local optimization strategies (lagging batch processing) and do not generalize well to handheld video. Finally, for dynamic scenes, commonly used robustification techniques like RANSAC require large numbers of iterations, and become prohibitively slow. We introduce a novel generalization of the Hough transform on SO(3) to efficiently and robustly find the camera rotation most compatible with optical flow. Among comparably fast methods, ours reduces error by almost 50\% over the next best, and is more accurate than any method, irrespective of speed. This represents a strong new performance point for crowded scenes, an important setting for computer vision. The code and the dataset are available at https://fabiendelattre.com/robust-rotation-estimation.
EVAL: Explainable Video Anomaly Localization
Dec 15, 2022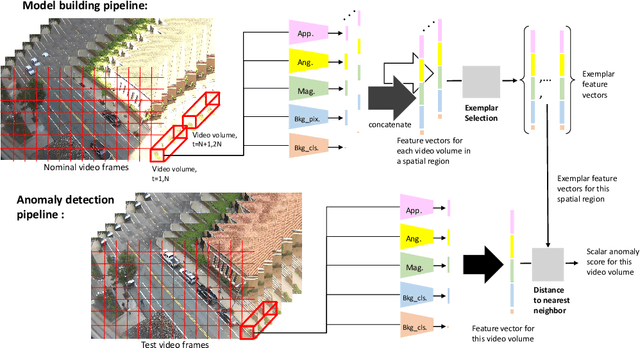



We develop a novel framework for single-scene video anomaly localization that allows for human-understandable reasons for the decisions the system makes. We first learn general representations of objects and their motions (using deep networks) and then use these representations to build a high-level, location-dependent model of any particular scene. This model can be used to detect anomalies in new videos of the same scene. Importantly, our approach is explainable - our high-level appearance and motion features can provide human-understandable reasons for why any part of a video is classified as normal or anomalous. We conduct experiments on standard video anomaly detection datasets (Street Scene, CUHK Avenue, ShanghaiTech and UCSD Ped1, Ped2) and show significant improvements over the previous state-of-the-art.
Cross-Modal Knowledge Transfer Without Task-Relevant Source Data
Sep 08, 2022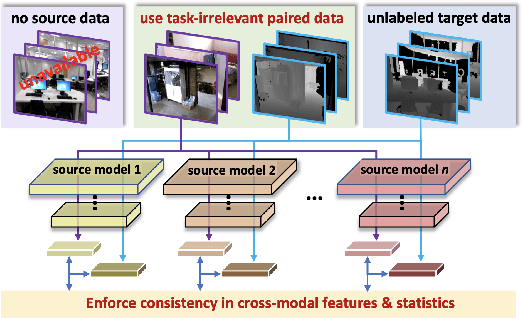

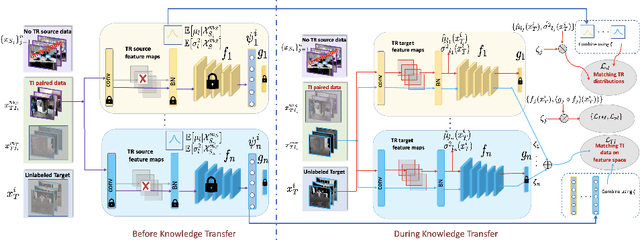

Cost-effective depth and infrared sensors as alternatives to usual RGB sensors are now a reality, and have some advantages over RGB in domains like autonomous navigation and remote sensing. As such, building computer vision and deep learning systems for depth and infrared data are crucial. However, large labeled datasets for these modalities are still lacking. In such cases, transferring knowledge from a neural network trained on a well-labeled large dataset in the source modality (RGB) to a neural network that works on a target modality (depth, infrared, etc.) is of great value. For reasons like memory and privacy, it may not be possible to access the source data, and knowledge transfer needs to work with only the source models. We describe an effective solution, SOCKET: SOurce-free Cross-modal KnowledgE Transfer for this challenging task of transferring knowledge from one source modality to a different target modality without access to task-relevant source data. The framework reduces the modality gap using paired task-irrelevant data, as well as by matching the mean and variance of the target features with the batch-norm statistics that are present in the source models. We show through extensive experiments that our method significantly outperforms existing source-free methods for classification tasks which do not account for the modality gap.
A Survey of Single-Scene Video Anomaly Detection
Apr 13, 2020


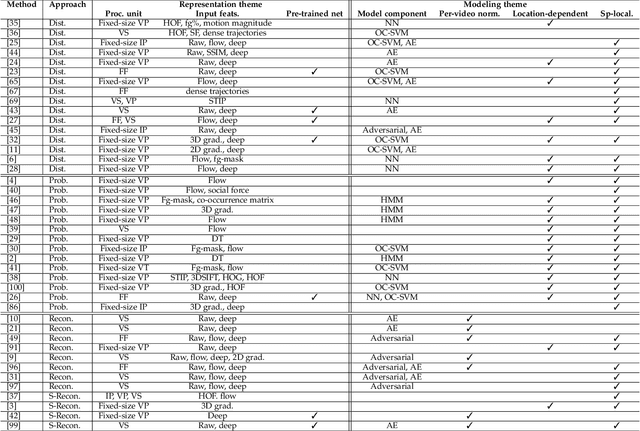
This survey article summarizes research trends on the topic of anomaly detection in video feeds of a single scene. We discuss the various problem formulations, publicly available datasets and evaluation criteria. We categorize and situate past research into an intuitive taxonomy. Finally, we also provide best practices and suggest some possible directions for future research.