 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSocially-Weighted Alignment: A Game-Theoretic Framework for Multi-Agent LLM Systems
Feb 16, 2026Deploying large language model (LLM) agents in shared environments introduces a fundamental tension between individual alignment and collective stability: locally rational decisions can impose negative externalities that degrade system-level performance. We propose Socially-Weighted Alignment (SWA), a game-theoretic framework that modifies inference-time decision making by interpolating between an agent's private objective and an estimate of group welfare via a social weight $λ\in[0,1]$. In a shared-resource congestion game with $n$ agents and congestion severity $β$, we show that SWA induces a critical threshold $λ^*=(n-β)/(n-1)$ above which agents no longer have marginal incentive to increase demand under overload, yielding a phase transition from persistent congestion to stable operation near capacity. We further provide an inference-time algorithmic instantiation of SWA that does not require parameter updates or multi-agent reinforcement learning, and use a multi-agent simulation to empirically validate the predicted threshold behavior.
Agentic AI-Empowered Dynamic Survey Framework
Feb 03, 2026Survey papers play a central role in synthesizing and organizing scientific knowledge, yet they are increasingly strained by the rapid growth of research output. As new work continues to appear after publication, surveys quickly become outdated, contributing to redundancy and fragmentation in the literature. We reframe survey writing as a long-horizon maintenance problem rather than a one-time generation task, treating surveys as living documents that evolve alongside the research they describe. We propose an agentic Dynamic Survey Framework that supports the continuous updating of existing survey papers by incrementally integrating new work while preserving survey structure and minimizing unnecessary disruption. Using a retrospective experimental setup, we demonstrate that the proposed framework effectively identifies and incorporates emerging research while preserving the coherence and structure of existing surveys.
Universal and Efficient Detection of Adversarial Data through Nonuniform Impact on Network Layers
Jun 25, 2025Deep Neural Networks (DNNs) are notoriously vulnerable to adversarial input designs with limited noise budgets. While numerous successful attacks with subtle modifications to original input have been proposed, defense techniques against these attacks are relatively understudied. Existing defense approaches either focus on improving DNN robustness by negating the effects of perturbations or use a secondary model to detect adversarial data. Although equally important, the attack detection approach, which is studied in this work, provides a more practical defense compared to the robustness approach. We show that the existing detection methods are either ineffective against the state-of-the-art attack techniques or computationally inefficient for real-time processing. We propose a novel universal and efficient method to detect adversarial examples by analyzing the varying degrees of impact of attacks on different DNN layers. {Our method trains a lightweight regression model that predicts deeper-layer features from early-layer features, and uses the prediction error to detect adversarial samples.} Through theoretical arguments and extensive experiments, we demonstrate that our detection method is highly effective, computationally efficient for real-time processing, compatible with any DNN architecture, and applicable across different domains, such as image, video, and audio.
* arXiv admin note: substantial text overlap with arXiv:2410.17442
Reliable Radiologic Skeletal Muscle Area Assessment -- A Biomarker for Cancer Cachexia Diagnosis
Mar 19, 2025Cancer cachexia is a common metabolic disorder characterized by severe muscle atrophy which is associated with poor prognosis and quality of life. Monitoring skeletal muscle area (SMA) longitudinally through computed tomography (CT) scans, an imaging modality routinely acquired in cancer care, is an effective way to identify and track this condition. However, existing tools often lack full automation and exhibit inconsistent accuracy, limiting their potential for integration into clinical workflows. To address these challenges, we developed SMAART-AI (Skeletal Muscle Assessment-Automated and Reliable Tool-based on AI), an end-to-end automated pipeline powered by deep learning models (nnU-Net 2D) trained on mid-third lumbar level CT images with 5-fold cross-validation, ensuring generalizability and robustness. SMAART-AI incorporates an uncertainty-based mechanism to flag high-error SMA predictions for expert review, enhancing reliability. We combined the SMA, skeletal muscle index, BMI, and clinical data to train a multi-layer perceptron (MLP) model designed to predict cachexia at the time of cancer diagnosis. Tested on the gastroesophageal cancer dataset, SMAART-AI achieved a Dice score of 97.80% +/- 0.93%, with SMA estimated across all four datasets in this study at a median absolute error of 2.48% compared to manual annotations with SliceOmatic. Uncertainty metrics-variance, entropy, and coefficient of variation-strongly correlated with SMA prediction errors (0.83, 0.76, and 0.73 respectively). The MLP model predicts cachexia with 79% precision, providing clinicians with a reliable tool for early diagnosis and intervention. By combining automation, accuracy, and uncertainty awareness, SMAART-AI bridges the gap between research and clinical application, offering a transformative approach to managing cancer cachexia.
Multimodal AI-driven Biomarker for Early Detection of Cancer Cachexia
Mar 09, 2025Cancer cachexia is a multifactorial syndrome characterized by progressive muscle wasting, metabolic dysfunction, and systemic inflammation, leading to reduced quality of life and increased mortality. Despite extensive research, no single definitive biomarker exists, as cachexia-related indicators such as serum biomarkers, skeletal muscle measurements, and metabolic abnormalities often overlap with other conditions. Existing composite indices, including the Cancer Cachexia Index (CXI), Modified CXI (mCXI), and Cachexia Score (CASCO), integrate multiple biomarkers but lack standardized thresholds, limiting their clinical utility. This study proposes a multimodal AI-based biomarker for early cancer cachexia detection, leveraging open-source large language models (LLMs) and foundation models trained on medical data. The approach integrates heterogeneous patient data, including demographics, disease status, lab reports, radiological imaging (CT scans), and clinical notes, using a machine learning framework that can handle missing data. Unlike previous AI-based models trained on curated datasets, this method utilizes routinely collected clinical data, enhancing real-world applicability. Additionally, the model incorporates confidence estimation, allowing the identification of cases requiring expert review for precise clinical interpretation. Preliminary findings demonstrate that integrating multiple data modalities improves cachexia prediction accuracy at the time of cancer diagnosis. The AI-based biomarker dynamically adapts to patient-specific factors such as age, race, ethnicity, weight, cancer type, and stage, avoiding the limitations of fixed-threshold biomarkers. This multimodal AI biomarker provides a scalable and clinically viable solution for early cancer cachexia detection, facilitating personalized interventions and potentially improving treatment outcomes and patient survival.
ComplexVAD: Detecting Interaction Anomalies in Video
Jan 16, 2025Existing video anomaly detection datasets are inadequate for representing complex anomalies that occur due to the interactions between objects. The absence of complex anomalies in previous video anomaly detection datasets affects research by shifting the focus onto simple anomalies. To address this problem, we introduce a new large-scale dataset: ComplexVAD. In addition, we propose a novel method to detect complex anomalies via modeling the interactions between objects using a scene graph with spatio-temporal attributes. With our proposed method and two other state-of-the-art video anomaly detection methods, we obtain baseline scores on ComplexVAD and demonstrate that our new method outperforms existing works.
WPMixer: Efficient Multi-Resolution Mixing for Long-Term Time Series Forecasting
Dec 22, 2024



Time series forecasting is crucial for various applications, such as weather forecasting, power load forecasting, and financial analysis. In recent studies, MLP-mixer models for time series forecasting have been shown as a promising alternative to transformer-based models. However, the performance of these models is still yet to reach its potential. In this paper, we propose Wavelet Patch Mixer (WPMixer), a novel MLP-based model, for long-term time series forecasting, which leverages the benefits of patching, multi-resolution wavelet decomposition, and mixing. Our model is based on three key components: (i) multi-resolution wavelet decomposition, (ii) patching and embedding, and (iii) MLP mixing. Multi-resolution wavelet decomposition efficiently extracts information in both the frequency and time domains. Patching allows the model to capture an extended history with a look-back window and enhances capturing local information while MLP mixing incorporates global information. Our model significantly outperforms state-of-the-art MLP-based and transformer-based models for long-term time series forecasting in a computationally efficient way, demonstrating its efficacy and potential for practical applications.
Detecting Adversarial Examples
Oct 22, 2024



Deep Neural Networks (DNNs) have been shown to be vulnerable to adversarial examples. While numerous successful adversarial attacks have been proposed, defenses against these attacks remain relatively understudied. Existing defense approaches either focus on negating the effects of perturbations caused by the attacks to restore the DNNs' original predictions or use a secondary model to detect adversarial examples. However, these methods often become ineffective due to the continuous advancements in attack techniques. We propose a novel universal and lightweight method to detect adversarial examples by analyzing the layer outputs of DNNs. Through theoretical justification and extensive experiments, we demonstrate that our detection method is highly effective, compatible with any DNN architecture, and applicable across different domains, such as image, video, and audio.
Future-Proofing Medical Imaging with Privacy-Preserving Federated Learning and Uncertainty Quantification: A Review
Sep 24, 2024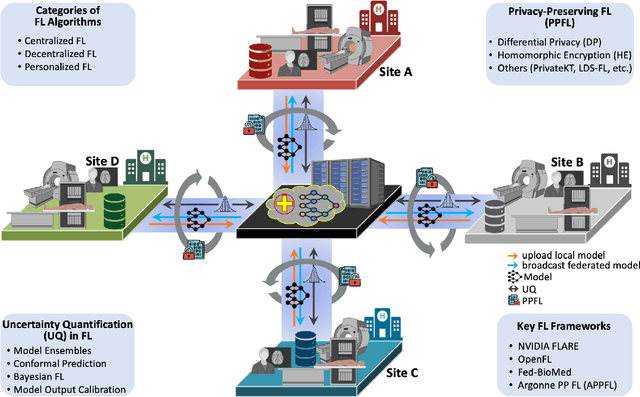
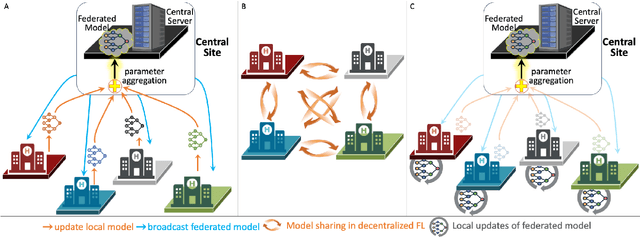
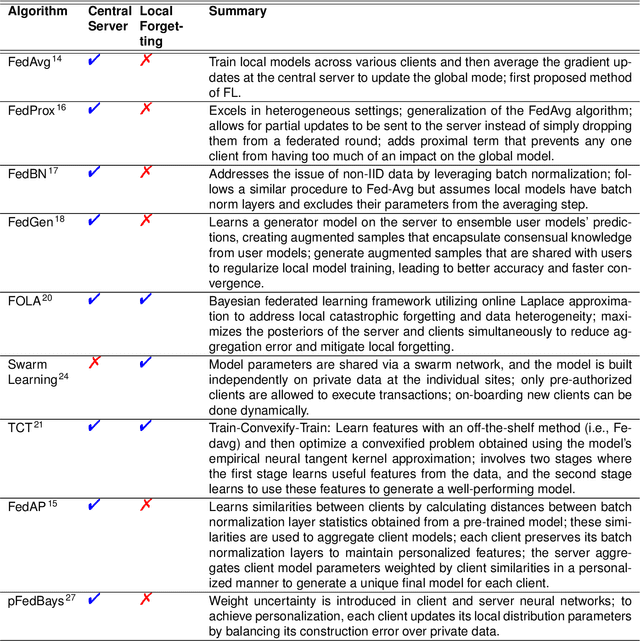
Artificial Intelligence (AI) has demonstrated significant potential in automating various medical imaging tasks, which could soon become routine in clinical practice for disease diagnosis, prognosis, treatment planning, and post-treatment surveillance. However, the privacy concerns surrounding patient data present a major barrier to the widespread adoption of AI in medical imaging, as large, diverse training datasets are essential for developing accurate, generalizable, and robust Artificial intelligence models. Federated Learning (FL) offers a solution that enables organizations to train AI models collaboratively without sharing sensitive data. federated learning exchanges model training information, such as gradients, between the participating sites. Despite its promise, federated learning is still in its developmental stages and faces several challenges. Notably, sensitive information can still be inferred from the gradients shared during model training. Quantifying AI models' uncertainty is vital due to potential data distribution shifts post-deployment, which can affect model performance. Uncertainty quantification (UQ) in FL is particularly challenging due to data heterogeneity across participating sites. This review provides a comprehensive examination of FL, privacy-preserving FL (PPFL), and UQ in FL. We identify key gaps in current FL methodologies and propose future research directions to enhance data privacy and trustworthiness in medical imaging applications.
Privacy Preserving Federated Learning in Medical Imaging with Uncertainty Estimation
Jun 18, 2024
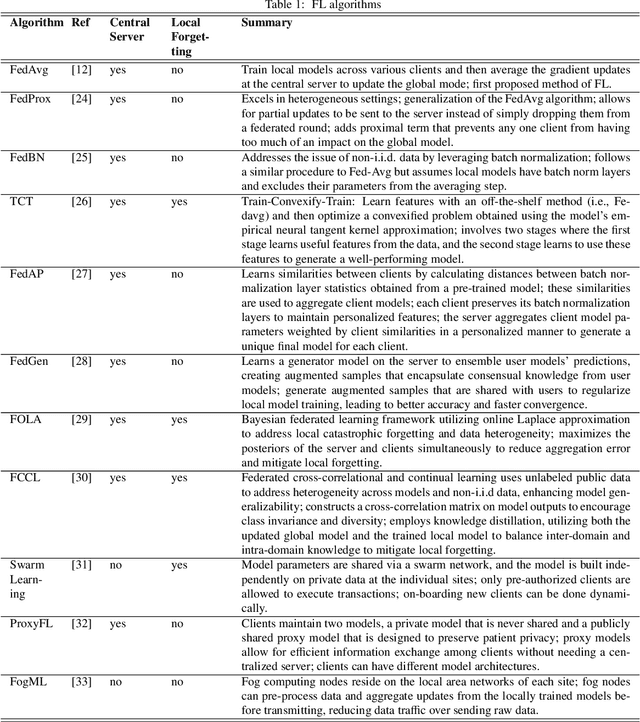

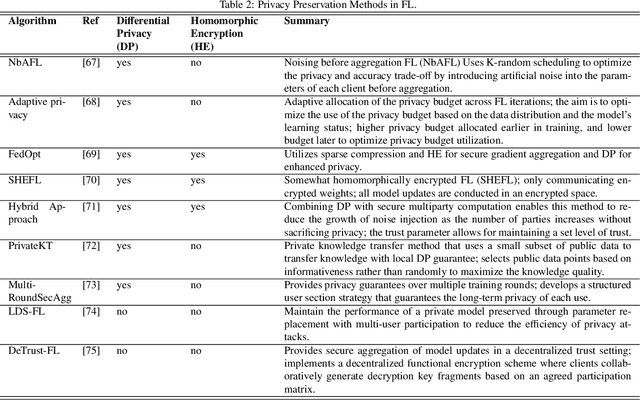
Machine learning (ML) and Artificial Intelligence (AI) have fueled remarkable advancements, particularly in healthcare. Within medical imaging, ML models hold the promise of improving disease diagnoses, treatment planning, and post-treatment monitoring. Various computer vision tasks like image classification, object detection, and image segmentation are poised to become routine in clinical analysis. However, privacy concerns surrounding patient data hinder the assembly of large training datasets needed for developing and training accurate, robust, and generalizable models. Federated Learning (FL) emerges as a compelling solution, enabling organizations to collaborate on ML model training by sharing model training information (gradients) rather than data (e.g., medical images). FL's distributed learning framework facilitates inter-institutional collaboration while preserving patient privacy. However, FL, while robust in privacy preservation, faces several challenges. Sensitive information can still be gleaned from shared gradients that are passed on between organizations during model training. Additionally, in medical imaging, quantifying model confidence\uncertainty accurately is crucial due to the noise and artifacts present in the data. Uncertainty estimation in FL encounters unique hurdles due to data heterogeneity across organizations. This paper offers a comprehensive review of FL, privacy preservation, and uncertainty estimation, with a focus on medical imaging. Alongside a survey of current research, we identify gaps in the field and suggest future directions for FL research to enhance privacy and address noisy medical imaging data challenges.