 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHoneyBee: A Scalable Modular Framework for Creating Multimodal Oncology Datasets with Foundational Embedding Models
Paper and Code
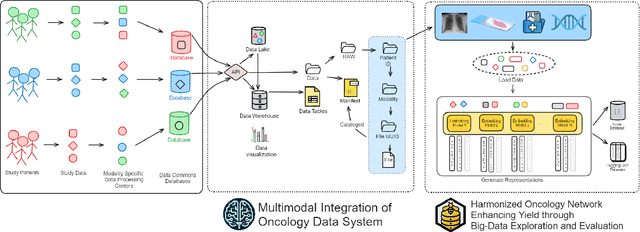



Developing accurate machine learning models for oncology requires large-scale, high-quality multimodal datasets. However, creating such datasets remains challenging due to the complexity and heterogeneity of medical data. To address this challenge, we introduce HoneyBee, a scalable modular framework for building multimodal oncology datasets that leverages foundational models to generate representative embeddings. HoneyBee integrates various data modalities, including clinical records, imaging data, and patient outcomes. It employs data preprocessing techniques and transformer-based architectures to generate embeddings that capture the essential features and relationships within the raw medical data. The generated embeddings are stored in a structured format using Hugging Face datasets and PyTorch dataloaders for accessibility. Vector databases enable efficient querying and retrieval for machine learning applications. We demonstrate the effectiveness of HoneyBee through experiments assessing the quality and representativeness of the embeddings. The framework is designed to be extensible to other medical domains and aims to accelerate oncology research by providing high-quality, machine learning-ready datasets. HoneyBee is an ongoing open-source effort, and the code, datasets, and models are available at the project repository.