 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMedical Image De-Identification Benchmark Challenge
Jul 31, 2025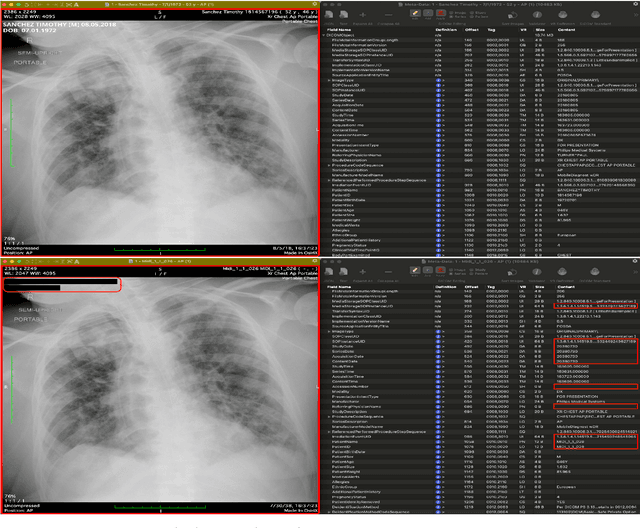
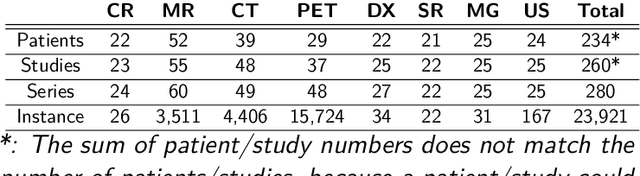
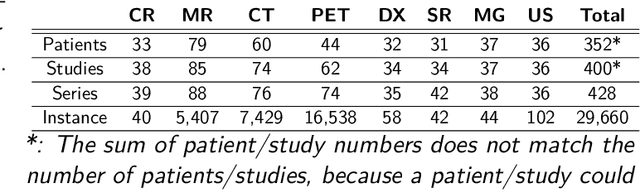
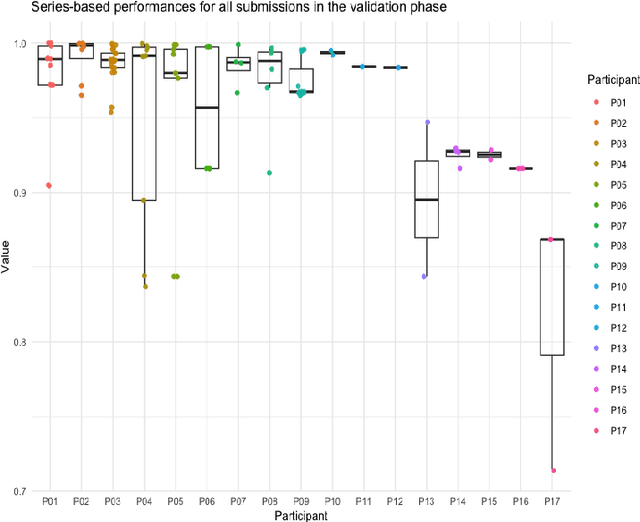
The de-identification (deID) of protected health information (PHI) and personally identifiable information (PII) is a fundamental requirement for sharing medical images, particularly through public repositories, to ensure compliance with patient privacy laws. In addition, preservation of non-PHI metadata to inform and enable downstream development of imaging artificial intelligence (AI) is an important consideration in biomedical research. The goal of MIDI-B was to provide a standardized platform for benchmarking of DICOM image deID tools based on a set of rules conformant to the HIPAA Safe Harbor regulation, the DICOM Attribute Confidentiality Profiles, and best practices in preservation of research-critical metadata, as defined by The Cancer Imaging Archive (TCIA). The challenge employed a large, diverse, multi-center, and multi-modality set of real de-identified radiology images with synthetic PHI/PII inserted. The MIDI-B Challenge consisted of three phases: training, validation, and test. Eighty individuals registered for the challenge. In the training phase, we encouraged participants to tune their algorithms using their in-house or public data. The validation and test phases utilized the DICOM images containing synthetic identifiers (of 216 and 322 subjects, respectively). Ten teams successfully completed the test phase of the challenge. To measure success of a rule-based approach to image deID, scores were computed as the percentage of correct actions from the total number of required actions. The scores ranged from 97.91% to 99.93%. Participants employed a variety of open-source and proprietary tools with customized configurations, large language models, and optical character recognition (OCR). In this paper we provide a comprehensive report on the MIDI-B Challenge's design, implementation, results, and lessons learned.
DICOM De-Identification via Hybrid AI and Rule-Based Framework for Scalable, Uncertainty-Aware Redaction
Jul 31, 2025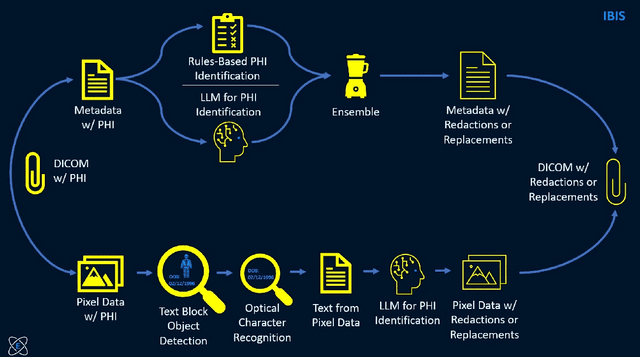


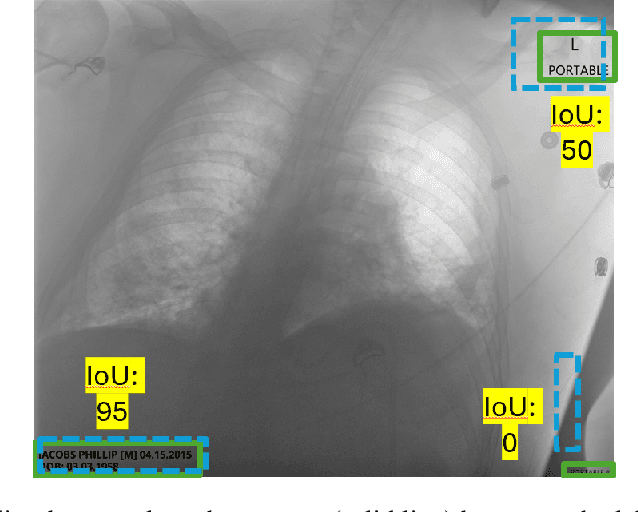
Access to medical imaging and associated text data has the potential to drive major advances in healthcare research and patient outcomes. However, the presence of Protected Health Information (PHI) and Personally Identifiable Information (PII) in Digital Imaging and Communications in Medicine (DICOM) files presents a significant barrier to the ethical and secure sharing of imaging datasets. This paper presents a hybrid de-identification framework developed by Impact Business Information Solutions (IBIS) that combines rule-based and AI-driven techniques, and rigorous uncertainty quantification for comprehensive PHI/PII removal from both metadata and pixel data. Our approach begins with a two-tiered rule-based system targeting explicit and inferred metadata elements, further augmented by a large language model (LLM) fine-tuned for Named Entity Recognition (NER), and trained on a suite of synthetic datasets simulating realistic clinical PHI/PII. For pixel data, we employ an uncertainty-aware Faster R-CNN model to localize embedded text, extract candidate PHI via Optical Character Recognition (OCR), and apply the NER pipeline for final redaction. Crucially, uncertainty quantification provides confidence measures for AI-based detections to enhance automation reliability and enable informed human-in-the-loop verification to manage residual risks. This uncertainty-aware deidentification framework achieves robust performance across benchmark datasets and regulatory standards, including DICOM, HIPAA, and TCIA compliance metrics. By combining scalable automation, uncertainty quantification, and rigorous quality assurance, our solution addresses critical challenges in medical data de-identification and supports the secure, ethical, and trustworthy release of imaging data for research.
Reliable Radiologic Skeletal Muscle Area Assessment -- A Biomarker for Cancer Cachexia Diagnosis
Mar 19, 2025Cancer cachexia is a common metabolic disorder characterized by severe muscle atrophy which is associated with poor prognosis and quality of life. Monitoring skeletal muscle area (SMA) longitudinally through computed tomography (CT) scans, an imaging modality routinely acquired in cancer care, is an effective way to identify and track this condition. However, existing tools often lack full automation and exhibit inconsistent accuracy, limiting their potential for integration into clinical workflows. To address these challenges, we developed SMAART-AI (Skeletal Muscle Assessment-Automated and Reliable Tool-based on AI), an end-to-end automated pipeline powered by deep learning models (nnU-Net 2D) trained on mid-third lumbar level CT images with 5-fold cross-validation, ensuring generalizability and robustness. SMAART-AI incorporates an uncertainty-based mechanism to flag high-error SMA predictions for expert review, enhancing reliability. We combined the SMA, skeletal muscle index, BMI, and clinical data to train a multi-layer perceptron (MLP) model designed to predict cachexia at the time of cancer diagnosis. Tested on the gastroesophageal cancer dataset, SMAART-AI achieved a Dice score of 97.80% +/- 0.93%, with SMA estimated across all four datasets in this study at a median absolute error of 2.48% compared to manual annotations with SliceOmatic. Uncertainty metrics-variance, entropy, and coefficient of variation-strongly correlated with SMA prediction errors (0.83, 0.76, and 0.73 respectively). The MLP model predicts cachexia with 79% precision, providing clinicians with a reliable tool for early diagnosis and intervention. By combining automation, accuracy, and uncertainty awareness, SMAART-AI bridges the gap between research and clinical application, offering a transformative approach to managing cancer cachexia.
Multimodal AI-driven Biomarker for Early Detection of Cancer Cachexia
Mar 09, 2025Cancer cachexia is a multifactorial syndrome characterized by progressive muscle wasting, metabolic dysfunction, and systemic inflammation, leading to reduced quality of life and increased mortality. Despite extensive research, no single definitive biomarker exists, as cachexia-related indicators such as serum biomarkers, skeletal muscle measurements, and metabolic abnormalities often overlap with other conditions. Existing composite indices, including the Cancer Cachexia Index (CXI), Modified CXI (mCXI), and Cachexia Score (CASCO), integrate multiple biomarkers but lack standardized thresholds, limiting their clinical utility. This study proposes a multimodal AI-based biomarker for early cancer cachexia detection, leveraging open-source large language models (LLMs) and foundation models trained on medical data. The approach integrates heterogeneous patient data, including demographics, disease status, lab reports, radiological imaging (CT scans), and clinical notes, using a machine learning framework that can handle missing data. Unlike previous AI-based models trained on curated datasets, this method utilizes routinely collected clinical data, enhancing real-world applicability. Additionally, the model incorporates confidence estimation, allowing the identification of cases requiring expert review for precise clinical interpretation. Preliminary findings demonstrate that integrating multiple data modalities improves cachexia prediction accuracy at the time of cancer diagnosis. The AI-based biomarker dynamically adapts to patient-specific factors such as age, race, ethnicity, weight, cancer type, and stage, avoiding the limitations of fixed-threshold biomarkers. This multimodal AI biomarker provides a scalable and clinically viable solution for early cancer cachexia detection, facilitating personalized interventions and potentially improving treatment outcomes and patient survival.
Improving Radiology Report Conciseness and Structure via Local Large Language Models
Nov 06, 2024In this study, we aim to enhance radiology reporting by improving both the conciseness and structured organization of findings (also referred to as templating), specifically by organizing information according to anatomical regions. This structured approach allows physicians to locate relevant information quickly, increasing the report's utility. We utilize Large Language Models (LLMs) such as Mixtral, Mistral, and Llama to generate concise, well-structured reports. Among these, we primarily focus on the Mixtral model due to its superior adherence to specific formatting requirements compared to other models. To maintain data security and privacy, we run these LLMs locally behind our institution's firewall. We leverage the LangChain framework and apply five distinct prompting strategies to enforce a consistent structure in radiology reports, aiming to eliminate extraneous language and achieve a high level of conciseness. We also introduce a novel metric, the Conciseness Percentage (CP) score, to evaluate report brevity. Our dataset comprises 814 radiology reports authored by seven board-certified body radiologists at our cancer center. In evaluating the different prompting methods, we discovered that the most effective approach for generating concise, well-structured reports involves first instructing the LLM to condense the report, followed by a prompt to structure the content according to specific guidelines. We assessed all prompting strategies based on their ability to handle formatting issues, reduce report length, and adhere to formatting instructions. Our findings demonstrate that open-source, locally deployed LLMs can significantly improve radiology report conciseness and structure while conforming to specified formatting standards.
Future-Proofing Medical Imaging with Privacy-Preserving Federated Learning and Uncertainty Quantification: A Review
Sep 24, 2024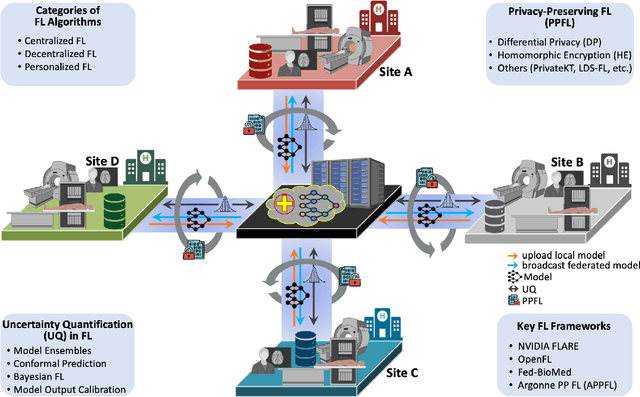
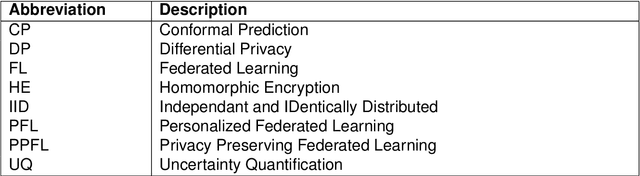
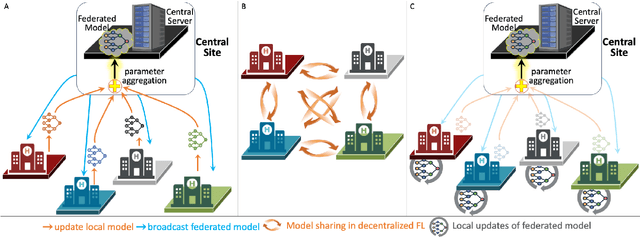
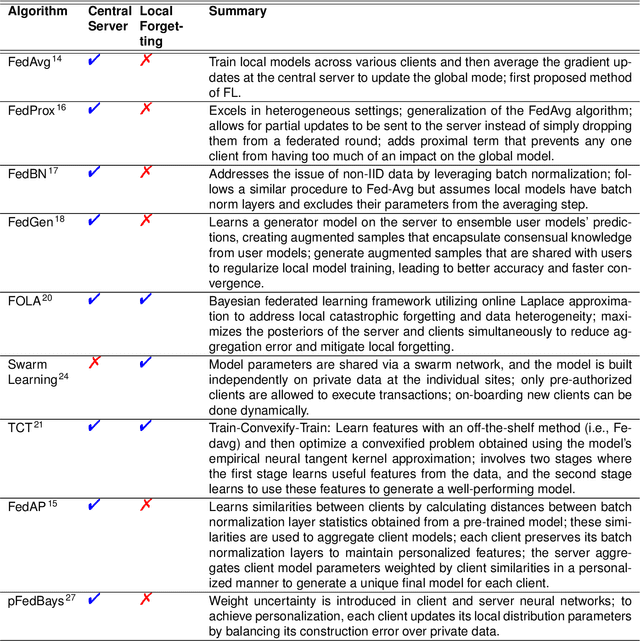
Artificial Intelligence (AI) has demonstrated significant potential in automating various medical imaging tasks, which could soon become routine in clinical practice for disease diagnosis, prognosis, treatment planning, and post-treatment surveillance. However, the privacy concerns surrounding patient data present a major barrier to the widespread adoption of AI in medical imaging, as large, diverse training datasets are essential for developing accurate, generalizable, and robust Artificial intelligence models. Federated Learning (FL) offers a solution that enables organizations to train AI models collaboratively without sharing sensitive data. federated learning exchanges model training information, such as gradients, between the participating sites. Despite its promise, federated learning is still in its developmental stages and faces several challenges. Notably, sensitive information can still be inferred from the gradients shared during model training. Quantifying AI models' uncertainty is vital due to potential data distribution shifts post-deployment, which can affect model performance. Uncertainty quantification (UQ) in FL is particularly challenging due to data heterogeneity across participating sites. This review provides a comprehensive examination of FL, privacy-preserving FL (PPFL), and UQ in FL. We identify key gaps in current FL methodologies and propose future research directions to enhance data privacy and trustworthiness in medical imaging applications.
Privacy Preserving Federated Learning in Medical Imaging with Uncertainty Estimation
Jun 18, 2024
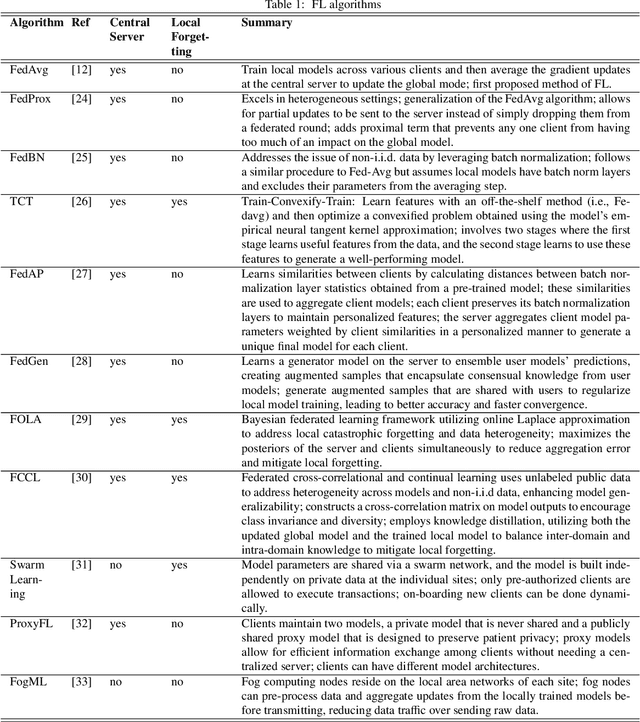

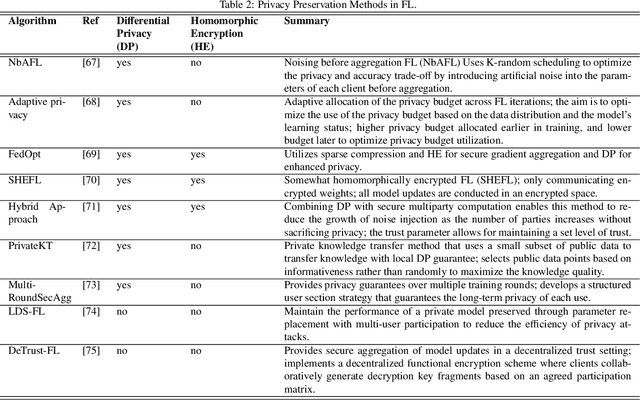
Machine learning (ML) and Artificial Intelligence (AI) have fueled remarkable advancements, particularly in healthcare. Within medical imaging, ML models hold the promise of improving disease diagnoses, treatment planning, and post-treatment monitoring. Various computer vision tasks like image classification, object detection, and image segmentation are poised to become routine in clinical analysis. However, privacy concerns surrounding patient data hinder the assembly of large training datasets needed for developing and training accurate, robust, and generalizable models. Federated Learning (FL) emerges as a compelling solution, enabling organizations to collaborate on ML model training by sharing model training information (gradients) rather than data (e.g., medical images). FL's distributed learning framework facilitates inter-institutional collaboration while preserving patient privacy. However, FL, while robust in privacy preservation, faces several challenges. Sensitive information can still be gleaned from shared gradients that are passed on between organizations during model training. Additionally, in medical imaging, quantifying model confidence\uncertainty accurately is crucial due to the noise and artifacts present in the data. Uncertainty estimation in FL encounters unique hurdles due to data heterogeneity across organizations. This paper offers a comprehensive review of FL, privacy preservation, and uncertainty estimation, with a focus on medical imaging. Alongside a survey of current research, we identify gaps in the field and suggest future directions for FL research to enhance privacy and address noisy medical imaging data challenges.
Embedding-based Multimodal Learning on Pan-Squamous Cell Carcinomas for Improved Survival Outcomes
Jun 11, 2024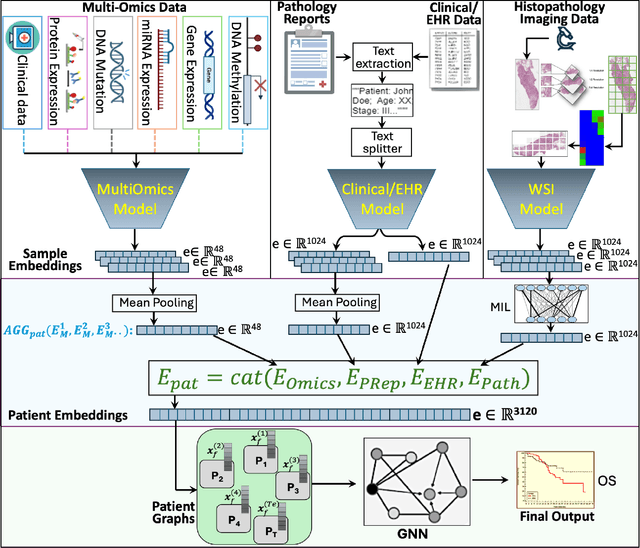
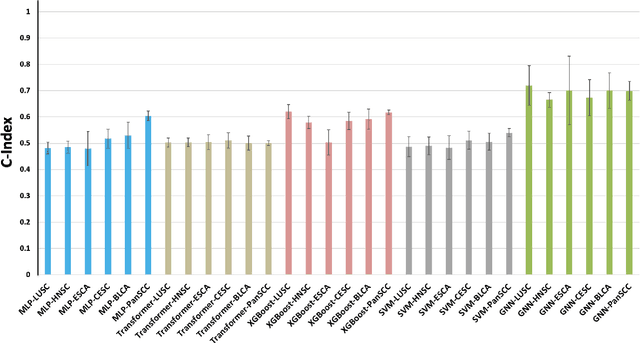

Cancer clinics capture disease data at various scales, from genetic to organ level. Current bioinformatic methods struggle to handle the heterogeneous nature of this data, especially with missing modalities. We propose PARADIGM, a Graph Neural Network (GNN) framework that learns from multimodal, heterogeneous datasets to improve clinical outcome prediction. PARADIGM generates embeddings from multi-resolution data using foundation models, aggregates them into patient-level representations, fuses them into a unified graph, and enhances performance for tasks like survival analysis. We train GNNs on pan-Squamous Cell Carcinomas and validate our approach on Moffitt Cancer Center lung SCC data. Multimodal GNN outperforms other models in patient survival prediction. Converging individual data modalities across varying scales provides a more insightful disease view. Our solution aims to understand the patient's circumstances comprehensively, offering insights on heterogeneous data integration and the benefits of converging maximum data views.
Adversarially Diversified Rehearsal Memory (ADRM): Mitigating Memory Overfitting Challenge in Continual Learning
May 20, 2024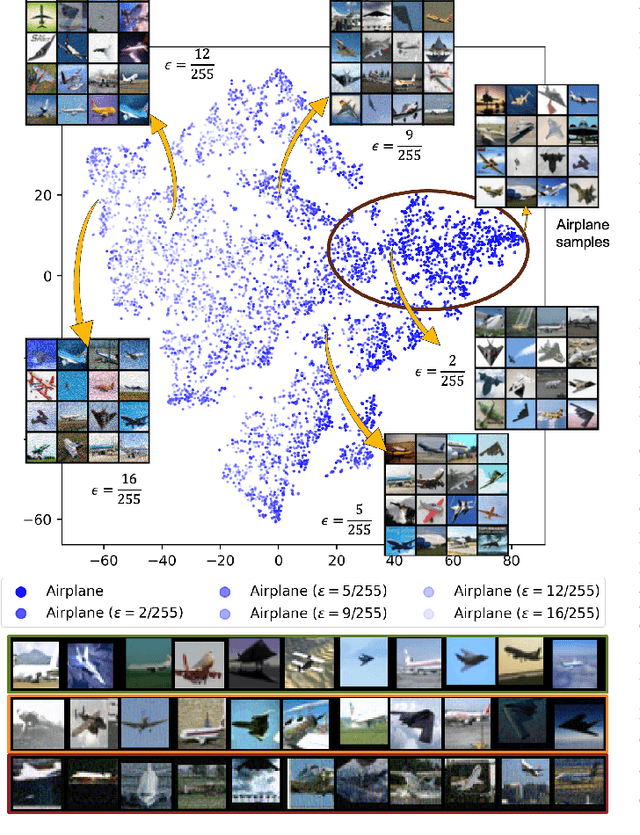

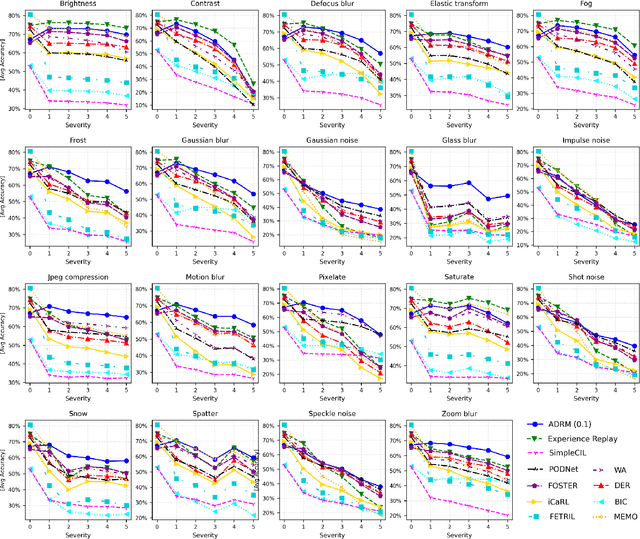

Continual learning focuses on learning non-stationary data distribution without forgetting previous knowledge. Rehearsal-based approaches are commonly used to combat catastrophic forgetting. However, these approaches suffer from a problem called "rehearsal memory overfitting, " where the model becomes too specialized on limited memory samples and loses its ability to generalize effectively. As a result, the effectiveness of the rehearsal memory progressively decays, ultimately resulting in catastrophic forgetting of the learned tasks. We introduce the Adversarially Diversified Rehearsal Memory (ADRM) to address the memory overfitting challenge. This novel method is designed to enrich memory sample diversity and bolster resistance against natural and adversarial noise disruptions. ADRM employs the FGSM attacks to introduce adversarially modified memory samples, achieving two primary objectives: enhancing memory diversity and fostering a robust response to continual feature drifts in memory samples. Our contributions are as follows: Firstly, ADRM addresses overfitting in rehearsal memory by employing FGSM to diversify and increase the complexity of the memory buffer. Secondly, we demonstrate that ADRM mitigates memory overfitting and significantly improves the robustness of CL models, which is crucial for safety-critical applications. Finally, our detailed analysis of features and visualization demonstrates that ADRM mitigates feature drifts in CL memory samples, significantly reducing catastrophic forgetting and resulting in a more resilient CL model. Additionally, our in-depth t-SNE visualizations of feature distribution and the quantification of the feature similarity further enrich our understanding of feature representation in existing CL approaches. Our code is publically available at https://github.com/hikmatkhan/ADRM.
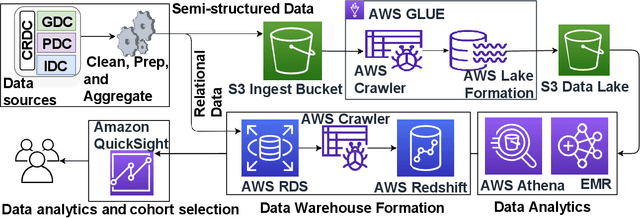
HoneyBee: A Scalable Modular Framework for Creating Multimodal Oncology Datasets with Foundational Embedding Models
May 13, 2024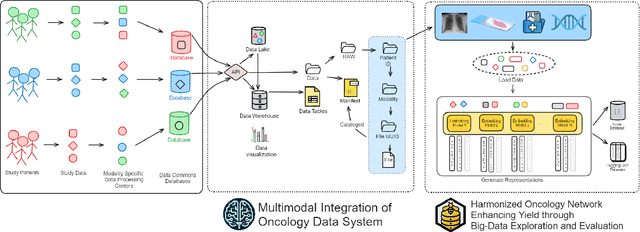



Developing accurate machine learning models for oncology requires large-scale, high-quality multimodal datasets. However, creating such datasets remains challenging due to the complexity and heterogeneity of medical data. To address this challenge, we introduce HoneyBee, a scalable modular framework for building multimodal oncology datasets that leverages foundational models to generate representative embeddings. HoneyBee integrates various data modalities, including clinical records, imaging data, and patient outcomes. It employs data preprocessing techniques and transformer-based architectures to generate embeddings that capture the essential features and relationships within the raw medical data. The generated embeddings are stored in a structured format using Hugging Face datasets and PyTorch dataloaders for accessibility. Vector databases enable efficient querying and retrieval for machine learning applications. We demonstrate the effectiveness of HoneyBee through experiments assessing the quality and representativeness of the embeddings. The framework is designed to be extensible to other medical domains and aims to accelerate oncology research by providing high-quality, machine learning-ready datasets. HoneyBee is an ongoing open-source effort, and the code, datasets, and models are available at the project repository.