 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Radiology Report Conciseness and Structure via Local Large Language Models
Nov 06, 2024In this study, we aim to enhance radiology reporting by improving both the conciseness and structured organization of findings (also referred to as templating), specifically by organizing information according to anatomical regions. This structured approach allows physicians to locate relevant information quickly, increasing the report's utility. We utilize Large Language Models (LLMs) such as Mixtral, Mistral, and Llama to generate concise, well-structured reports. Among these, we primarily focus on the Mixtral model due to its superior adherence to specific formatting requirements compared to other models. To maintain data security and privacy, we run these LLMs locally behind our institution's firewall. We leverage the LangChain framework and apply five distinct prompting strategies to enforce a consistent structure in radiology reports, aiming to eliminate extraneous language and achieve a high level of conciseness. We also introduce a novel metric, the Conciseness Percentage (CP) score, to evaluate report brevity. Our dataset comprises 814 radiology reports authored by seven board-certified body radiologists at our cancer center. In evaluating the different prompting methods, we discovered that the most effective approach for generating concise, well-structured reports involves first instructing the LLM to condense the report, followed by a prompt to structure the content according to specific guidelines. We assessed all prompting strategies based on their ability to handle formatting issues, reduce report length, and adhere to formatting instructions. Our findings demonstrate that open-source, locally deployed LLMs can significantly improve radiology report conciseness and structure while conforming to specified formatting standards.
Vision-Language Models for Medical Report Generation and Visual Question Answering: A Review
Mar 04, 2024



Medical vision-language models (VLMs) combine computer vision and natural language processing to analyze visual and textual medical data. Our paper reviews recent advancements in developing VLMs specialized for healthcare, focusing on models designed for medical report generation and visual question answering. We provide background on natural language processing and computer vision, explaining how techniques from both fields are integrated into VLMs to enable learning from multimodal data. Key areas we address include the exploration of medical vision-language datasets, in-depth analyses of architectures and pre-training strategies employed in recent noteworthy medical VLMs, and comprehensive discussion on evaluation metrics for assessing VLMs' performance in medical report generation and visual question answering. We also highlight current challenges and propose future directions, including enhancing clinical validity and addressing patient privacy concerns. Overall, our review summarizes recent progress in developing VLMs to harness multimodal medical data for improved healthcare applications.
Learning on Persistence Diagrams as Radon Measures
Dec 16, 2022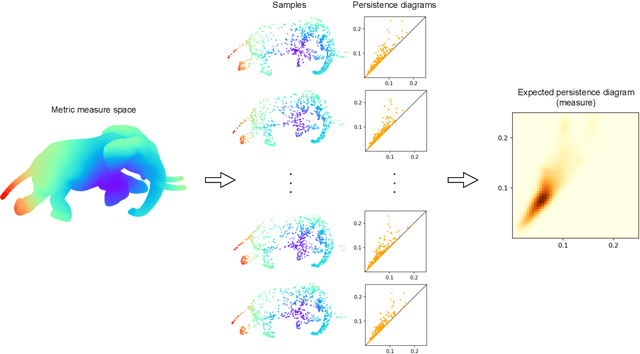

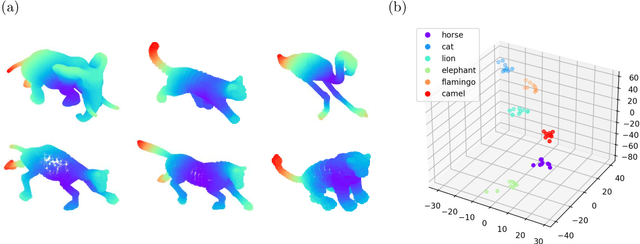

Persistence diagrams are common descriptors of the topological structure of data appearing in various classification and regression tasks. They can be generalized to Radon measures supported on the birth-death plane and endowed with an optimal transport distance. Examples of such measures are expectations of probability distributions on the space of persistence diagrams. In this paper, we develop methods for approximating continuous functions on the space of Radon measures supported on the birth-death plane, as well as their utilization in supervised learning tasks. Indeed, we show that any continuous function defined on a compact subset of the space of such measures (e.g., a classifier or regressor) can be approximated arbitrarily well by polynomial combinations of features computed using a continuous compactly supported function on the birth-death plane (a template). We provide insights into the structure of relatively compact subsets of the space of Radon measures, and test our approximation methodology on various data sets and supervised learning tasks.