 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeNMo: A Self-Normalizing Deep Learning Model for Enhanced Multi-Omics Data Analysis in Oncology
Paper and Code
May 13, 2024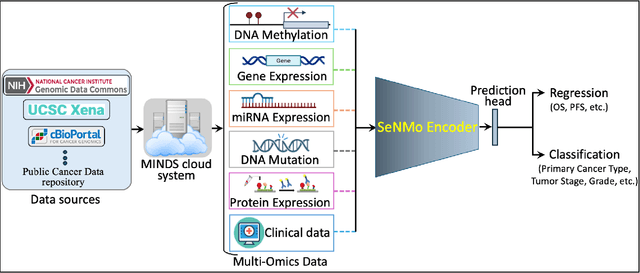
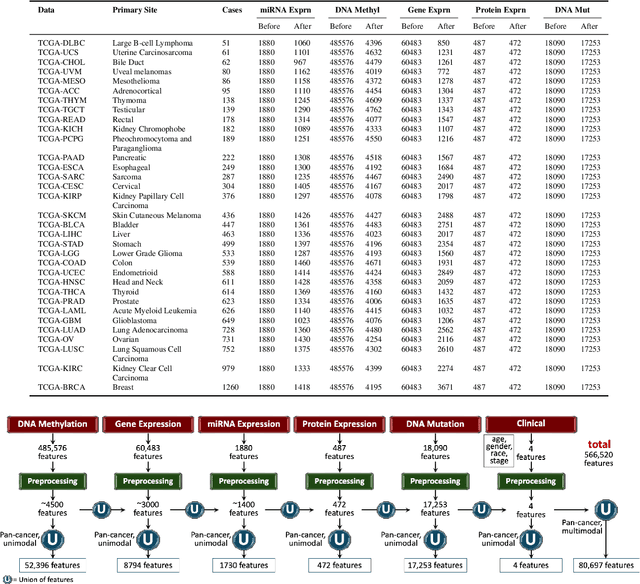


Multi-omics research has enhanced our understanding of cancer heterogeneity and progression. Investigating molecular data through multi-omics approaches is crucial for unraveling the complex biological mechanisms underlying cancer, thereby enabling effective diagnosis, treatment, and prevention strategies. However, predicting patient outcomes through integration of all available multi-omics data is an under-study research direction. Here, we present SeNMo (Self-normalizing Network for Multi-omics), a deep neural network trained on multi-omics data across 33 cancer types. SeNMo is efficient in handling multi-omics data characterized by high-width (many features) and low-length (fewer samples) attributes. We trained SeNMo for the task of overall survival using pan-cancer data involving 33 cancer sites from Genomics Data Commons (GDC). The training data includes gene expression, DNA methylation, miRNA expression, DNA mutations, protein expression modalities, and clinical data. We evaluated the model's performance in predicting overall survival using concordance index (C-Index). SeNMo performed consistently well in training regime, with the validation C-Index of 0.76 on GDC's public data. In the testing regime, SeNMo performed with a C-Index of 0.758 on a held-out test set. The model showed an average accuracy of 99.8% on the task of classifying the primary cancer type on the pan-cancer test cohort. SeNMo proved to be a mini-foundation model for multi-omics oncology data because it demonstrated robust performance, and adaptability not only across molecular data types but also on the classification task of predicting the primary cancer type of patients. SeNMo can be further scaled to any cancer site and molecular data type. We believe SeNMo and similar models are poised to transform the oncology landscape, offering hope for more effective, efficient, and patient-centric cancer care.