 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Neo-Adjuvant Chemotherapy Response in Triple-Negative Breast Cancer Using Pre-Treatment Histopathologic Images
May 20, 2025Triple-negative breast cancer (TNBC) is an aggressive subtype defined by the lack of estrogen receptor (ER), progesterone receptor (PR), and human epidermal growth factor receptor 2 (HER2) expression, resulting in limited targeted treatment options. Neoadjuvant chemotherapy (NACT) is the standard treatment for early-stage TNBC, with pathologic complete response (pCR) serving as a key prognostic marker; however, only 40-50% of patients with TNBC achieve pCR. Accurate prediction of NACT response is crucial to optimize therapy, avoid ineffective treatments, and improve patient outcomes. In this study, we developed a deep learning model to predict NACT response using pre-treatment hematoxylin and eosin (H&E)-stained biopsy images. Our model achieved promising results in five-fold cross-validation (accuracy: 82%, AUC: 0.86, F1-score: 0.84, sensitivity: 0.85, specificity: 0.81, precision: 0.80). Analysis of model attention maps in conjunction with multiplexed immunohistochemistry (mIHC) data revealed that regions of high predictive importance consistently colocalized with tumor areas showing elevated PD-L1 expression, CD8+ T-cell infiltration, and CD163+ macrophage density - all established biomarkers of treatment response. Our findings indicate that incorporating IHC-derived immune profiling data could substantially improve model interpretability and predictive performance. Furthermore, this approach may accelerate the discovery of novel histopathological biomarkers for NACT and advance the development of personalized treatment strategies for TNBC patients.
Adversarially Diversified Rehearsal Memory (ADRM): Mitigating Memory Overfitting Challenge in Continual Learning
May 20, 2024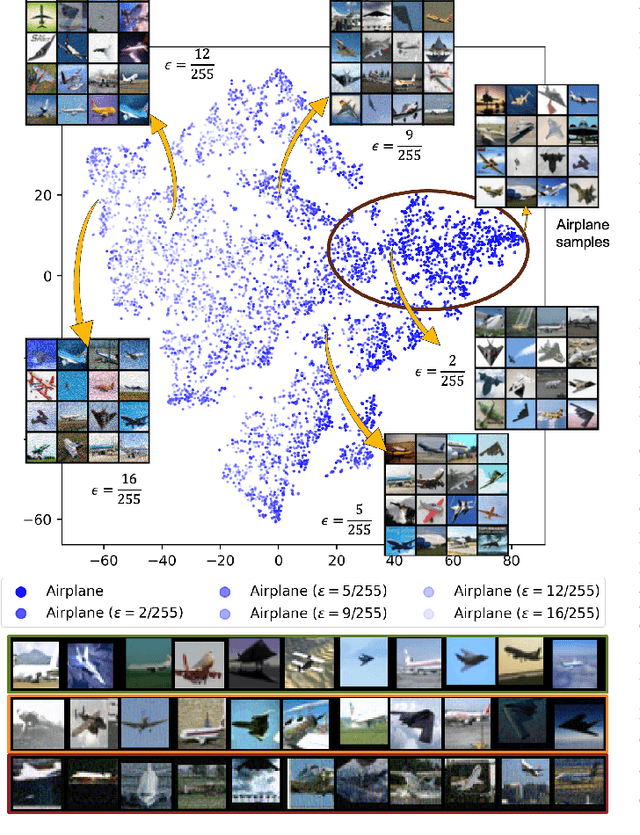

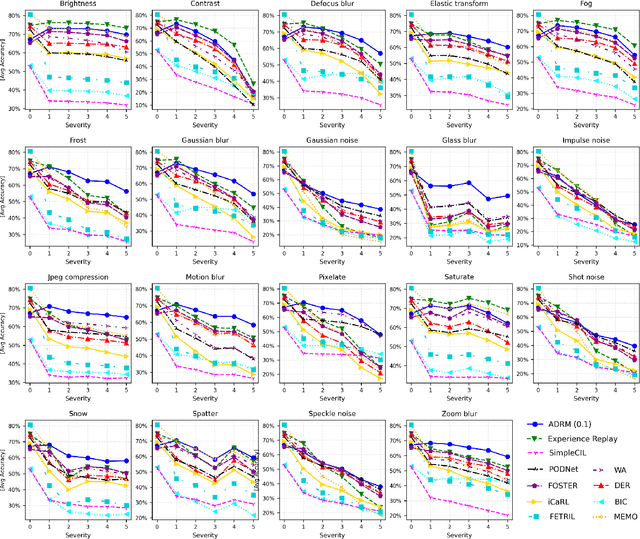

Continual learning focuses on learning non-stationary data distribution without forgetting previous knowledge. Rehearsal-based approaches are commonly used to combat catastrophic forgetting. However, these approaches suffer from a problem called "rehearsal memory overfitting, " where the model becomes too specialized on limited memory samples and loses its ability to generalize effectively. As a result, the effectiveness of the rehearsal memory progressively decays, ultimately resulting in catastrophic forgetting of the learned tasks. We introduce the Adversarially Diversified Rehearsal Memory (ADRM) to address the memory overfitting challenge. This novel method is designed to enrich memory sample diversity and bolster resistance against natural and adversarial noise disruptions. ADRM employs the FGSM attacks to introduce adversarially modified memory samples, achieving two primary objectives: enhancing memory diversity and fostering a robust response to continual feature drifts in memory samples. Our contributions are as follows: Firstly, ADRM addresses overfitting in rehearsal memory by employing FGSM to diversify and increase the complexity of the memory buffer. Secondly, we demonstrate that ADRM mitigates memory overfitting and significantly improves the robustness of CL models, which is crucial for safety-critical applications. Finally, our detailed analysis of features and visualization demonstrates that ADRM mitigates feature drifts in CL memory samples, significantly reducing catastrophic forgetting and resulting in a more resilient CL model. Additionally, our in-depth t-SNE visualizations of feature distribution and the quantification of the feature similarity further enrich our understanding of feature representation in existing CL approaches. Our code is publically available at https://github.com/hikmatkhan/ADRM.
Brain-Inspired Continual Learning-Robust Feature Distillation and Re-Consolidation for Class Incremental Learning
Apr 22, 2024Artificial intelligence (AI) and neuroscience share a rich history, with advancements in neuroscience shaping the development of AI systems capable of human-like knowledge retention. Leveraging insights from neuroscience and existing research in adversarial and continual learning, we introduce a novel framework comprising two core concepts: feature distillation and re-consolidation. Our framework, named Robust Rehearsal, addresses the challenge of catastrophic forgetting inherent in continual learning (CL) systems by distilling and rehearsing robust features. Inspired by the mammalian brain's memory consolidation process, Robust Rehearsal aims to emulate the rehearsal of distilled experiences during learning tasks. Additionally, it mimics memory re-consolidation, where new experiences influence the integration of past experiences to mitigate forgetting. Extensive experiments conducted on CIFAR10, CIFAR100, and real-world helicopter attitude datasets showcase the superior performance of CL models trained with Robust Rehearsal compared to baseline methods. Furthermore, examining different optimization training objectives-joint, continual, and adversarial learning-we highlight the crucial role of feature learning in model performance. This underscores the significance of rehearsing CL-robust samples in mitigating catastrophic forgetting. In conclusion, aligning CL approaches with neuroscience insights offers promising solutions to the challenge of catastrophic forgetting, paving the way for more robust and human-like AI systems.
The Importance of Robust Features in Mitigating Catastrophic Forgetting
Jun 29, 2023Continual learning (CL) is an approach to address catastrophic forgetting, which refers to forgetting previously learned knowledge by neural networks when trained on new tasks or data distributions. The adversarial robustness has decomposed features into robust and non-robust types and demonstrated that models trained on robust features significantly enhance adversarial robustness. However, no study has been conducted on the efficacy of robust features from the lens of the CL model in mitigating catastrophic forgetting in CL. In this paper, we introduce the CL robust dataset and train four baseline models on both the standard and CL robust datasets. Our results demonstrate that the CL models trained on the CL robust dataset experienced less catastrophic forgetting of the previously learned tasks than when trained on the standard dataset. Our observations highlight the significance of the features provided to the underlying CL models, showing that CL robust features can alleviate catastrophic forgetting.
Deep Ensemble for Rotorcraft Attitude Prediction
Jun 29, 2023Historically, the rotorcraft community has experienced a higher fatal accident rate than other aviation segments, including commercial and general aviation. Recent advancements in artificial intelligence (AI) and the application of these technologies in different areas of our lives are both intriguing and encouraging. When developed appropriately for the aviation domain, AI techniques provide an opportunity to help design systems that can address rotorcraft safety challenges. Our recent work demonstrated that AI algorithms could use video data from onboard cameras and correctly identify different flight parameters from cockpit gauges, e.g., indicated airspeed. These AI-based techniques provide a potentially cost-effective solution, especially for small helicopter operators, to record the flight state information and perform post-flight analyses. We also showed that carefully designed and trained AI systems could accurately predict rotorcraft attitude (i.e., pitch and yaw) from outside scenes (images or video data). Ordinary off-the-shelf video cameras were installed inside the rotorcraft cockpit to record the outside scene, including the horizon. The AI algorithm could correctly identify rotorcraft attitude at an accuracy in the range of 80\%. In this work, we combined five different onboard camera viewpoints to improve attitude prediction accuracy to 94\%. In this paper, five onboard camera views included the pilot windshield, co-pilot windshield, pilot Electronic Flight Instrument System (EFIS) display, co-pilot EFIS display, and the attitude indicator gauge. Using video data from each camera view, we trained various convolutional neural networks (CNNs), which achieved prediction accuracy in the range of 79\% % to 90\% %. We subsequently ensembled the learned knowledge from all CNNs and achieved an ensembled accuracy of 93.3\%.
Susceptibility of Continual Learning Against Adversarial Attacks
Jul 14, 2022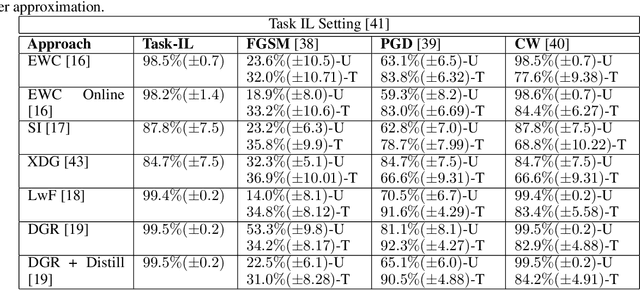

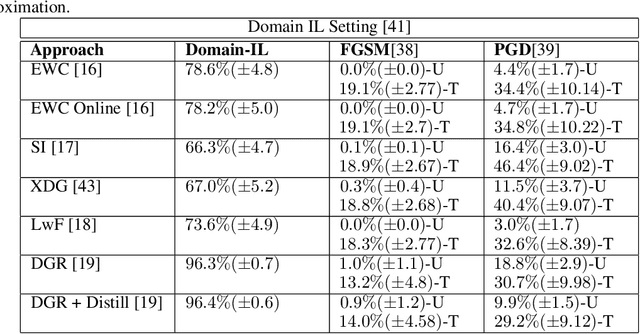
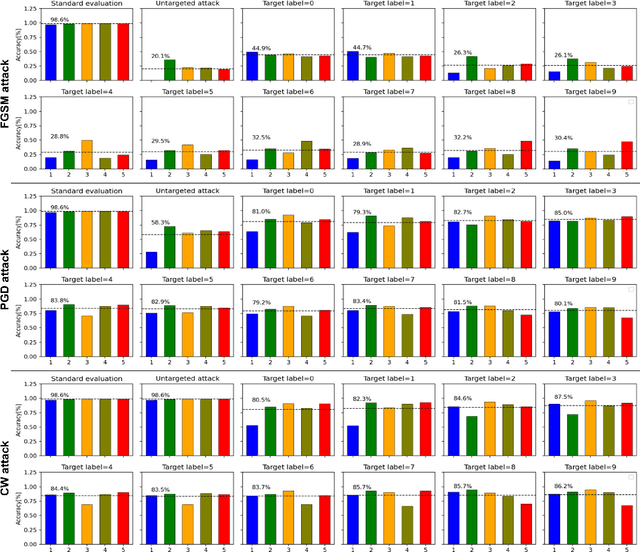
The recent advances in continual (incremental or lifelong) learning have concentrated on the prevention of forgetting that can lead to catastrophic consequences, but there are two outstanding challenges that must be addressed. The first is the evaluation of the robustness of the proposed methods. The second is ensuring the security of learned tasks remains largely unexplored. This paper presents a comprehensive study of the susceptibility of the continually learned tasks (including both current and previously learned tasks) that are vulnerable to forgetting. Such vulnerability of tasks against adversarial attacks raises profound issues in data integrity and privacy. We consider all three scenarios (i.e, task-incremental leaning, domain-incremental learning and class-incremental learning) of continual learning and explore three regularization-based experiments, three replay-based experiments, and one hybrid technique based on the reply and exemplar approach. We examine the robustness of these methods. In particular, we consider cases where we demonstrate that any class belonging to the current or previously learned tasks is prone to misclassification. Our observations, we identify potential limitations in continual learning approaches against adversarial attacks. Our empirical study recommends that the research community consider the robustness of the proposed continual learning approaches and invest extensive efforts in mitigating catastrophic forgetting.