 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Importance of Robust Features in Mitigating Catastrophic Forgetting
Jun 29, 2023Continual learning (CL) is an approach to address catastrophic forgetting, which refers to forgetting previously learned knowledge by neural networks when trained on new tasks or data distributions. The adversarial robustness has decomposed features into robust and non-robust types and demonstrated that models trained on robust features significantly enhance adversarial robustness. However, no study has been conducted on the efficacy of robust features from the lens of the CL model in mitigating catastrophic forgetting in CL. In this paper, we introduce the CL robust dataset and train four baseline models on both the standard and CL robust datasets. Our results demonstrate that the CL models trained on the CL robust dataset experienced less catastrophic forgetting of the previously learned tasks than when trained on the standard dataset. Our observations highlight the significance of the features provided to the underlying CL models, showing that CL robust features can alleviate catastrophic forgetting.
Efficient Scopeformer: Towards Scalable and Rich Feature Extraction for Intracranial Hemorrhage Detection
Feb 01, 2023The quality and richness of feature maps extracted by convolution neural networks (CNNs) and vision Transformers (ViTs) directly relate to the robust model performance. In medical computer vision, these information-rich features are crucial for detecting rare cases within large datasets. This work presents the "Scopeformer," a novel multi-CNN-ViT model for intracranial hemorrhage classification in computed tomography (CT) images. The Scopeformer architecture is scalable and modular, which allows utilizing various CNN architectures as the backbone with diversified output features and pre-training strategies. We propose effective feature projection methods to reduce redundancies among CNN-generated features and to control the input size of ViTs. Extensive experiments with various Scopeformer models show that the model performance is proportional to the number of convolutional blocks employed in the feature extractor. Using multiple strategies, including diversifying the pre-training paradigms for CNNs, different pre-training datasets, and style transfer techniques, we demonstrate an overall improvement in the model performance at various computational budgets. Later, we propose smaller compute-efficient Scopeformer versions with three different types of input and output ViT configurations. Efficient Scopeformers use four different pre-trained CNN architectures as feature extractors to increase feature richness. Our best Efficient Scopeformer model achieved an accuracy of 96.94\% and a weighted logarithmic loss of 0.083 with an eight times reduction in the number of trainable parameters compared to the base Scopeformer. Another version of the Efficient Scopeformer model further reduced the parameter space by almost 17 times with negligible performance reduction. Hybrid CNNs and ViTs might provide the desired feature richness for developing accurate medical computer vision models
Trustworthy Medical Segmentation with Uncertainty Estimation
Nov 30, 2021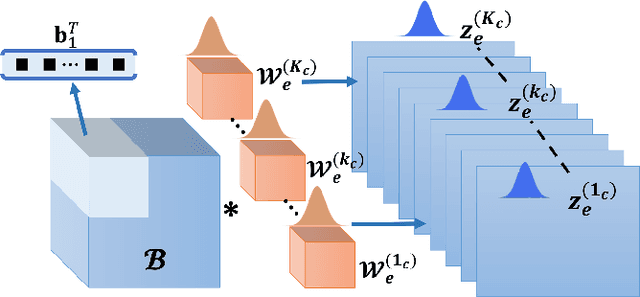
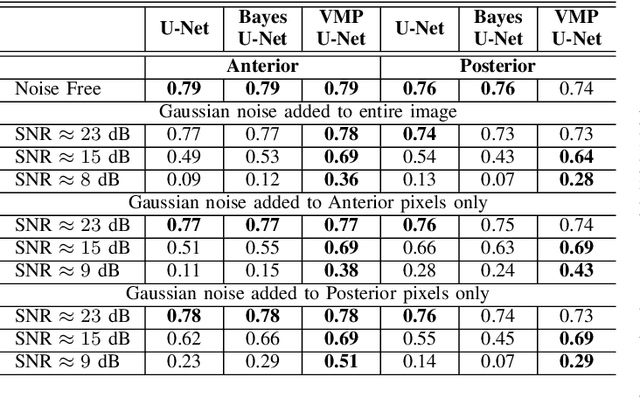
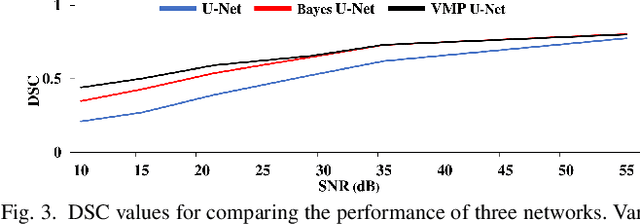

Deep Learning (DL) holds great promise in reshaping the healthcare systems given its precision, efficiency, and objectivity. However, the brittleness of DL models to noisy and out-of-distribution inputs is ailing their deployment in the clinic. Most systems produce point estimates without further information about model uncertainty or confidence. This paper introduces a new Bayesian deep learning framework for uncertainty quantification in segmentation neural networks, specifically encoder-decoder architectures. The proposed framework uses the first-order Taylor series approximation to propagate and learn the first two moments (mean and covariance) of the distribution of the model parameters given the training data by maximizing the evidence lower bound. The output consists of two maps: the segmented image and the uncertainty map of the segmentation. The uncertainty in the segmentation decisions is captured by the covariance matrix of the predictive distribution. We evaluate the proposed framework on medical image segmentation data from Magnetic Resonances Imaging and Computed Tomography scans. Our experiments on multiple benchmark datasets demonstrate that the proposed framework is more robust to noise and adversarial attacks as compared to state-of-the-art segmentation models. Moreover, the uncertainty map of the proposed framework associates low confidence (or equivalently high uncertainty) to patches in the test input images that are corrupted with noise, artifacts or adversarial attacks. Thus, the model can self-assess its segmentation decisions when it makes an erroneous prediction or misses part of the segmentation structures, e.g., tumor, by presenting higher values in the uncertainty map.
Robust Learning via Ensemble Density Propagation in Deep Neural Networks
Nov 10, 2021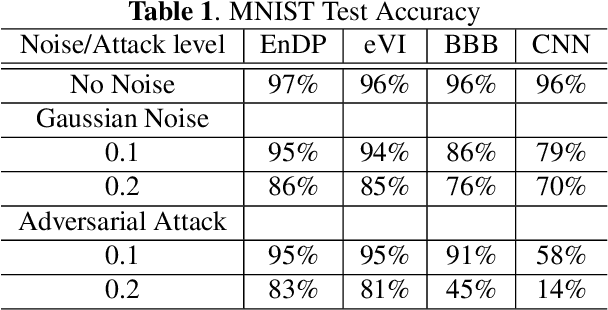
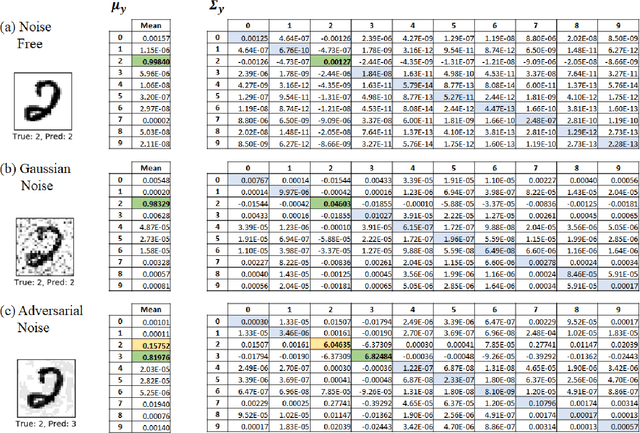
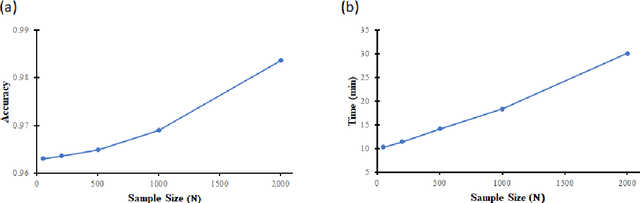
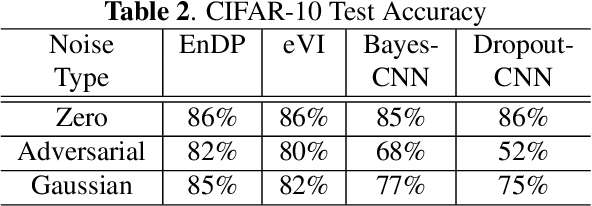
Learning in uncertain, noisy, or adversarial environments is a challenging task for deep neural networks (DNNs). We propose a new theoretically grounded and efficient approach for robust learning that builds upon Bayesian estimation and Variational Inference. We formulate the problem of density propagation through layers of a DNN and solve it using an Ensemble Density Propagation (EnDP) scheme. The EnDP approach allows us to propagate moments of the variational probability distribution across the layers of a Bayesian DNN, enabling the estimation of the mean and covariance of the predictive distribution at the output of the model. Our experiments using MNIST and CIFAR-10 datasets show a significant improvement in the robustness of the trained models to random noise and adversarial attacks.
Self-Compression in Bayesian Neural Networks
Nov 10, 2021

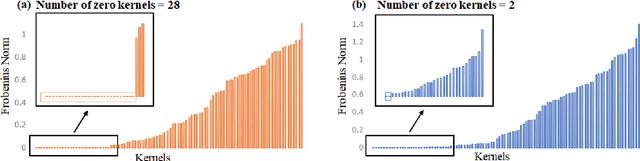
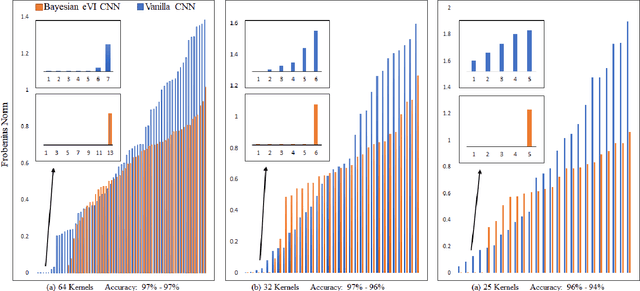
Machine learning models have achieved human-level performance on various tasks. This success comes at a high cost of computation and storage overhead, which makes machine learning algorithms difficult to deploy on edge devices. Typically, one has to partially sacrifice accuracy in favor of an increased performance quantified in terms of reduced memory usage and energy consumption. Current methods compress the networks by reducing the precision of the parameters or by eliminating redundant ones. In this paper, we propose a new insight into network compression through the Bayesian framework. We show that Bayesian neural networks automatically discover redundancy in model parameters, thus enabling self-compression, which is linked to the propagation of uncertainty through the layers of the network. Our experimental results show that the network architecture can be successfully compressed by deleting parameters identified by the network itself while retaining the same level of accuracy.
Dilated Inception U-Net for Brain Tumor Segmentation
Aug 15, 2021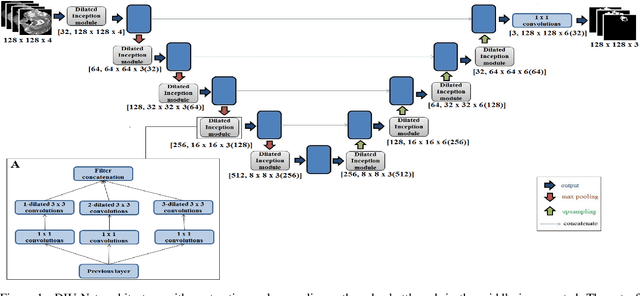
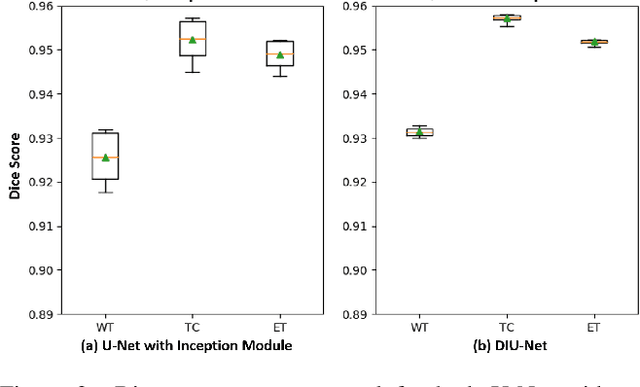
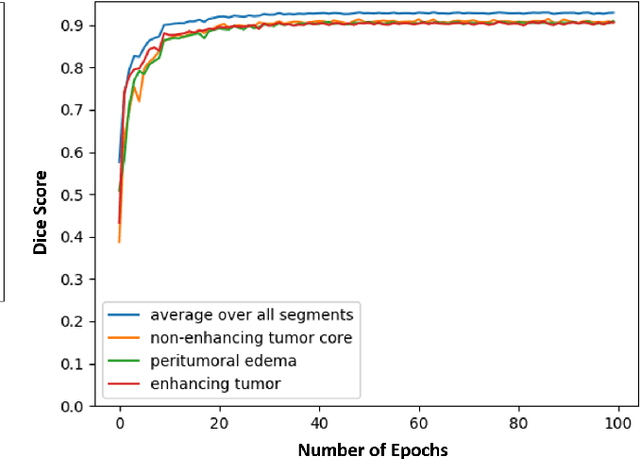
Magnetic resonance imaging (MRI) is routinely used for brain tumor diagnosis, treatment planning, and post-treatment surveillance. Recently, various models based on deep neural networks have been proposed for the pixel-level segmentation of tumors in brain MRIs. However, the structural variations, spatial dissimilarities, and intensity inhomogeneity in MRIs make segmentation a challenging task. We propose a new end-to-end brain tumor segmentation architecture based on U-Net that integrates Inception modules and dilated convolutions into its contracting and expanding paths. This allows us to extract local structural as well as global contextual information. We performed segmentation of glioma sub-regions, including tumor core, enhancing tumor, and whole tumor using Brain Tumor Segmentation (BraTS) 2018 dataset. Our proposed model performed significantly better than the state-of-the-art U-Net-based model ($p<0.05$) for tumor core and whole tumor segmentation.
Exploring Robustness of Neural Networks through Graph Measures
Jun 30, 2021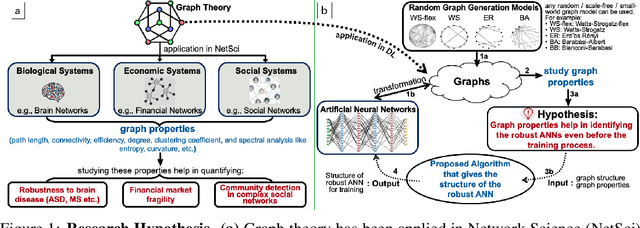
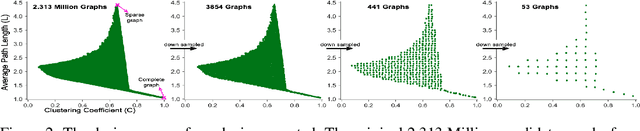
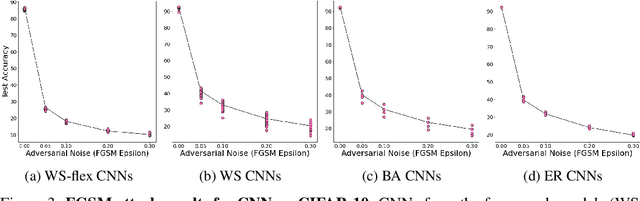
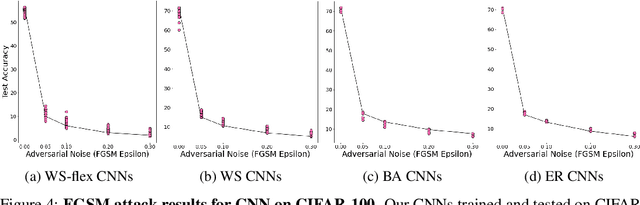
Motivated by graph theory, artificial neural networks (ANNs) are traditionally structured as layers of neurons (nodes), which learn useful information by the passage of data through interconnections (edges). In the machine learning realm, graph structures (i.e., neurons and connections) of ANNs have recently been explored using various graph-theoretic measures linked to their predictive performance. On the other hand, in network science (NetSci), certain graph measures including entropy and curvature are known to provide insight into the robustness and fragility of real-world networks. In this work, we use these graph measures to explore the robustness of various ANNs to adversarial attacks. To this end, we (1) explore the design space of inter-layer and intra-layers connectivity regimes of ANNs in the graph domain and record their predictive performance after training under different types of adversarial attacks, (2) use graph representations for both inter-layer and intra-layers connectivity regimes to calculate various graph-theoretic measures, including curvature and entropy, and (3) analyze the relationship between these graph measures and the adversarial performance of ANNs. We show that curvature and entropy, while operating in the graph domain, can quantify the robustness of ANNs without having to train these ANNs. Our results suggest that the real-world networks, including brain networks, financial networks, and social networks may provide important clues to the neural architecture search for robust ANNs. We propose a search strategy that efficiently finds robust ANNs amongst a set of well-performing ANNs without having a need to train all of these ANNs.