 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Scopeformer: Towards Scalable and Rich Feature Extraction for Intracranial Hemorrhage Detection
Feb 01, 2023The quality and richness of feature maps extracted by convolution neural networks (CNNs) and vision Transformers (ViTs) directly relate to the robust model performance. In medical computer vision, these information-rich features are crucial for detecting rare cases within large datasets. This work presents the "Scopeformer," a novel multi-CNN-ViT model for intracranial hemorrhage classification in computed tomography (CT) images. The Scopeformer architecture is scalable and modular, which allows utilizing various CNN architectures as the backbone with diversified output features and pre-training strategies. We propose effective feature projection methods to reduce redundancies among CNN-generated features and to control the input size of ViTs. Extensive experiments with various Scopeformer models show that the model performance is proportional to the number of convolutional blocks employed in the feature extractor. Using multiple strategies, including diversifying the pre-training paradigms for CNNs, different pre-training datasets, and style transfer techniques, we demonstrate an overall improvement in the model performance at various computational budgets. Later, we propose smaller compute-efficient Scopeformer versions with three different types of input and output ViT configurations. Efficient Scopeformers use four different pre-trained CNN architectures as feature extractors to increase feature richness. Our best Efficient Scopeformer model achieved an accuracy of 96.94\% and a weighted logarithmic loss of 0.083 with an eight times reduction in the number of trainable parameters compared to the base Scopeformer. Another version of the Efficient Scopeformer model further reduced the parameter space by almost 17 times with negligible performance reduction. Hybrid CNNs and ViTs might provide the desired feature richness for developing accurate medical computer vision models
Scopeformer: n-CNN-ViT Hybrid Model for Intracranial Hemorrhage Classification
Jul 07, 2021
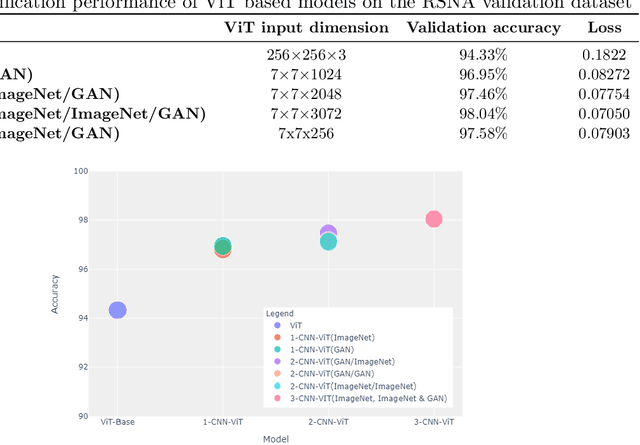
We propose a feature generator backbone composed of an ensemble of convolutional neuralnetworks (CNNs) to improve the recently emerging Vision Transformer (ViT) models. We tackled the RSNA intracranial hemorrhage classification problem, i.e., identifying various hemorrhage types from computed tomography (CT) slices. We show that by gradually stacking several feature maps extracted using multiple Xception CNNs, we can develop a feature-rich input for the ViT model. Our approach allowed the ViT model to pay attention to relevant features at multiple levels. Moreover, pretraining the n CNNs using various paradigms leads to a diverse feature set and further improves the performance of the proposed n-CNN-ViT. We achieved a test accuracy of 98.04% with a weighted logarithmic loss value of 0.0708. The proposed architecture is modular and scalable in both the number of CNNs used for feature extraction and the size of the ViT.