 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Mixture of Experts Foundation Model for Scanning Electron Microscopy Image Analysis
Apr 07, 2026Scanning Electron Microscopy (SEM) is indispensable in modern materials science, enabling high-resolution imaging across a wide range of structural, chemical, and functional investigations. However, SEM imaging remains constrained by task-specific models and labor-intensive acquisition processes that limit its scalability across diverse applications. Here, we introduce the first foundation model for SEM images, pretrained on a large corpus of multi-instrument, multi-condition scientific micrographs, enabling generalization across diverse material systems and imaging conditions. Leveraging a self-supervised transformer architecture, our model learns rich and transferable representations that can be fine-tuned or adapted to a wide range of downstream tasks. As a compelling demonstration, we focus on defocus-to-focus image translation-an essential yet underexplored challenge in automated microscopy pipelines. Our method not only restores focused detail from defocused inputs without paired supervision but also outperforms state-of-the-art techniques across multiple evaluation metrics. This work lays the groundwork for a new class of adaptable SEM models, accelerating materials discovery by bridging foundational representation learning with real-world imaging needs.
Hierarchy-Guided Multimodal Representation Learning for Taxonomic Inference
Mar 26, 2026Accurate biodiversity identification from large-scale field data is a foundational problem with direct impact on ecology, conservation, and environmental monitoring. In practice, the core task is taxonomic prediction - inferring order, family, genus, or species from imperfect inputs such as specimen images, DNA barcodes, or both. Existing multimodal methods often treat taxonomy as a flat label space and therefore fail to encode the hierarchical structure of biological classification, which is critical for robustness under noise and missing modalities. We present two end-to-end variants for hierarchy-aware multimodal learning: CLiBD-HiR, which introduces Hierarchical Information Regularization (HiR) to shape embedding geometry across taxonomic levels, yielding structured and noise-robust representations; and CLiBD-HiR-Fuse, which additionally trains a lightweight fusion predictor that supports image-only, DNA-only, or joint inference and is resilient to modality corruption. Across large-scale biodiversity benchmarks, our approach improves taxonomic classification accuracy by over 14 percent compared to strong multimodal baselines, with particularly large gains under partial and corrupted DNA conditions. These results highlight that explicitly encoding biological hierarchy, together with flexible fusion, is key for practical biodiversity foundation models.
Towards Source-Free Machine Unlearning
Aug 20, 2025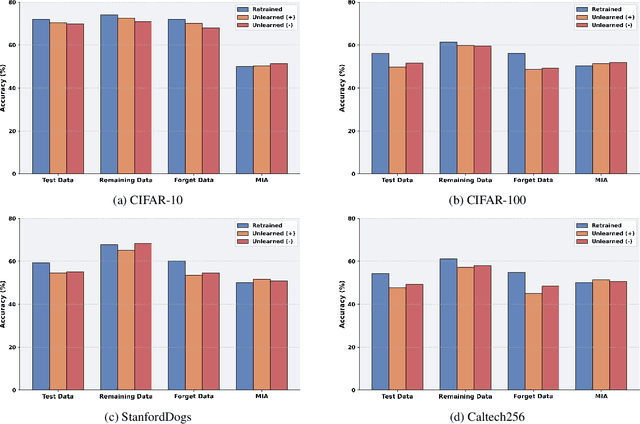
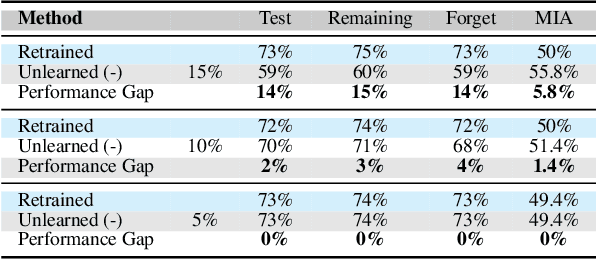
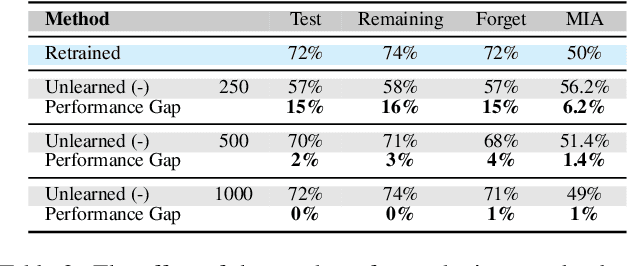
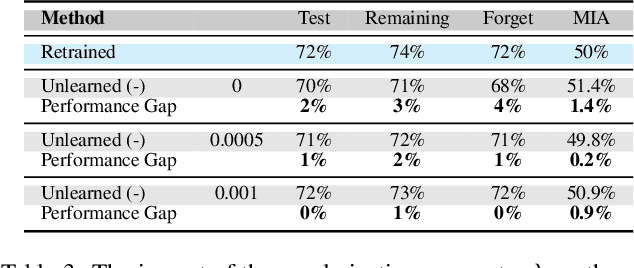
As machine learning becomes more pervasive and data privacy regulations evolve, the ability to remove private or copyrighted information from trained models is becoming an increasingly critical requirement. Existing unlearning methods often rely on the assumption of having access to the entire training dataset during the forgetting process. However, this assumption may not hold true in practical scenarios where the original training data may not be accessible, i.e., the source-free setting. To address this challenge, we focus on the source-free unlearning scenario, where an unlearning algorithm must be capable of removing specific data from a trained model without requiring access to the original training dataset. Building on recent work, we present a method that can estimate the Hessian of the unknown remaining training data, a crucial component required for efficient unlearning. Leveraging this estimation technique, our method enables efficient zero-shot unlearning while providing robust theoretical guarantees on the unlearning performance, while maintaining performance on the remaining data. Extensive experiments over a wide range of datasets verify the efficacy of our method.
A Certified Unlearning Approach without Access to Source Data
Jun 06, 2025
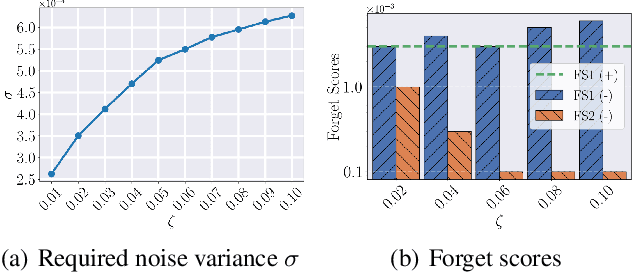
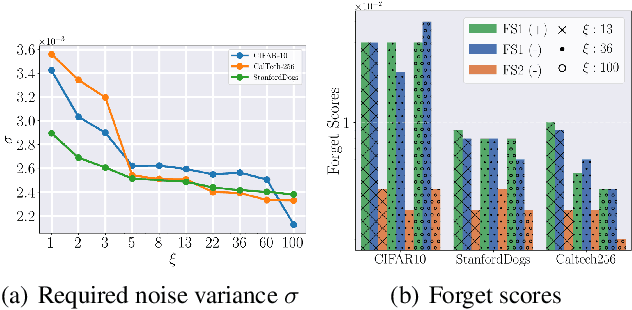
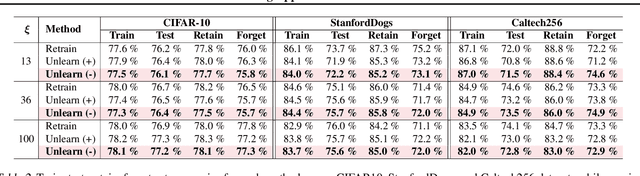
With the growing adoption of data privacy regulations, the ability to erase private or copyrighted information from trained models has become a crucial requirement. Traditional unlearning methods often assume access to the complete training dataset, which is unrealistic in scenarios where the source data is no longer available. To address this challenge, we propose a certified unlearning framework that enables effective data removal \final{without access to the original training data samples}. Our approach utilizes a surrogate dataset that approximates the statistical properties of the source data, allowing for controlled noise scaling based on the statistical distance between the two. \updated{While our theoretical guarantees assume knowledge of the exact statistical distance, practical implementations typically approximate this distance, resulting in potentially weaker but still meaningful privacy guarantees.} This ensures strong guarantees on the model's behavior post-unlearning while maintaining its overall utility. We establish theoretical bounds, introduce practical noise calibration techniques, and validate our method through extensive experiments on both synthetic and real-world datasets. The results demonstrate the effectiveness and reliability of our approach in privacy-sensitive settings.
FLASH: Federated Learning Across Simultaneous Heterogeneities
Feb 13, 2024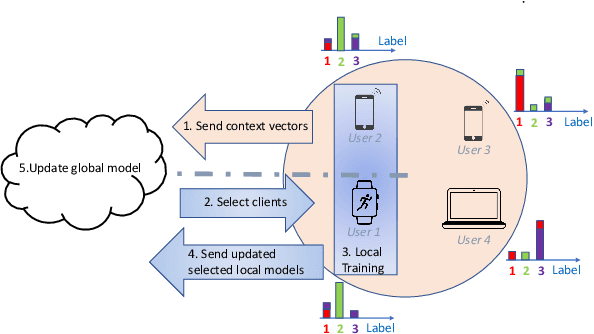


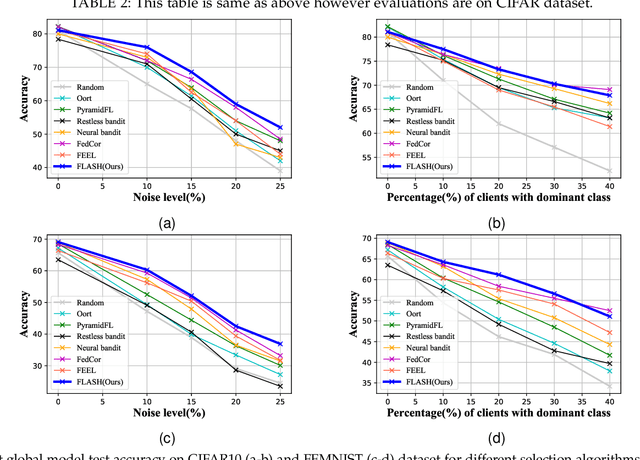
The key premise of federated learning (FL) is to train ML models across a diverse set of data-owners (clients), without exchanging local data. An overarching challenge to this date is client heterogeneity, which may arise not only from variations in data distribution, but also in data quality, as well as compute/communication latency. An integrated view of these diverse and concurrent sources of heterogeneity is critical; for instance, low-latency clients may have poor data quality, and vice versa. In this work, we propose FLASH(Federated Learning Across Simultaneous Heterogeneities), a lightweight and flexible client selection algorithm that outperforms state-of-the-art FL frameworks under extensive sources of heterogeneity, by trading-off the statistical information associated with the client's data quality, data distribution, and latency. FLASH is the first method, to our knowledge, for handling all these heterogeneities in a unified manner. To do so, FLASH models the learning dynamics through contextual multi-armed bandits (CMAB) and dynamically selects the most promising clients. Through extensive experiments, we demonstrate that FLASH achieves substantial and consistent improvements over state-of-the-art baselines -- as much as 10% in absolute accuracy -- thanks to its unified approach. Importantly, FLASH also outperforms federated aggregation methods that are designed to handle highly heterogeneous settings and even enjoys a performance boost when integrated with them.
Plug-and-Play Transformer Modules for Test-Time Adaptation
Jan 10, 2024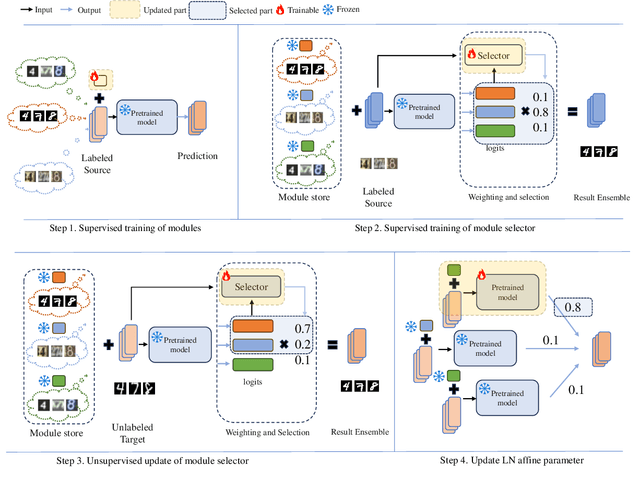

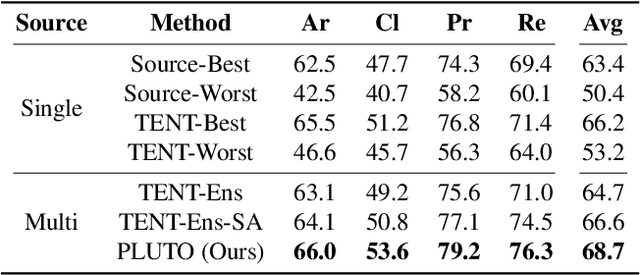
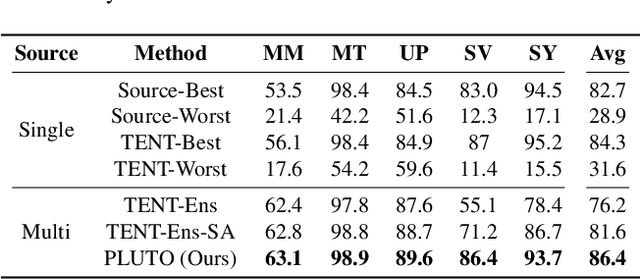
Parameter-efficient tuning (PET) methods such as LoRA, Adapter, and Visual Prompt Tuning (VPT) have found success in enabling adaptation to new domains by tuning small modules within a transformer model. However, the number of domains encountered during test time can be very large, and the data is usually unlabeled. Thus, adaptation to new domains is challenging; it is also impractical to generate customized tuned modules for each such domain. Toward addressing these challenges, this work introduces PLUTO: a Plug-and-pLay modUlar Test-time domain adaptatiOn strategy. We pre-train a large set of modules, each specialized for different source domains, effectively creating a ``module store''. Given a target domain with few-shot unlabeled data, we introduce an unsupervised test-time adaptation (TTA) method to (1) select a sparse subset of relevant modules from this store and (2) create a weighted combination of selected modules without tuning their weights. This plug-and-play nature enables us to harness multiple most-relevant source domains in a single inference call. Comprehensive evaluations demonstrate that PLUTO uniformly outperforms alternative TTA methods and that selecting $\leq$5 modules suffice to extract most of the benefit. At a high level, our method equips pre-trained transformers with the capability to dynamically adapt to new domains, motivating a new paradigm for efficient and scalable domain adaptation.
MeTA: Multi-source Test Time Adaptation
Jan 04, 2024



Test time adaptation is the process of adapting, in an unsupervised manner, a pre-trained source model to each incoming batch of the test data (i.e., without requiring a substantial portion of the test data to be available, as in traditional domain adaptation) and without access to the source data. Since it works with each batch of test data, it is well-suited for dynamic environments where decisions need to be made as the data is streaming in. Current test time adaptation methods are primarily focused on a single source model. We propose the first completely unsupervised Multi-source Test Time Adaptation (MeTA) framework that handles multiple source models and optimally combines them to adapt to the test data. MeTA has two distinguishing features. First, it efficiently obtains the optimal combination weights to combine the source models to adapt to the test data distribution. Second, it identifies which of the source model parameters to update so that only the model which is most correlated to the target data is adapted, leaving the less correlated ones untouched; this mitigates the issue of "forgetting" the source model parameters by focusing only on the source model that exhibits the strongest correlation with the test batch distribution. Experiments on diverse datasets demonstrate that the combination of multiple source models does at least as well as the best source (with hindsight knowledge), and performance does not degrade as the test data distribution changes over time (robust to forgetting).
Effective Restoration of Source Knowledge in Continual Test Time Adaptation
Nov 08, 2023Traditional test-time adaptation (TTA) methods face significant challenges in adapting to dynamic environments characterized by continuously changing long-term target distributions. These challenges primarily stem from two factors: catastrophic forgetting of previously learned valuable source knowledge and gradual error accumulation caused by miscalibrated pseudo labels. To address these issues, this paper introduces an unsupervised domain change detection method that is capable of identifying domain shifts in dynamic environments and subsequently resets the model parameters to the original source pre-trained values. By restoring the knowledge from the source, it effectively corrects the negative consequences arising from the gradual deterioration of model parameters caused by ongoing shifts in the domain. Our method involves progressive estimation of global batch-norm statistics specific to each domain, while keeping track of changes in the statistics triggered by domain shifts. Importantly, our method is agnostic to the specific adaptation technique employed and thus, can be incorporated to existing TTA methods to enhance their performance in dynamic environments. We perform extensive experiments on benchmark datasets to demonstrate the superior performance of our method compared to state-of-the-art adaptation methods.
SUMMIT: Source-Free Adaptation of Uni-Modal Models to Multi-Modal Targets
Aug 23, 2023



Scene understanding using multi-modal data is necessary in many applications, e.g., autonomous navigation. To achieve this in a variety of situations, existing models must be able to adapt to shifting data distributions without arduous data annotation. Current approaches assume that the source data is available during adaptation and that the source consists of paired multi-modal data. Both these assumptions may be problematic for many applications. Source data may not be available due to privacy, security, or economic concerns. Assuming the existence of paired multi-modal data for training also entails significant data collection costs and fails to take advantage of widely available freely distributed pre-trained uni-modal models. In this work, we relax both of these assumptions by addressing the problem of adapting a set of models trained independently on uni-modal data to a target domain consisting of unlabeled multi-modal data, without having access to the original source dataset. Our proposed approach solves this problem through a switching framework which automatically chooses between two complementary methods of cross-modal pseudo-label fusion -- agreement filtering and entropy weighting -- based on the estimated domain gap. We demonstrate our work on the semantic segmentation problem. Experiments across seven challenging adaptation scenarios verify the efficacy of our approach, achieving results comparable to, and in some cases outperforming, methods which assume access to source data. Our method achieves an improvement in mIoU of up to 12% over competing baselines. Our code is publicly available at https://github.com/csimo005/SUMMIT.
Cross-Modal Knowledge Transfer Without Task-Relevant Source Data
Sep 08, 2022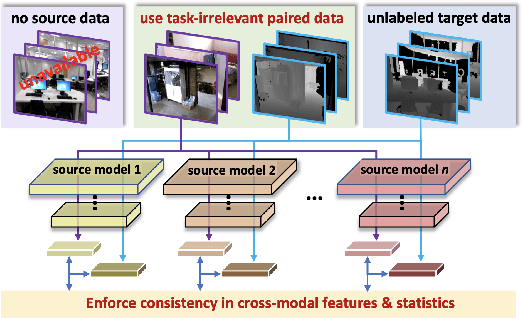

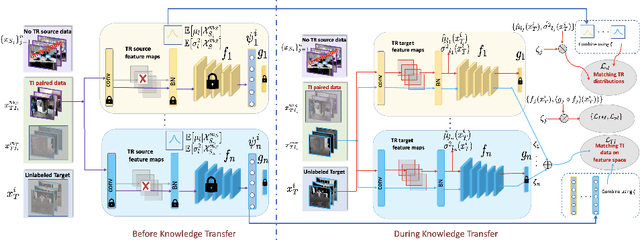

Cost-effective depth and infrared sensors as alternatives to usual RGB sensors are now a reality, and have some advantages over RGB in domains like autonomous navigation and remote sensing. As such, building computer vision and deep learning systems for depth and infrared data are crucial. However, large labeled datasets for these modalities are still lacking. In such cases, transferring knowledge from a neural network trained on a well-labeled large dataset in the source modality (RGB) to a neural network that works on a target modality (depth, infrared, etc.) is of great value. For reasons like memory and privacy, it may not be possible to access the source data, and knowledge transfer needs to work with only the source models. We describe an effective solution, SOCKET: SOurce-free Cross-modal KnowledgE Transfer for this challenging task of transferring knowledge from one source modality to a different target modality without access to task-relevant source data. The framework reduces the modality gap using paired task-irrelevant data, as well as by matching the mean and variance of the target features with the batch-norm statistics that are present in the source models. We show through extensive experiments that our method significantly outperforms existing source-free methods for classification tasks which do not account for the modality gap.