 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Inversion Attacks on Parameter-Efficient Fine-Tuning
Jun 04, 2025Federated learning (FL) allows multiple data-owners to collaboratively train machine learning models by exchanging local gradients, while keeping their private data on-device. To simultaneously enhance privacy and training efficiency, recently parameter-efficient fine-tuning (PEFT) of large-scale pretrained models has gained substantial attention in FL. While keeping a pretrained (backbone) model frozen, each user fine-tunes only a few lightweight modules to be used in conjunction, to fit specific downstream applications. Accordingly, only the gradients with respect to these lightweight modules are shared with the server. In this work, we investigate how the privacy of the fine-tuning data of the users can be compromised via a malicious design of the pretrained model and trainable adapter modules. We demonstrate gradient inversion attacks on a popular PEFT mechanism, the adapter, which allow an attacker to reconstruct local data samples of a target user, using only the accessible adapter gradients. Via extensive experiments, we demonstrate that a large batch of fine-tuning images can be retrieved with high fidelity. Our attack highlights the need for privacy-preserving mechanisms for PEFT, while opening up several future directions. Our code is available at https://github.com/info-ucr/PEFTLeak.
FLASH: Federated Learning Across Simultaneous Heterogeneities
Feb 13, 2024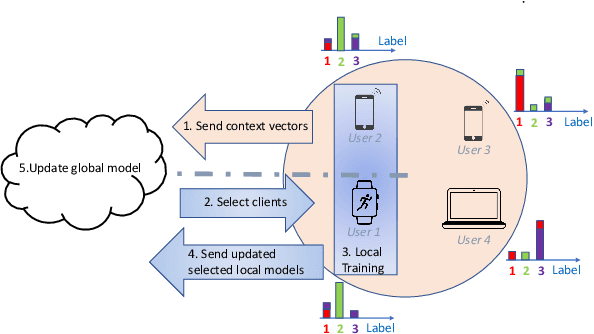


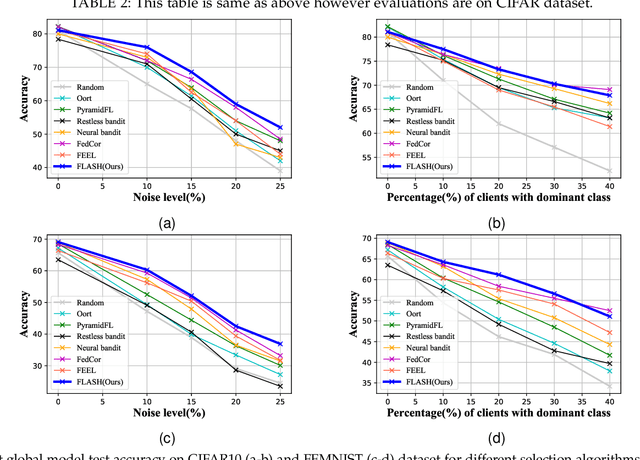
The key premise of federated learning (FL) is to train ML models across a diverse set of data-owners (clients), without exchanging local data. An overarching challenge to this date is client heterogeneity, which may arise not only from variations in data distribution, but also in data quality, as well as compute/communication latency. An integrated view of these diverse and concurrent sources of heterogeneity is critical; for instance, low-latency clients may have poor data quality, and vice versa. In this work, we propose FLASH(Federated Learning Across Simultaneous Heterogeneities), a lightweight and flexible client selection algorithm that outperforms state-of-the-art FL frameworks under extensive sources of heterogeneity, by trading-off the statistical information associated with the client's data quality, data distribution, and latency. FLASH is the first method, to our knowledge, for handling all these heterogeneities in a unified manner. To do so, FLASH models the learning dynamics through contextual multi-armed bandits (CMAB) and dynamically selects the most promising clients. Through extensive experiments, we demonstrate that FLASH achieves substantial and consistent improvements over state-of-the-art baselines -- as much as 10% in absolute accuracy -- thanks to its unified approach. Importantly, FLASH also outperforms federated aggregation methods that are designed to handle highly heterogeneous settings and even enjoys a performance boost when integrated with them.
Plug-and-Play Transformer Modules for Test-Time Adaptation
Jan 10, 2024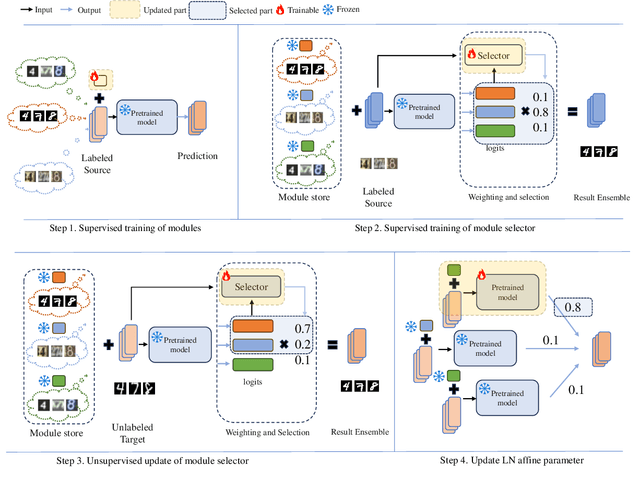

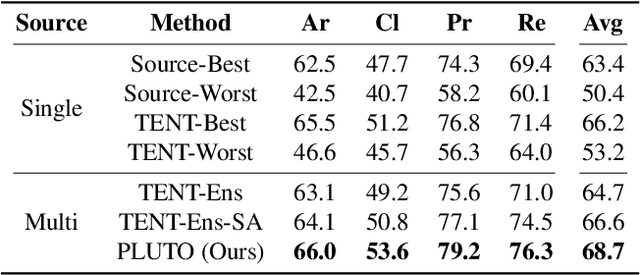
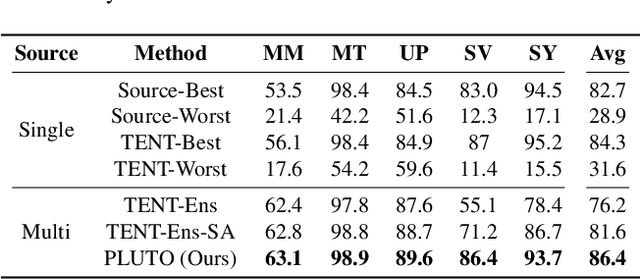
Parameter-efficient tuning (PET) methods such as LoRA, Adapter, and Visual Prompt Tuning (VPT) have found success in enabling adaptation to new domains by tuning small modules within a transformer model. However, the number of domains encountered during test time can be very large, and the data is usually unlabeled. Thus, adaptation to new domains is challenging; it is also impractical to generate customized tuned modules for each such domain. Toward addressing these challenges, this work introduces PLUTO: a Plug-and-pLay modUlar Test-time domain adaptatiOn strategy. We pre-train a large set of modules, each specialized for different source domains, effectively creating a ``module store''. Given a target domain with few-shot unlabeled data, we introduce an unsupervised test-time adaptation (TTA) method to (1) select a sparse subset of relevant modules from this store and (2) create a weighted combination of selected modules without tuning their weights. This plug-and-play nature enables us to harness multiple most-relevant source domains in a single inference call. Comprehensive evaluations demonstrate that PLUTO uniformly outperforms alternative TTA methods and that selecting $\leq$5 modules suffice to extract most of the benefit. At a high level, our method equips pre-trained transformers with the capability to dynamically adapt to new domains, motivating a new paradigm for efficient and scalable domain adaptation.
Leveraging Local Patch Differences in Multi-Object Scenes for Generative Adversarial Attacks
Oct 03, 2022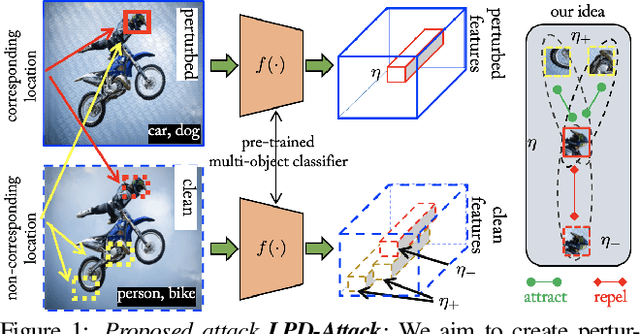

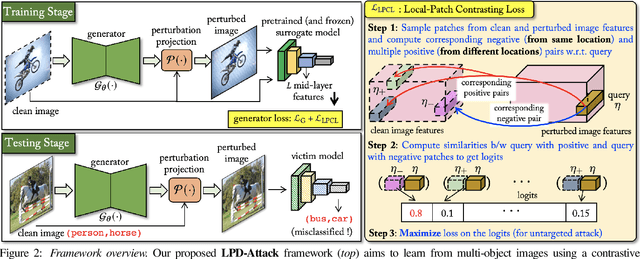

State-of-the-art generative model-based attacks against image classifiers overwhelmingly focus on single-object (i.e., single dominant object) images. Different from such settings, we tackle a more practical problem of generating adversarial perturbations using multi-object (i.e., multiple dominant objects) images as they are representative of most real-world scenes. Our goal is to design an attack strategy that can learn from such natural scenes by leveraging the local patch differences that occur inherently in such images (e.g. difference between the local patch on the object `person' and the object `bike' in a traffic scene). Our key idea is to misclassify an adversarial multi-object image by confusing the victim classifier for each local patch in the image. Based on this, we propose a novel generative attack (called Local Patch Difference or LPD-Attack) where a novel contrastive loss function uses the aforesaid local differences in feature space of multi-object scenes to optimize the perturbation generator. Through various experiments across diverse victim convolutional neural networks, we show that our approach outperforms baseline generative attacks with highly transferable perturbations when evaluated under different white-box and black-box settings.
GAMA: Generative Adversarial Multi-Object Scene Attacks
Sep 20, 2022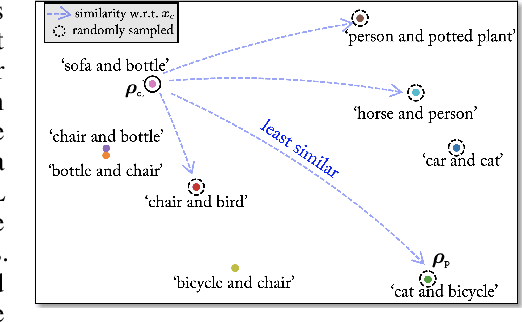

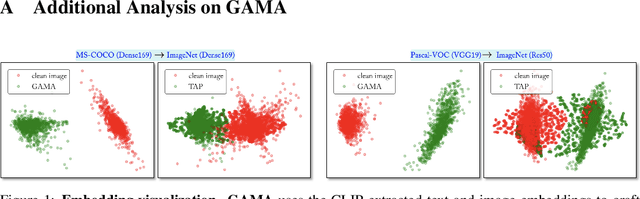
The majority of methods for crafting adversarial attacks have focused on scenes with a single dominant object (e.g., images from ImageNet). On the other hand, natural scenes include multiple dominant objects that are semantically related. Thus, it is crucial to explore designing attack strategies that look beyond learning on single-object scenes or attack single-object victim classifiers. Due to their inherent property of strong transferability of perturbations to unknown models, this paper presents the first approach of using generative models for adversarial attacks on multi-object scenes. In order to represent the relationships between different objects in the input scene, we leverage upon the open-sourced pre-trained vision-language model CLIP (Contrastive Language-Image Pre-training), with the motivation to exploit the encoded semantics in the language space along with the visual space. We call this attack approach Generative Adversarial Multi-object scene Attacks (GAMA). GAMA demonstrates the utility of the CLIP model as an attacker's tool to train formidable perturbation generators for multi-object scenes. Using the joint image-text features to train the generator, we show that GAMA can craft potent transferable perturbations in order to fool victim classifiers in various attack settings. For example, GAMA triggers ~16% more misclassification than state-of-the-art generative approaches in black-box settings where both the classifier architecture and data distribution of the attacker are different from the victim. Our code will be made publicly available soon.
Zero-Query Transfer Attacks on Context-Aware Object Detectors
Mar 29, 2022

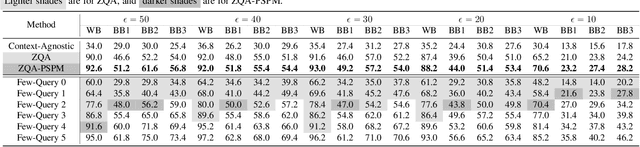

Adversarial attacks perturb images such that a deep neural network produces incorrect classification results. A promising approach to defend against adversarial attacks on natural multi-object scenes is to impose a context-consistency check, wherein, if the detected objects are not consistent with an appropriately defined context, then an attack is suspected. Stronger attacks are needed to fool such context-aware detectors. We present the first approach for generating context-consistent adversarial attacks that can evade the context-consistency check of black-box object detectors operating on complex, natural scenes. Unlike many black-box attacks that perform repeated attempts and open themselves to detection, we assume a "zero-query" setting, where the attacker has no knowledge of the classification decisions of the victim system. First, we derive multiple attack plans that assign incorrect labels to victim objects in a context-consistent manner. Then we design and use a novel data structure that we call the perturbation success probability matrix, which enables us to filter the attack plans and choose the one most likely to succeed. This final attack plan is implemented using a perturbation-bounded adversarial attack algorithm. We compare our zero-query attack against a few-query scheme that repeatedly checks if the victim system is fooled. We also compare against state-of-the-art context-agnostic attacks. Against a context-aware defense, the fooling rate of our zero-query approach is significantly higher than context-agnostic approaches and higher than that achievable with up to three rounds of the few-query scheme.
Context-Aware Transfer Attacks for Object Detection
Dec 06, 2021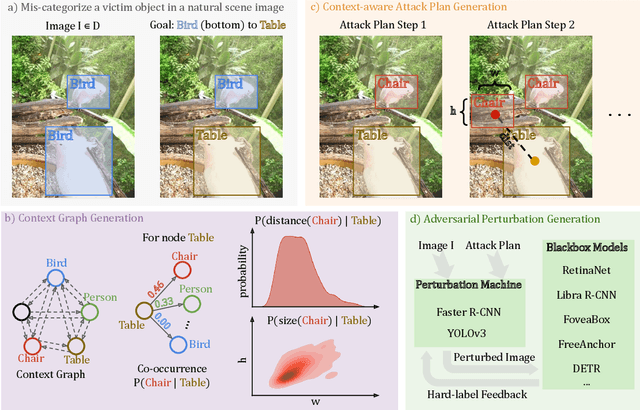
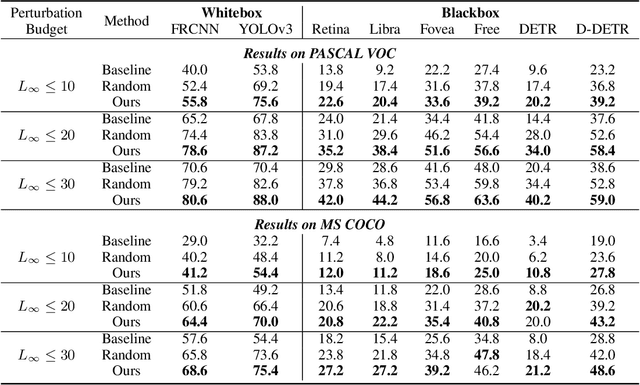

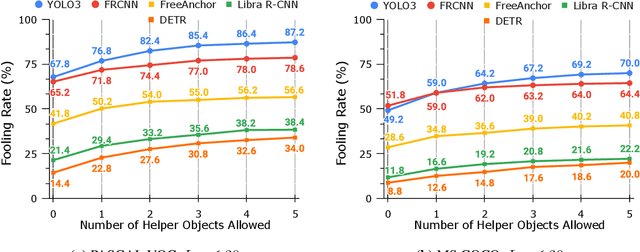
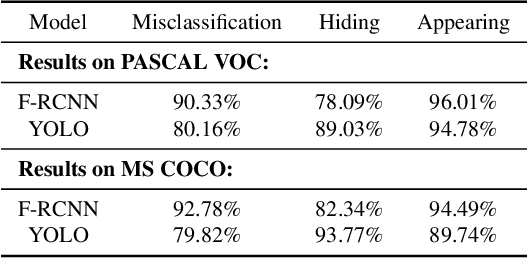
Blackbox transfer attacks for image classifiers have been extensively studied in recent years. In contrast, little progress has been made on transfer attacks for object detectors. Object detectors take a holistic view of the image and the detection of one object (or lack thereof) often depends on other objects in the scene. This makes such detectors inherently context-aware and adversarial attacks in this space are more challenging than those targeting image classifiers. In this paper, we present a new approach to generate context-aware attacks for object detectors. We show that by using co-occurrence of objects and their relative locations and sizes as context information, we can successfully generate targeted mis-categorization attacks that achieve higher transfer success rates on blackbox object detectors than the state-of-the-art. We test our approach on a variety of object detectors with images from PASCAL VOC and MS COCO datasets and demonstrate up to $20$ percentage points improvement in performance compared to the other state-of-the-art methods.
ADC: Adversarial attacks against object Detection that evade Context consistency checks
Oct 24, 2021

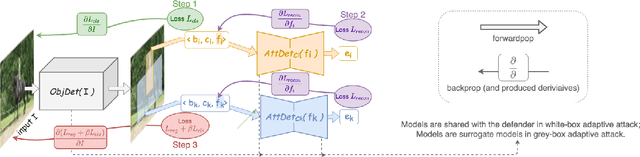

Deep Neural Networks (DNNs) have been shown to be vulnerable to adversarial examples, which are slightly perturbed input images which lead DNNs to make wrong predictions. To protect from such examples, various defense strategies have been proposed. A very recent defense strategy for detecting adversarial examples, that has been shown to be robust to current attacks, is to check for intrinsic context consistencies in the input data, where context refers to various relationships (e.g., object-to-object co-occurrence relationships) in images. In this paper, we show that even context consistency checks can be brittle to properly crafted adversarial examples and to the best of our knowledge, we are the first to do so. Specifically, we propose an adaptive framework to generate examples that subvert such defenses, namely, Adversarial attacks against object Detection that evade Context consistency checks (ADC). In ADC, we formulate a joint optimization problem which has two attack goals, viz., (i) fooling the object detector and (ii) evading the context consistency check system, at the same time. Experiments on both PASCAL VOC and MS COCO datasets show that examples generated with ADC fool the object detector with a success rate of over 85% in most cases, and at the same time evade the recently proposed context consistency checks, with a bypassing rate of over 80% in most cases. Our results suggest that how to robustly model context and check its consistency, is still an open problem.
Exploiting Multi-Object Relationships for Detecting Adversarial Attacks in Complex Scenes
Aug 19, 2021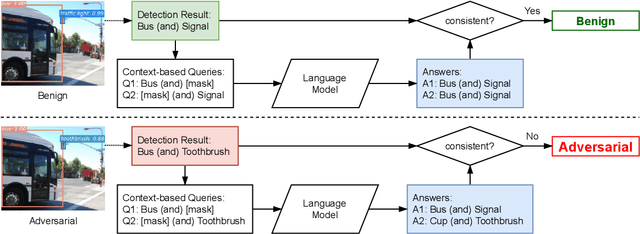
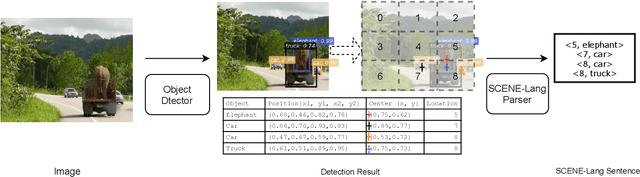

Vision systems that deploy Deep Neural Networks (DNNs) are known to be vulnerable to adversarial examples. Recent research has shown that checking the intrinsic consistencies in the input data is a promising way to detect adversarial attacks (e.g., by checking the object co-occurrence relationships in complex scenes). However, existing approaches are tied to specific models and do not offer generalizability. Motivated by the observation that language descriptions of natural scene images have already captured the object co-occurrence relationships that can be learned by a language model, we develop a novel approach to perform context consistency checks using such language models. The distinguishing aspect of our approach is that it is independent of the deployed object detector and yet offers very high accuracy in terms of detecting adversarial examples in practical scenes with multiple objects.
Measurement-driven Security Analysis of Imperceptible Impersonation Attacks
Aug 26, 2020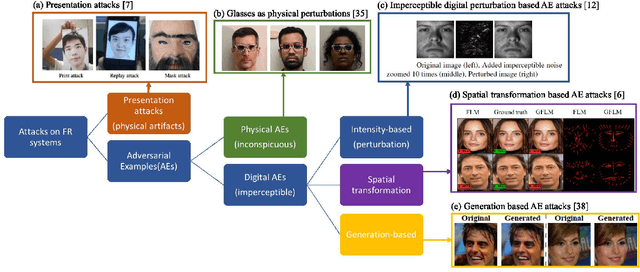



The emergence of Internet of Things (IoT) brings about new security challenges at the intersection of cyber and physical spaces. One prime example is the vulnerability of Face Recognition (FR) based access control in IoT systems. While previous research has shown that Deep Neural Network(DNN)-based FR systems (FRS) are potentially susceptible to imperceptible impersonation attacks, the potency of such attacks in a wide set of scenarios has not been thoroughly investigated. In this paper, we present the first systematic, wide-ranging measurement study of the exploitability of DNN-based FR systems using a large scale dataset. We find that arbitrary impersonation attacks, wherein an arbitrary attacker impersonates an arbitrary target, are hard if imperceptibility is an auxiliary goal. Specifically, we show that factors such as skin color, gender, and age, impact the ability to carry out an attack on a specific target victim, to different extents. We also study the feasibility of constructing universal attacks that are robust to different poses or views of the attacker's face. Our results show that finding a universal perturbation is a much harder problem from the attacker's perspective. Finally, we find that the perturbed images do not generalize well across different DNN models. This suggests security countermeasures that can dramatically reduce the exploitability of DNN-based FR systems.