 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAPLE: Latent Multi-Agent Play for End-to-End Autonomous Driving
May 13, 2026Vision-language-action (VLA) models are effective as end-to-end motion planners, but can be brittle when evaluated in closed-loop settings due to being trained under traditional imitation learning framework. Existing closed-loop supervision approaches lack scalability and fail to completely model a reactive environment. We propose MAPLE, a novel framework for reactive, multi-agent rollout of a dynamic driving scenario in the latent space of the VLA model. The ego vehicle and nearby traffic agents are independently controlled over multi-step horizons, while being reactive to other agents in the scene, enabling closed-loop training. MAPLE consists of two training stages: (1) supervised fine-tuning on the latent rollouts based on ground-truth trajectories, followed by (2) reinforcement learning with global and agent -specific rewards that encourage safety, progress, and interaction realism. We further propose diversity rewards that encourage the model to generate planning behaviors that may not be present in logged driving data. Notably, our closed-loop training framework is scalable and does not require external simulators, which can be computationally expensive to run and have limited visual fidelity to the real-world. MAPLE achieves state-of-the-art driving performance on Bench2Drive and demonstrates scalable, closed-loop multi-agent play for robust E2E autonomous driving systems.
Generative Scenario Rollouts for End-to-End Autonomous Driving
Jan 16, 2026Vision-Language-Action (VLA) models are emerging as highly effective planning models for end-to-end autonomous driving systems. However, current works mostly rely on imitation learning from sparse trajectory annotations and under-utilize their potential as generative models. We propose Generative Scenario Rollouts (GeRo), a plug-and-play framework for VLA models that jointly performs planning and generation of language-grounded future traffic scenes through an autoregressive rollout strategy. First, a VLA model is trained to encode ego vehicle and agent dynamics into latent tokens under supervision from planning, motion, and language tasks, facilitating text-aligned generation. Next, GeRo performs language-conditioned autoregressive generation. Given multi-view images, a scenario description, and ego-action questions, it generates future latent tokens and textual responses to guide long-horizon rollouts. A rollout-consistency loss stabilizes predictions using ground truth or pseudo-labels, mitigating drift and preserving text-action alignment. This design enables GeRo to perform temporally consistent, language-grounded rollouts that support long-horizon reasoning and multi-agent planning. On Bench2Drive, GeRo improves driving score and success rate by +15.7 and +26.2, respectively. By integrating reinforcement learning with generative rollouts, GeRo achieves state-of-the-art closed-loop and open-loop performance, demonstrating strong zero-shot robustness. These results highlight the promise of generative, language-conditioned reasoning as a foundation for safer and more interpretable end-to-end autonomous driving.
Distilling Multi-modal Large Language Models for Autonomous Driving
Jan 16, 2025
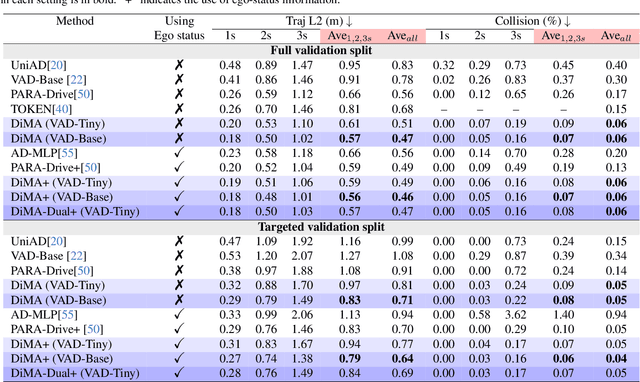

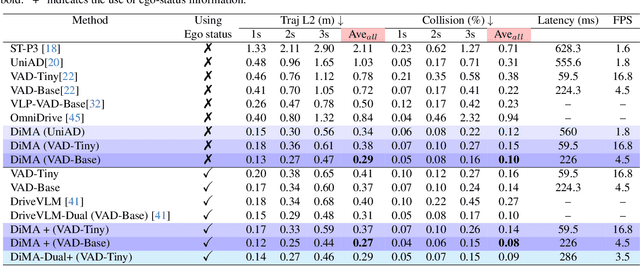
Autonomous driving demands safe motion planning, especially in critical "long-tail" scenarios. Recent end-to-end autonomous driving systems leverage large language models (LLMs) as planners to improve generalizability to rare events. However, using LLMs at test time introduces high computational costs. To address this, we propose DiMA, an end-to-end autonomous driving system that maintains the efficiency of an LLM-free (or vision-based) planner while leveraging the world knowledge of an LLM. DiMA distills the information from a multi-modal LLM to a vision-based end-to-end planner through a set of specially designed surrogate tasks. Under a joint training strategy, a scene encoder common to both networks produces structured representations that are semantically grounded as well as aligned to the final planning objective. Notably, the LLM is optional at inference, enabling robust planning without compromising on efficiency. Training with DiMA results in a 37% reduction in the L2 trajectory error and an 80% reduction in the collision rate of the vision-based planner, as well as a 44% trajectory error reduction in longtail scenarios. DiMA also achieves state-of-the-art performance on the nuScenes planning benchmark.
Equivariant Spatio-Temporal Self-Supervision for LiDAR Object Detection
Apr 17, 2024



Popular representation learning methods encourage feature invariance under transformations applied at the input. However, in 3D perception tasks like object localization and segmentation, outputs are naturally equivariant to some transformations, such as rotation. Using pre-training loss functions that encourage equivariance of features under certain transformations provides a strong self-supervision signal while also retaining information of geometric relationships between transformed feature representations. This can enable improved performance in downstream tasks that are equivariant to such transformations. In this paper, we propose a spatio-temporal equivariant learning framework by considering both spatial and temporal augmentations jointly. Our experiments show that the best performance arises with a pre-training approach that encourages equivariance to translation, scaling, and flip, rotation and scene flow. For spatial augmentations, we find that depending on the transformation, either a contrastive objective or an equivariance-by-classification objective yields best results. To leverage real-world object deformations and motion, we consider sequential LiDAR scene pairs and develop a novel 3D scene flow-based equivariance objective that leads to improved performance overall. We show our pre-training method for 3D object detection which outperforms existing equivariant and invariant approaches in many settings.
Multimodal 3D Object Detection on Unseen Domains
Apr 17, 2024LiDAR datasets for autonomous driving exhibit biases in properties such as point cloud density, range, and object dimensions. As a result, object detection networks trained and evaluated in different environments often experience performance degradation. Domain adaptation approaches assume access to unannotated samples from the test distribution to address this problem. However, in the real world, the exact conditions of deployment and access to samples representative of the test dataset may be unavailable while training. We argue that the more realistic and challenging formulation is to require robustness in performance to unseen target domains. We propose to address this problem in a two-pronged manner. First, we leverage paired LiDAR-image data present in most autonomous driving datasets to perform multimodal object detection. We suggest that working with multimodal features by leveraging both images and LiDAR point clouds for scene understanding tasks results in object detectors more robust to unseen domain shifts. Second, we train a 3D object detector to learn multimodal object features across different distributions and promote feature invariance across these source domains to improve generalizability to unseen target domains. To this end, we propose CLIX$^\text{3D}$, a multimodal fusion and supervised contrastive learning framework for 3D object detection that performs alignment of object features from same-class samples of different domains while pushing the features from different classes apart. We show that CLIX$^\text{3D}$ yields state-of-the-art domain generalization performance under multiple dataset shifts.
CLIP goes 3D: Leveraging Prompt Tuning for Language Grounded 3D Recognition
Apr 04, 2023



Vision-Language models like CLIP have been widely adopted for various tasks due to their impressive zero-shot capabilities. However, CLIP is not suitable for extracting 3D geometric features as it was trained on only images and text by natural language supervision. We work on addressing this limitation and propose a new framework termed CG3D (CLIP Goes 3D) where a 3D encoder is learned to exhibit zero-shot capabilities. CG3D is trained using triplets of pointclouds, corresponding rendered 2D images, and texts using natural language supervision. To align the features in a multimodal embedding space, we utilize contrastive loss on 3D features obtained from the 3D encoder, as well as visual and text features extracted from CLIP. We note that the natural images used to train CLIP and the rendered 2D images in CG3D have a distribution shift. Attempting to train the visual and text encoder to account for this shift results in catastrophic forgetting and a notable decrease in performance. To solve this, we employ prompt tuning and introduce trainable parameters in the input space to shift CLIP towards the 3D pre-training dataset utilized in CG3D. We extensively test our pre-trained CG3D framework and demonstrate its impressive capabilities in zero-shot, open scene understanding, and retrieval tasks. Further, it also serves as strong starting weights for fine-tuning in downstream 3D recognition tasks.
Attentive Prototypes for Source-free Unsupervised Domain Adaptive 3D Object Detection
Dec 01, 2021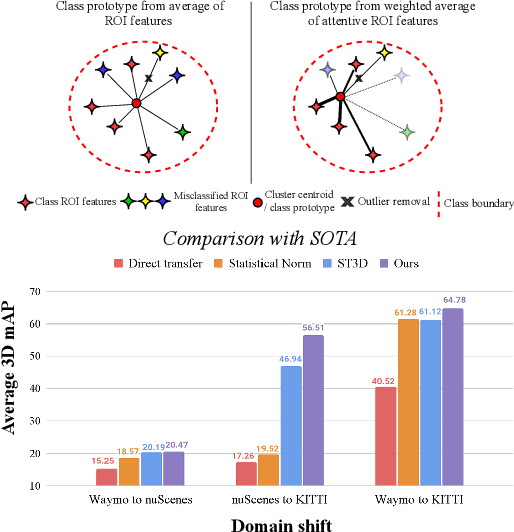
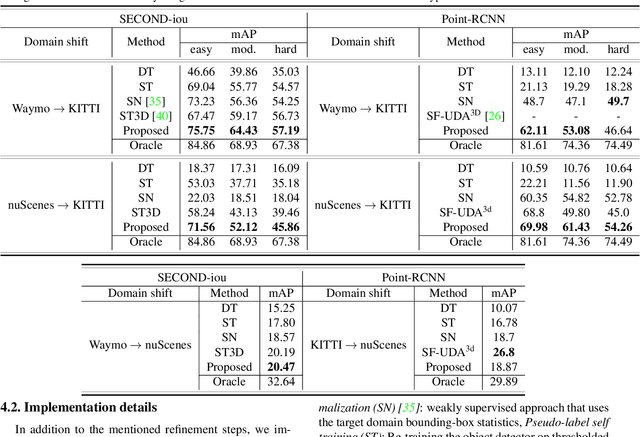
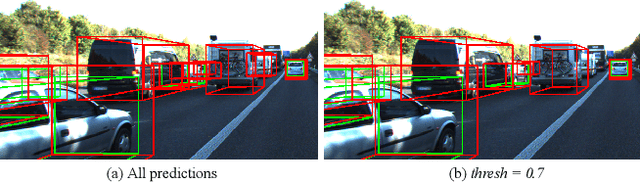
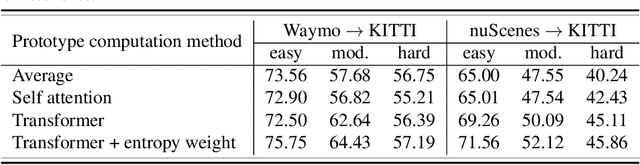
3D object detection networks tend to be biased towards the data they are trained on. Evaluation on datasets captured in different locations, conditions or sensors than that of the training (source) data results in a drop in model performance due to the gap in distribution with the test (or target) data. Current methods for domain adaptation either assume access to source data during training, which may not be available due to privacy or memory concerns, or require a sequence of lidar frames as an input. We propose a single-frame approach for source-free, unsupervised domain adaptation of lidar-based 3D object detectors that uses class prototypes to mitigate the effect pseudo-label noise. Addressing the limitations of traditional feature aggregation methods for prototype computation in the presence of noisy labels, we utilize a transformer module to identify outlier ROI's that correspond to incorrect, over-confident annotations, and compute an attentive class prototype. Under an iterative training strategy, the losses associated with noisy pseudo labels are down-weighed and thus refined in the process of self-training. To validate the effectiveness of our proposed approach, we examine the domain shift associated with networks trained on large, label-rich datasets (such as the Waymo Open Dataset and nuScenes) and evaluate on smaller, label-poor datasets (such as KITTI) and vice-versa. We demonstrate our approach on two recent object detectors and achieve results that out-perform the other domain adaptation works.
Uncertainty-aware Mean Teacher for Source-free Unsupervised Domain Adaptive 3D Object Detection
Sep 29, 2021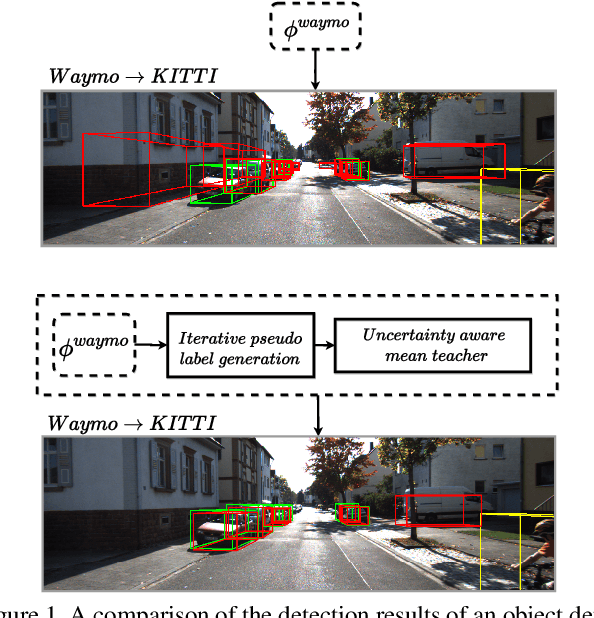
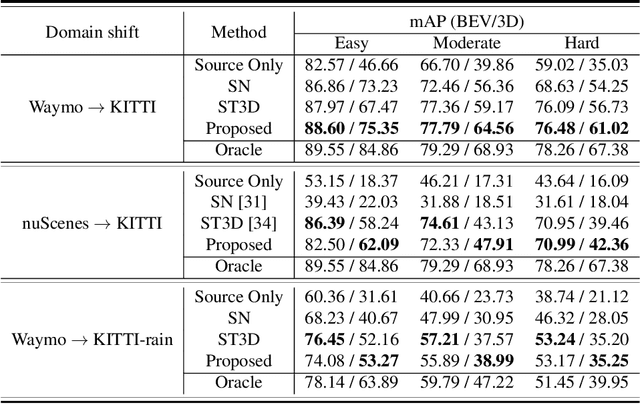
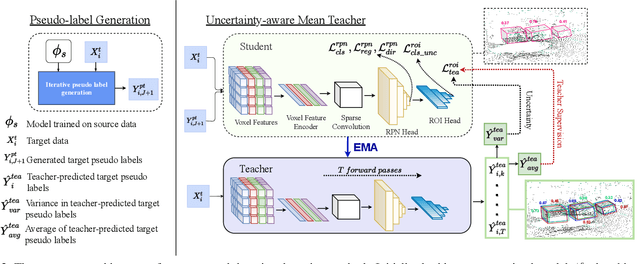

Pseudo-label based self training approaches are a popular method for source-free unsupervised domain adaptation. However, their efficacy depends on the quality of the labels generated by the source trained model. These labels may be incorrect with high confidence, rendering thresholding methods ineffective. In order to avoid reinforcing errors caused by label noise, we propose an uncertainty-aware mean teacher framework which implicitly filters incorrect pseudo-labels during training. Leveraging model uncertainty allows the mean teacher network to perform implicit filtering by down-weighing losses corresponding uncertain pseudo-labels. Effectively, we perform automatic soft-sampling of pseudo-labeled data while aligning predictions from the student and teacher networks. We demonstrate our method on several domain adaptation scenarios, from cross-dataset to cross-weather conditions, and achieve state-of-the-art performance in these cases, on the KITTI lidar target dataset.
Lidar Light Scattering Augmentation (LISA): Physics-based Simulation of Adverse Weather Conditions for 3D Object Detection
Jul 14, 2021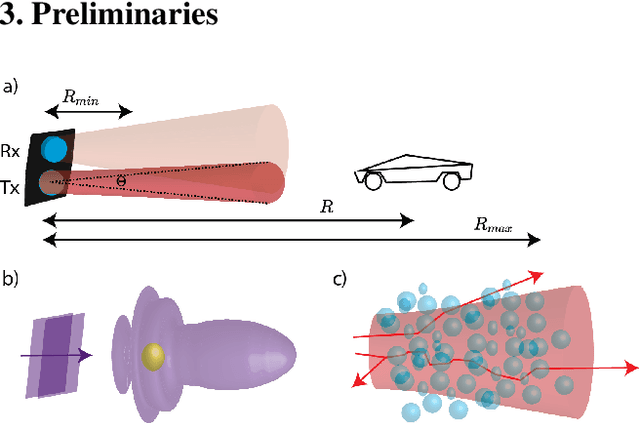

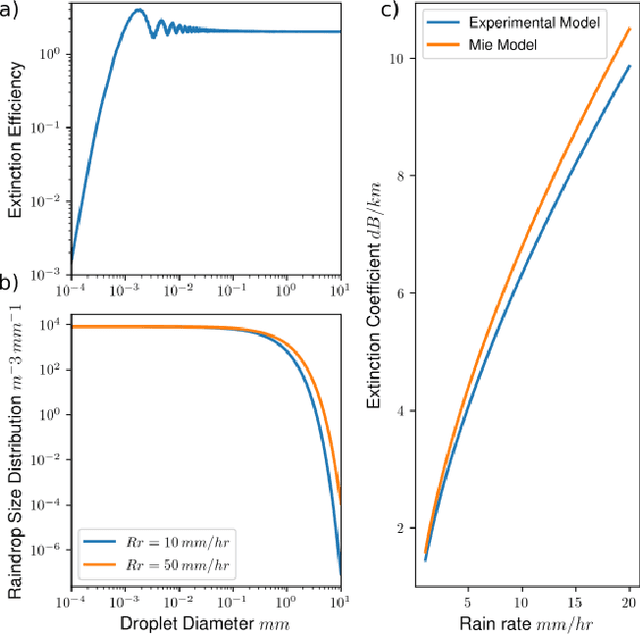
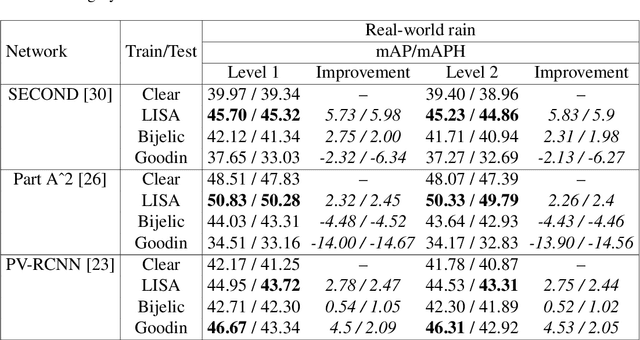
Lidar-based object detectors are critical parts of the 3D perception pipeline in autonomous navigation systems such as self-driving cars. However, they are known to be sensitive to adverse weather conditions such as rain, snow and fog due to reduced signal-to-noise ratio (SNR) and signal-to-background ratio (SBR). As a result, lidar-based object detectors trained on data captured in normal weather tend to perform poorly in such scenarios. However, collecting and labelling sufficient training data in a diverse range of adverse weather conditions is laborious and prohibitively expensive. To address this issue, we propose a physics-based approach to simulate lidar point clouds of scenes in adverse weather conditions. These augmented datasets can then be used to train lidar-based detectors to improve their all-weather reliability. Specifically, we introduce a hybrid Monte-Carlo based approach that treats (i) the effects of large particles by placing them randomly and comparing their back reflected power against the target, and (ii) attenuation effects on average through calculation of scattering efficiencies from the Mie theory and particle size distributions. Retraining networks with this augmented data improves mean average precision evaluated on real world rainy scenes and we observe greater improvement in performance with our model relative to existing models from the literature. Furthermore, we evaluate recent state-of-the-art detectors on the simulated weather conditions and present an in-depth analysis of their performance.