 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStable Diffusion Models are Secretly Good at Visual In-Context Learning
Aug 13, 2025Large language models (LLM) in natural language processing (NLP) have demonstrated great potential for in-context learning (ICL) -- the ability to leverage a few sets of example prompts to adapt to various tasks without having to explicitly update the model weights. ICL has recently been explored for computer vision tasks with promising early outcomes. These approaches involve specialized training and/or additional data that complicate the process and limit its generalizability. In this work, we show that off-the-shelf Stable Diffusion models can be repurposed for visual in-context learning (V-ICL). Specifically, we formulate an in-place attention re-computation within the self-attention layers of the Stable Diffusion architecture that explicitly incorporates context between the query and example prompts. Without any additional fine-tuning, we show that this repurposed Stable Diffusion model is able to adapt to six different tasks: foreground segmentation, single object detection, semantic segmentation, keypoint detection, edge detection, and colorization. For example, the proposed approach improves the mean intersection over union (mIoU) for the foreground segmentation task on Pascal-5i dataset by 8.9% and 3.2% over recent methods such as Visual Prompting and IMProv, respectively. Additionally, we show that the proposed method is able to effectively leverage multiple prompts through ensembling to infer the task better and further improve the performance.
Uncertainty-aware Mean Teacher for Source-free Unsupervised Domain Adaptive 3D Object Detection
Sep 29, 2021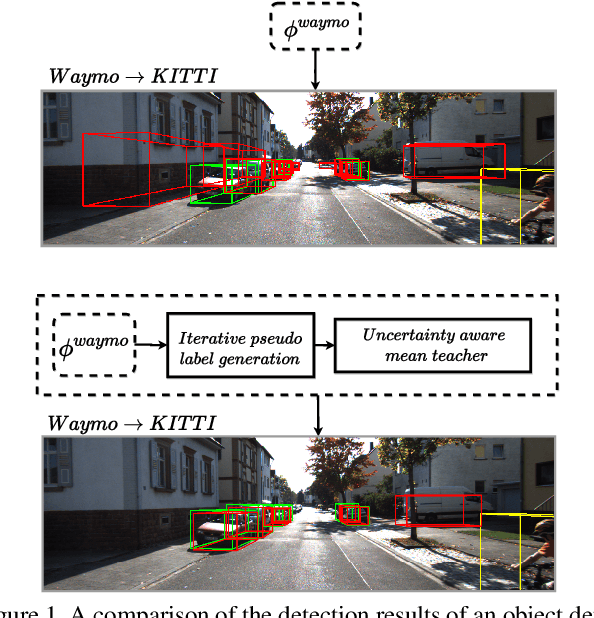
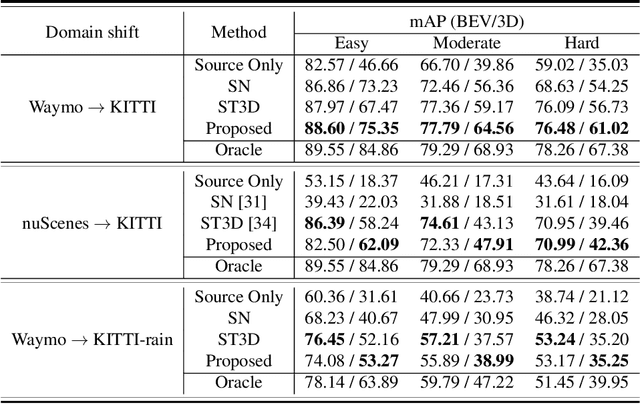
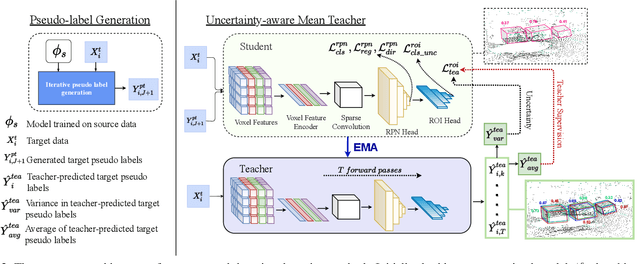

Pseudo-label based self training approaches are a popular method for source-free unsupervised domain adaptation. However, their efficacy depends on the quality of the labels generated by the source trained model. These labels may be incorrect with high confidence, rendering thresholding methods ineffective. In order to avoid reinforcing errors caused by label noise, we propose an uncertainty-aware mean teacher framework which implicitly filters incorrect pseudo-labels during training. Leveraging model uncertainty allows the mean teacher network to perform implicit filtering by down-weighing losses corresponding uncertain pseudo-labels. Effectively, we perform automatic soft-sampling of pseudo-labeled data while aligning predictions from the student and teacher networks. We demonstrate our method on several domain adaptation scenarios, from cross-dataset to cross-weather conditions, and achieve state-of-the-art performance in these cases, on the KITTI lidar target dataset.
Lidar Light Scattering Augmentation (LISA): Physics-based Simulation of Adverse Weather Conditions for 3D Object Detection
Jul 14, 2021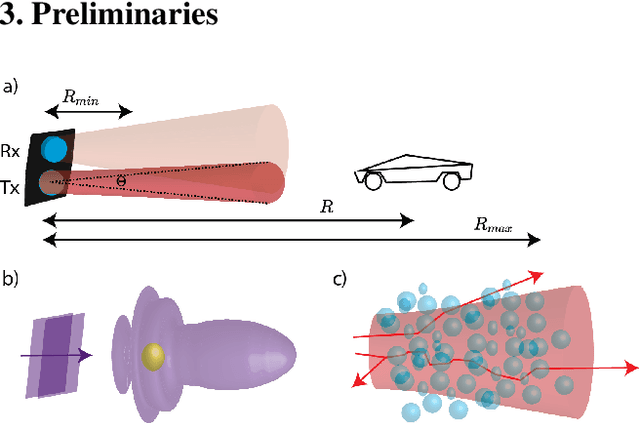

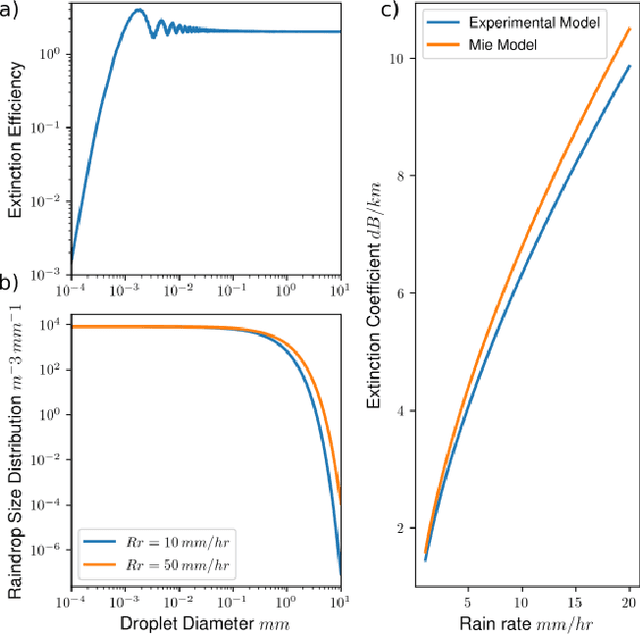
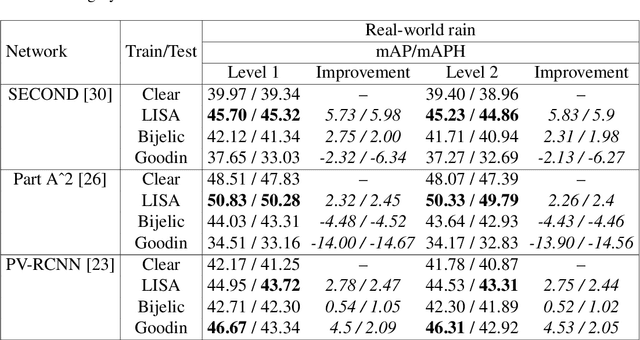
Lidar-based object detectors are critical parts of the 3D perception pipeline in autonomous navigation systems such as self-driving cars. However, they are known to be sensitive to adverse weather conditions such as rain, snow and fog due to reduced signal-to-noise ratio (SNR) and signal-to-background ratio (SBR). As a result, lidar-based object detectors trained on data captured in normal weather tend to perform poorly in such scenarios. However, collecting and labelling sufficient training data in a diverse range of adverse weather conditions is laborious and prohibitively expensive. To address this issue, we propose a physics-based approach to simulate lidar point clouds of scenes in adverse weather conditions. These augmented datasets can then be used to train lidar-based detectors to improve their all-weather reliability. Specifically, we introduce a hybrid Monte-Carlo based approach that treats (i) the effects of large particles by placing them randomly and comparing their back reflected power against the target, and (ii) attenuation effects on average through calculation of scattering efficiencies from the Mie theory and particle size distributions. Retraining networks with this augmented data improves mean average precision evaluated on real world rainy scenes and we observe greater improvement in performance with our model relative to existing models from the literature. Furthermore, we evaluate recent state-of-the-art detectors on the simulated weather conditions and present an in-depth analysis of their performance.
KiU-Net: Towards Accurate Segmentation of Biomedical Images using Over-complete Representations
Jun 08, 2020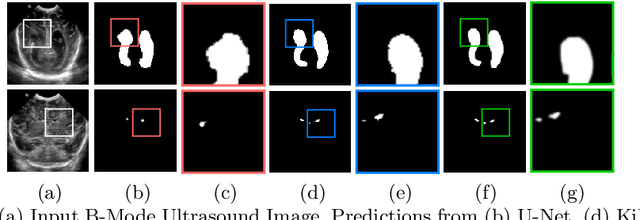
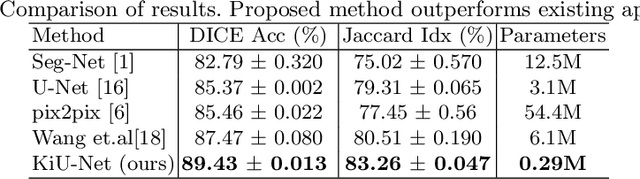
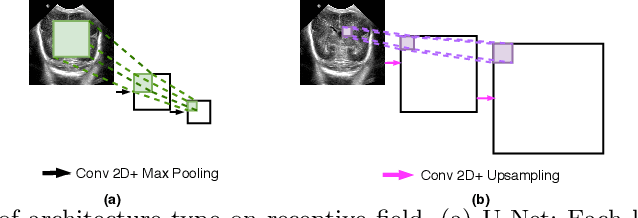

Due to its excellent performance, U-Net is the most widely used backbone architecture for biomedical image segmentation in the recent years. However, in our studies, we observe that there is a considerable performance drop in the case of detecting smaller anatomical landmarks with blurred noisy boundaries. We analyze this issue in detail, and address it by proposing an over-complete architecture (Ki-Net) which involves projecting the data onto higher dimensions (in the spatial sense). This network, when augmented with U-Net, results in significant improvements in the case of segmenting small anatomical landmarks and blurred noisy boundaries while obtaining better overall performance. Furthermore, the proposed network has additional benefits like faster convergence and fewer number of parameters. We evaluate the proposed method on the task of brain anatomy segmentation from 2D Ultrasound (US) of preterm neonates, and achieve an improvement of around 4% in terms of the DICE accuracy and Jaccard index as compared to the standard-U-Net, while outperforming the recent best methods by 2%. Code: https://github.com/jeya-maria-jose/KiU-Net-pytorch .
Joint Transmission Map Estimation and Dehazing using Deep Networks
Aug 02, 2017



Single image haze removal is an extremely challenging problem due to its inherent ill-posed nature. Several prior-based and learning-based methods have been proposed in the literature to solve this problem and they have achieved superior results. However, most of the existing methods assume constant atmospheric light model and tend to follow a two- step procedure involving prior-based methods for estimating transmission map followed by calculation of dehazed image using the closed form solution. In this paper, we relax the constant atmospheric light assumption and propose a novel unified single image dehazing network that jointly estimates the transmission map and performs dehazing. In other words, our new approach provides an end-to-end learning framework, where the inherent transmission map and dehazed result are learned directly from the loss function. Extensive experiments on synthetic and real datasets with challenging hazy images demonstrate that the proposed method achieves significant improvements over the state-of-the-art methods.
Image De-raining Using a Conditional Generative Adversarial Network
Feb 04, 2017
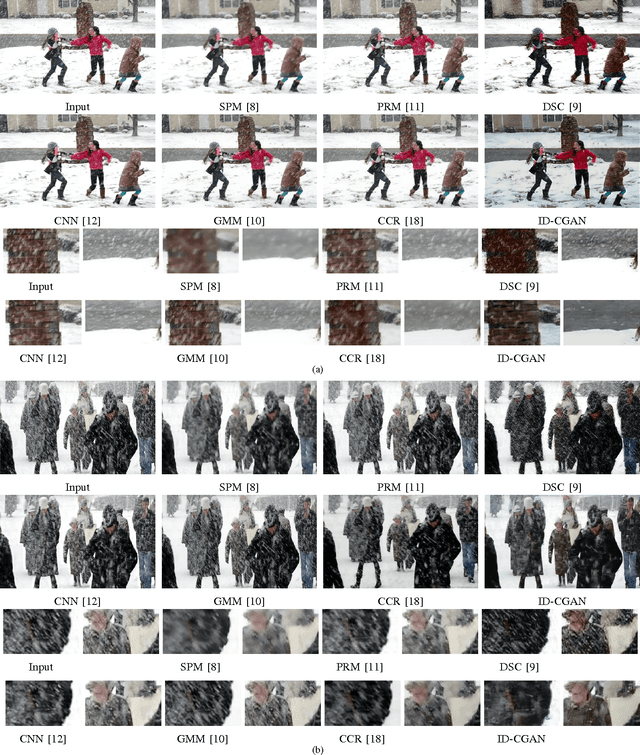


Severe weather conditions such as rain and snow adversely affect the visual quality of images captured under such conditions thus rendering them useless for further usage and sharing. In addition, such degraded images drastically affect performance of vision systems. Hence, it is important to solve the problem of single image de-raining/de-snowing. However, this is a difficult problem to solve due to its inherent ill-posed nature. Existing approaches attempt to introduce prior information to convert it into a well-posed problem. In this paper, we investigate a new point of view in addressing the single image de-raining problem. Instead of focusing only on deciding what is a good prior or a good framework to achieve good quantitative and qualitative performance, we also ensure that the de-rained image itself does not degrade the performance of a given computer vision algorithm such as detection and classification. In other words, the de-rained result should be indistinguishable from its corresponding clear image to a given discriminator. This criterion can be directly incorporated into the optimization framework by using the recently introduced conditional generative adversarial networks (GANs). To minimize artifacts introduced by GANs and ensure better visual quality, a new refined loss function is introduced. Based on this, we propose a novel single image de-raining method called Image De-raining Conditional General Adversarial Network (ID-CGAN), which considers quantitative, visual and also discriminative performance into the objective function. Experiments evaluated on synthetic images and real images show that the proposed method outperforms many recent state-of-the-art single image de-raining methods in terms of quantitative and visual performance.