 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealBirdID: Benchmarking Bird Species Identification in the Era of MLLMs
Mar 27, 2026Fine-grained bird species identification in the wild is frequently unanswerable from a single image: key cues may be non-visual (e.g. vocalization), or obscured due to occlusion, camera angle, or low resolution. Yet today's multimodal systems are typically judged on answerable, in-schema cases, encouraging confident guesses rather than principled abstention. We propose the RealBirdID benchmark: given an image of a bird, a system should either answer with a species or abstain with a concrete, evidence-based rationale: "requires vocalization," "low quality image," or "view obstructed". For each genus, the dataset includes a validation split composed of curated unanswerable examples with labeled rationales, paired with a companion set of clearly answerable instances. We find that (1) the species identification on the answerable set is challenging for a variety of open-source and proprietary models (less than 13% accuracy for MLLMs including GPT-5 and Gemini-2.5 Pro), (2) models with greater classification ability are not necessarily more calibrated to abstain from unanswerable examples, and (3) that MLLMs generally fail at providing correct reasons even when they do abstain. RealBirdID establishes a focused target for abstention-aware fine-grained recognition and a recipe for measuring progress.
FLIGHT: Fibonacci Lattice-based Inference for Geometric Heading in real-Time
Feb 26, 2026Estimating camera motion from monocular video is a fundamental problem in computer vision, central to tasks such as SLAM, visual odometry, and structure-from-motion. Existing methods that recover the camera's heading under known rotation, whether from an IMU or an optimization algorithm, tend to perform well in low-noise, low-outlier conditions, but often decrease in accuracy or become computationally expensive as noise and outlier levels increase. To address these limitations, we propose a novel generalization of the Hough transform on the unit sphere (S(2)) to estimate the camera's heading. First, the method extracts correspondences between two frames and generates a great circle of directions compatible with each pair of correspondences. Then, by discretizing the unit sphere using a Fibonacci lattice as bin centers, each great circle casts votes for a range of directions, ensuring that features unaffected by noise or dynamic objects vote consistently for the correct motion direction. Experimental results on three datasets demonstrate that the proposed method is on the Pareto frontier of accuracy versus efficiency. Additionally, experiments on SLAM show that the proposed method reduces RMSE by correcting the heading during camera pose initialization.
Robust Frame-to-Frame Camera Rotation Estimation in Crowded Scenes
Sep 15, 2023



We present an approach to estimating camera rotation in crowded, real-world scenes from handheld monocular video. While camera rotation estimation is a well-studied problem, no previous methods exhibit both high accuracy and acceptable speed in this setting. Because the setting is not addressed well by other datasets, we provide a new dataset and benchmark, with high-accuracy, rigorously verified ground truth, on 17 video sequences. Methods developed for wide baseline stereo (e.g., 5-point methods) perform poorly on monocular video. On the other hand, methods used in autonomous driving (e.g., SLAM) leverage specific sensor setups, specific motion models, or local optimization strategies (lagging batch processing) and do not generalize well to handheld video. Finally, for dynamic scenes, commonly used robustification techniques like RANSAC require large numbers of iterations, and become prohibitively slow. We introduce a novel generalization of the Hough transform on SO(3) to efficiently and robustly find the camera rotation most compatible with optical flow. Among comparably fast methods, ours reduces error by almost 50\% over the next best, and is more accurate than any method, irrespective of speed. This represents a strong new performance point for crowded scenes, an important setting for computer vision. The code and the dataset are available at https://fabiendelattre.com/robust-rotation-estimation.
A Domain-Agnostic Approach for Characterization of Lifelong Learning Systems
Jan 18, 2023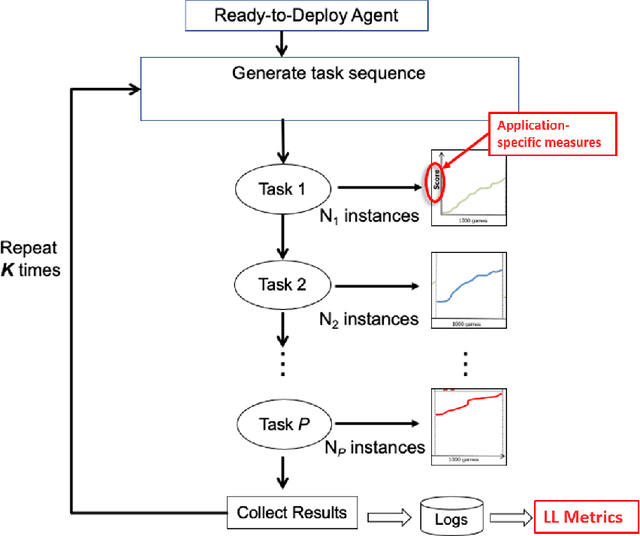


Despite the advancement of machine learning techniques in recent years, state-of-the-art systems lack robustness to "real world" events, where the input distributions and tasks encountered by the deployed systems will not be limited to the original training context, and systems will instead need to adapt to novel distributions and tasks while deployed. This critical gap may be addressed through the development of "Lifelong Learning" systems that are capable of 1) Continuous Learning, 2) Transfer and Adaptation, and 3) Scalability. Unfortunately, efforts to improve these capabilities are typically treated as distinct areas of research that are assessed independently, without regard to the impact of each separate capability on other aspects of the system. We instead propose a holistic approach, using a suite of metrics and an evaluation framework to assess Lifelong Learning in a principled way that is agnostic to specific domains or system techniques. Through five case studies, we show that this suite of metrics can inform the development of varied and complex Lifelong Learning systems. We highlight how the proposed suite of metrics quantifies performance trade-offs present during Lifelong Learning system development - both the widely discussed Stability-Plasticity dilemma and the newly proposed relationship between Sample Efficient and Robust Learning. Further, we make recommendations for the formulation and use of metrics to guide the continuing development of Lifelong Learning systems and assess their progress in the future.
Self-supervised visual feature learning with curriculum
Jan 16, 2020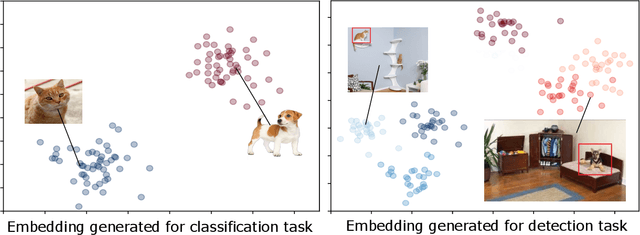

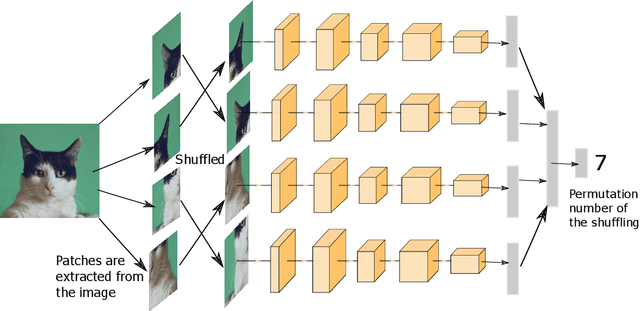
Self-supervised learning techniques have shown their abilities to learn meaningful feature representation. This is made possible by training a model on pretext tasks that only requires to find correlations between inputs or parts of inputs. However, such pretext tasks need to be carefully hand selected to avoid low level signals that could make those pretext tasks trivial. Moreover, removing those shortcuts often leads to the loss of some semantically valuable information. We show that it directly impacts the speed of learning of the downstream task. In this paper we took inspiration from curriculum learning to progressively remove low level signals and show that it significantly increase the speed of convergence of the downstream task.