 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised visual feature learning with curriculum
Jan 16, 2020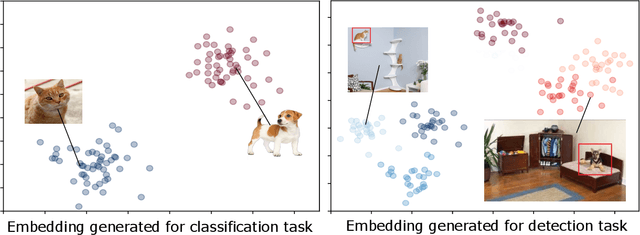

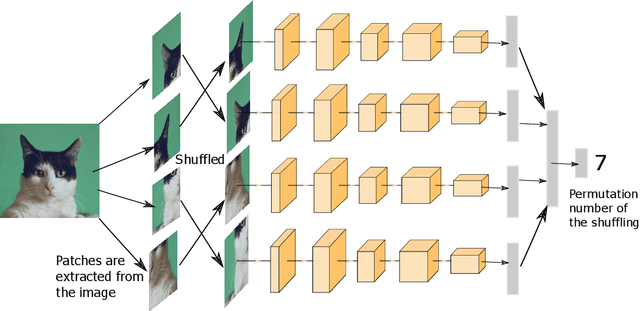
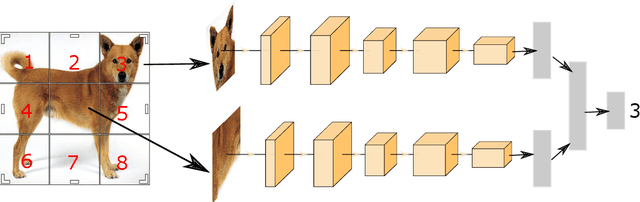
Self-supervised learning techniques have shown their abilities to learn meaningful feature representation. This is made possible by training a model on pretext tasks that only requires to find correlations between inputs or parts of inputs. However, such pretext tasks need to be carefully hand selected to avoid low level signals that could make those pretext tasks trivial. Moreover, removing those shortcuts often leads to the loss of some semantically valuable information. We show that it directly impacts the speed of learning of the downstream task. In this paper we took inspiration from curriculum learning to progressively remove low level signals and show that it significantly increase the speed of convergence of the downstream task.
Decoupling Semantic Context and Color Correlation with multi-class cross branch regularization
Oct 18, 2018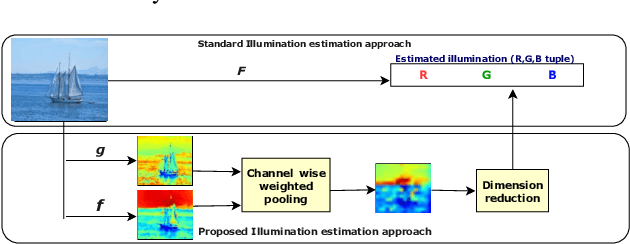

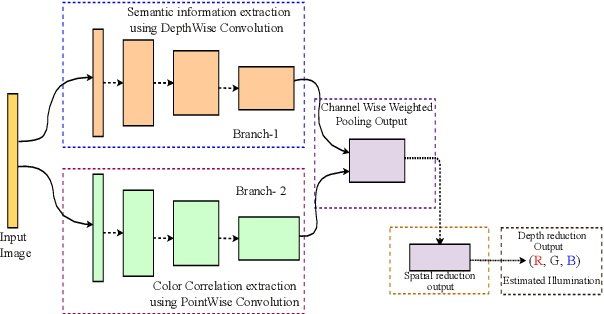
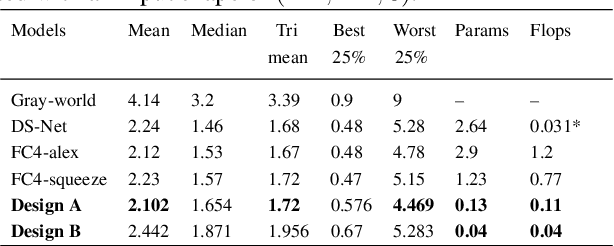
Success and applicability of Deep Neural Network (DNN) based methods for mobile vision tasks inspired the research community to design efficient vision-based models for performance constrained embedded devices. This paper presents a novel design methodology for architecting light-weight and fast models for a class of mobile-based vision applications. To demonstrate the effectiveness of our architecture, we picked color constancy task, an essential and inherently present block in camera and imaging pipelines of all vision-based applications. Specifically, we present a multi-branch architecture that decouples processing of spatial context and color correlation present in an image, and later combine these two signals in order to predict a global property (e.g. global illumination of the scene). We also came up with an innovative implicit regularization technique called cross-branch regularization in our architectural design helping us in achieving higher generalization accuracy. With a conservative use of best operators available for learning semantic information and color properties, we show that our architecture is able to reach state of the art accuracy with 30X lesser model parameters and 70X faster inference time. This makes our method most suitable for real-time mobile vision use cases. We also show that our method is generic and with minimal tuning, can be applied to other vision applications such as low-light photography.