Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised visual feature learning with curriculum
Paper and Code
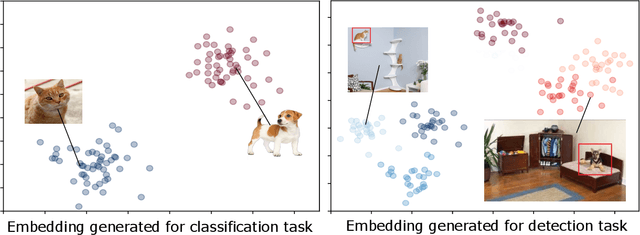

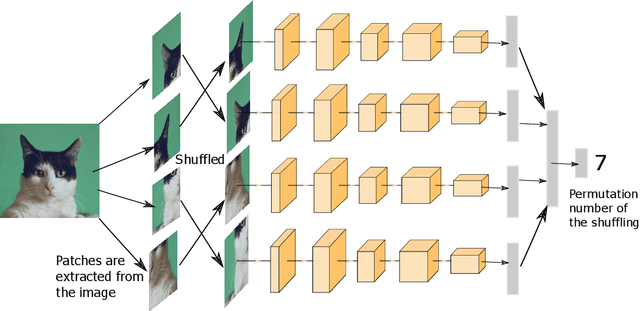
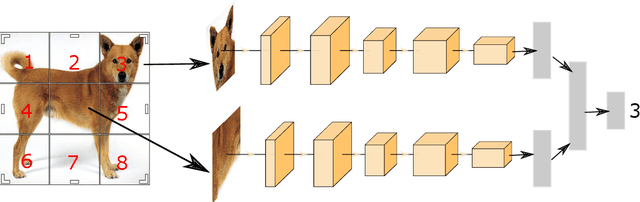
Self-supervised learning techniques have shown their abilities to learn meaningful feature representation. This is made possible by training a model on pretext tasks that only requires to find correlations between inputs or parts of inputs. However, such pretext tasks need to be carefully hand selected to avoid low level signals that could make those pretext tasks trivial. Moreover, removing those shortcuts often leads to the loss of some semantically valuable information. We show that it directly impacts the speed of learning of the downstream task. In this paper we took inspiration from curriculum learning to progressively remove low level signals and show that it significantly increase the speed of convergence of the downstream task.
* 9 pages
View paper on