 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurriculum-enhanced GroupDRO: Challenging the Norm of Avoiding Curriculum Learning in Subpopulation Shift Setups
Nov 22, 2024

In subpopulation shift scenarios, a Curriculum Learning (CL) approach would only serve to imprint the model weights, early on, with the easily learnable spurious correlations featured. To the best of our knowledge, none of the current state-of-the-art subpopulation shift approaches employ any kind of curriculum. To overcome this, we design a CL approach aimed at initializing the model weights in an unbiased vantage point in the hypothesis space which sabotages easy convergence towards biased hypotheses during the final optimization based on the entirety of the available data. We hereby propose a Curriculum-enhanced Group Distributionally Robust Optimization (CeGDRO) approach, which prioritizes the hardest bias-confirming samples and the easiest bias-conflicting samples, leveraging GroupDRO to balance the initial discrepancy in terms of difficulty. We benchmark our proposed method against the most popular subpopulation shift datasets, showing an increase over the state-of-the-art results across all scenarios, up to 6.2% on Waterbirds.
SSMTL++: Revisiting Self-Supervised Multi-Task Learning for Video Anomaly Detection
Jul 16, 2022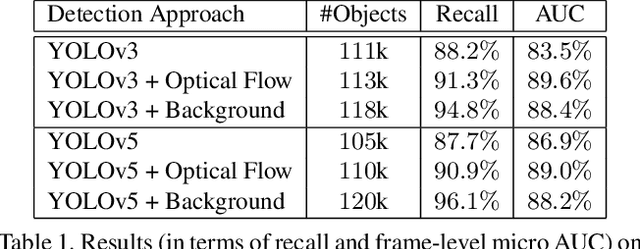
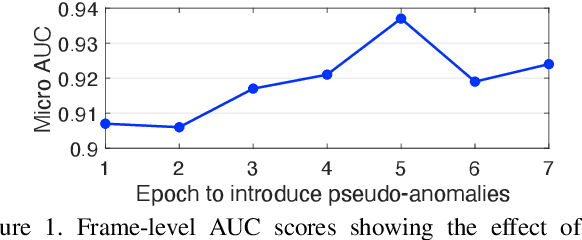
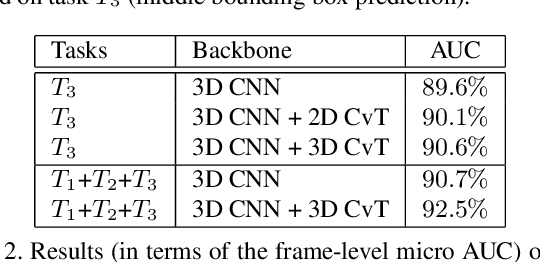
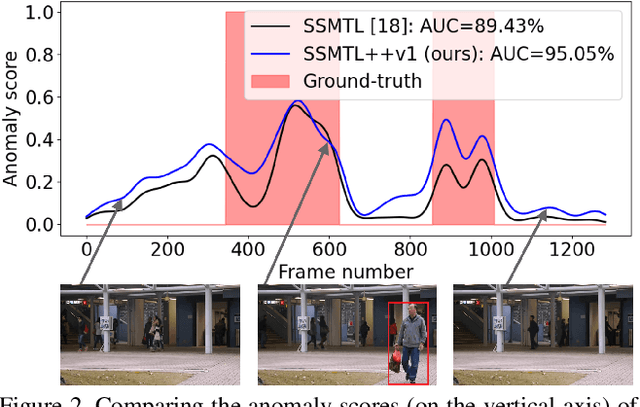
A self-supervised multi-task learning (SSMTL) framework for video anomaly detection was recently introduced in literature. Due to its highly accurate results, the method attracted the attention of many researchers. In this work, we revisit the self-supervised multi-task learning framework, proposing several updates to the original method. First, we study various detection methods, e.g. based on detecting high-motion regions using optical flow or background subtraction, since we believe the currently used pre-trained YOLOv3 is suboptimal, e.g. objects in motion or objects from unknown classes are never detected. Second, we modernize the 3D convolutional backbone by introducing multi-head self-attention modules, inspired by the recent success of vision transformers. As such, we alternatively introduce both 2D and 3D convolutional vision transformer (CvT) blocks. Third, in our attempt to further improve the model, we study additional self-supervised learning tasks, such as predicting segmentation maps through knowledge distillation, solving jigsaw puzzles, estimating body pose through knowledge distillation, predicting masked regions (inpainting), and adversarial learning with pseudo-anomalies. We conduct experiments to assess the performance impact of the introduced changes. Upon finding more promising configurations of the framework, dubbed SSMTL++v1 and SSMTL++v2, we extend our preliminary experiments to more data sets, demonstrating that our performance gains are consistent across all data sets. In most cases, our results on Avenue, ShanghaiTech and UBnormal raise the state-of-the-art performance to a new level.
VeriDark: A Large-Scale Benchmark for Authorship Verification on the Dark Web
Jul 07, 2022
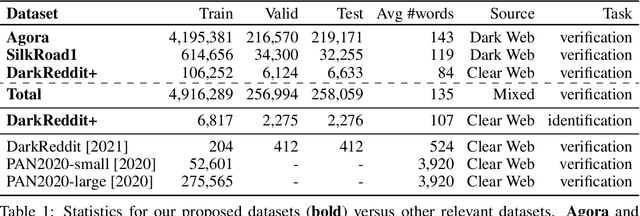
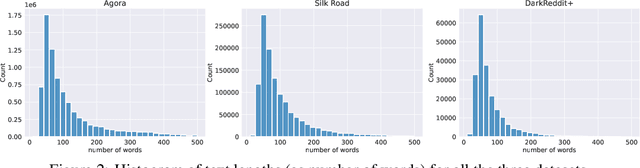
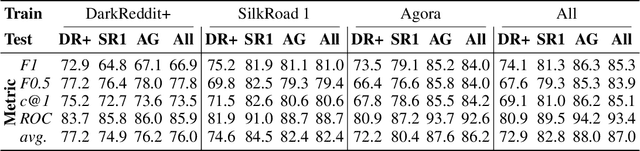
The DarkWeb represents a hotbed for illicit activity, where users communicate on different market forums in order to exchange goods and services. Law enforcement agencies benefit from forensic tools that perform authorship analysis, in order to identify and profile users based on their textual content. However, authorship analysis has been traditionally studied using corpora featuring literary texts such as fragments from novels or fan fiction, which may not be suitable in a cybercrime context. Moreover, the few works that employ authorship analysis tools for cybercrime prevention usually employ ad-hoc experimental setups and datasets. To address these issues, we release VeriDark: a benchmark comprised of three large scale authorship verification datasets and one authorship identification dataset obtained from user activity from either Dark Web related Reddit communities or popular illicit Dark Web market forums. We evaluate competitive NLP baselines on the three datasets and perform an analysis of the predictions to better understand the limitations of such approaches. We make the datasets and baselines publicly available at https://github.com/bit-ml/VeriDark
Transferring BERT-like Transformers' Knowledge for Authorship Verification
Dec 09, 2021

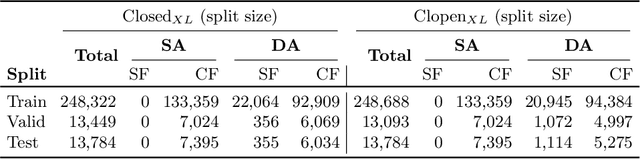

The task of identifying the author of a text spans several decades and was tackled using linguistics, statistics, and, more recently, machine learning. Inspired by the impressive performance gains across a broad range of natural language processing tasks and by the recent availability of the PAN large-scale authorship dataset, we first study the effectiveness of several BERT-like transformers for the task of authorship verification. Such models prove to achieve very high scores consistently. Next, we empirically show that they focus on topical clues rather than on author writing style characteristics, taking advantage of existing biases in the dataset. To address this problem, we provide new splits for PAN-2020, where training and test data are sampled from disjoint topics or authors. Finally, we introduce DarkReddit, a dataset with a different input data distribution. We further use it to analyze the domain generalization performance of models in a low-data regime and how performance varies when using the proposed PAN-2020 splits for fine-tuning. We show that those splits can enhance the models' capability to transfer knowledge over a new, significantly different dataset.
Anomaly Detection in Video via Self-Supervised and Multi-Task Learning
Nov 15, 2020

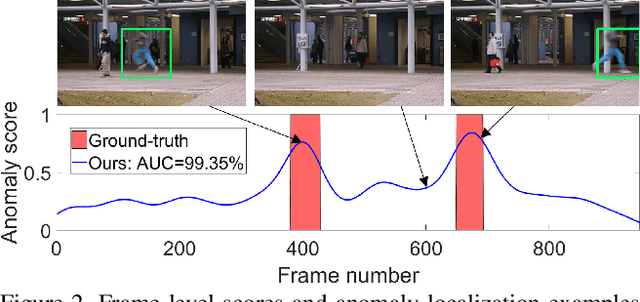
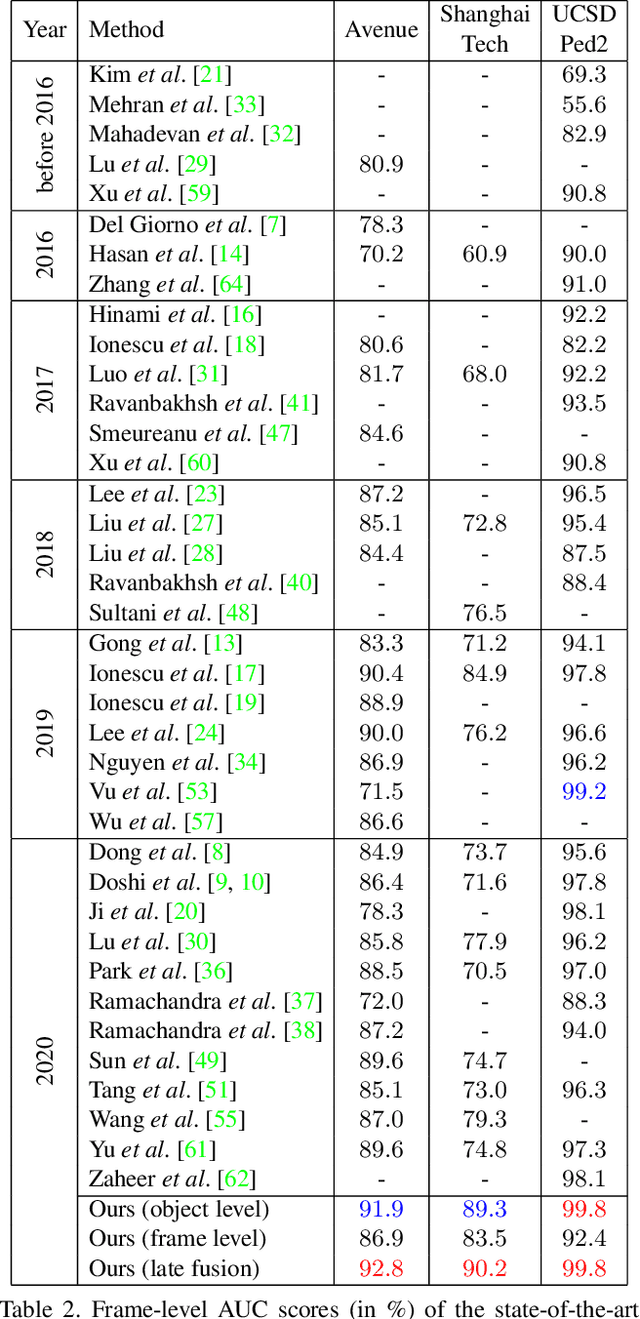
Anomaly detection in video is a challenging computer vision problem. Due to the lack of anomalous events at training time, anomaly detection requires the design of learning methods without full supervision. In this paper, we approach anomalous event detection in video through self-supervised and multi-task learning at the object level. We first utilize a pre-trained detector to detect objects. Then, we train a 3D convolutional neural network to produce discriminative anomaly-specific information by jointly learning multiple proxy tasks: three self-supervised and one based on knowledge distillation. The self-supervised tasks are: (i) discrimination of forward/backward moving objects (arrow of time), (ii) discrimination of objects in consecutive/intermittent frames (motion irregularity) and (iii) reconstruction of object-specific appearance information. The knowledge distillation task takes into account both classification and detection information, generating large prediction discrepancies between teacher and student models when anomalies occur. To the best of our knowledge, we are the first to approach anomalous event detection in video as a multi-task learning problem, integrating multiple self-supervised and knowledge distillation proxy tasks in a single architecture. Our lightweight architecture outperforms the state-of-the-art methods on three benchmarks: Avenue, ShanghaiTech and UCSD Ped2. Additionally, we perform an ablation study demonstrating the importance of integrating self-supervised learning and normality-specific distillation in a multi-task learning setting.
Black-Box Ripper: Copying black-box models using generative evolutionary algorithms
Oct 21, 2020

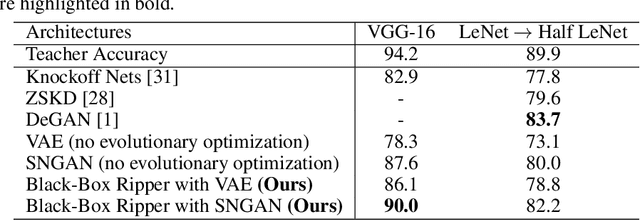

We study the task of replicating the functionality of black-box neural models, for which we only know the output class probabilities provided for a set of input images. We assume back-propagation through the black-box model is not possible and its training images are not available, e.g. the model could be exposed only through an API. In this context, we present a teacher-student framework that can distill the black-box (teacher) model into a student model with minimal accuracy loss. To generate useful data samples for training the student, our framework (i) learns to generate images on a proxy data set (with images and classes different from those used to train the black-box) and (ii) applies an evolutionary strategy to make sure that each generated data sample exhibits a high response for a specific class when given as input to the black box. Our framework is compared with several baseline and state-of-the-art methods on three benchmark data sets. The empirical evidence indicates that our model is superior to the considered baselines. Although our method does not back-propagate through the black-box network, it generally surpasses state-of-the-art methods that regard the teacher as a glass-box model. Our code is available at: https://github.com/antoniobarbalau/black-box-ripper.
A Generic and Model-Agnostic Exemplar Synthetization Framework for Explainable AI
Jul 01, 2020



With the growing complexity of deep learning methods adopted in practical applications, there is an increasing and stringent need to explain and interpret the decisions of such methods. In this work, we focus on explainable AI and propose a novel generic and model-agnostic framework for synthesizing input exemplars that maximize a desired response from a machine learning model. To this end, we use a generative model, which acts as a prior for generating data, and traverse its latent space using a novel evolutionary strategy with momentum updates. Our framework is generic because (i) it can employ any underlying generator, e.g. Variational Auto-Encoders (VAEs) or Generative Adversarial Networks (GANs), and (ii) it can be applied to any input data, e.g. images, text samples or tabular data. Since we use a zero-order optimization method, our framework is model-agnostic, in the sense that the machine learning model that we aim to explain is a black-box. We stress out that our novel framework does not require access or knowledge of the internal structure or the training data of the black-box model. We conduct experiments with two generative models, VAEs and GANs, and synthesize exemplars for various data formats, image, text and tabular, demonstrating that our framework is generic. We also employ our prototype synthetization framework on various black-box models, for which we only know the input and the output formats, showing that it is model-agnostic. Moreover, we compare our framework (available at https://github.com/antoniobarbalau/exemplar) with a model-dependent approach based on gradient descent, proving that our framework obtains equally-good exemplars in a shorter computational time.