 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTailLoR: Protecting Principal Components in Parameter-Efficient Continual Learning
Jun 04, 2026Parameter-efficient finetuning methods based on spectral decomposition have enabled progress in Continual Learning. In this paper we introduce TailLoR, which utilizes the singular bases U and V of the pre-trained weights as a fixed reference frame to learn a low-rank update applied to the singular value matrix. A soft spectral penalty discourages updates aligned with dominant singular directions, reducing interference while routing fine-grained adaptation into the highly flexible, long-tail spectral coordinates.
CLewR: Curriculum Learning with Restarts for Machine Translation Preference Learning
Jan 09, 2026Large language models (LLMs) have demonstrated competitive performance in zero-shot multilingual machine translation (MT). Some follow-up works further improved MT performance via preference optimization, but they leave a key aspect largely underexplored: the order in which data samples are given during training. We address this topic by integrating curriculum learning into various state-of-the-art preference optimization algorithms to boost MT performance. We introduce a novel curriculum learning strategy with restarts (CLewR), which reiterates easy-to-hard curriculum multiple times during training to effectively mitigate the catastrophic forgetting of easy examples. We demonstrate consistent gains across several model families (Gemma2, Qwen2.5, Llama3.1) and preference optimization techniques. We publicly release our code at https://github.com/alexandra-dragomir/CLewR.
C-ing Clearly: Enhanced Binary Code Explanations using C code
Dec 16, 2025Large Language Models (LLMs) typically excel at coding tasks involving high-level programming languages, as opposed to lower-level programming languages, such as assembly. We propose a synthetic data generation method named C-ing Clearly, which leverages the corresponding C code to enhance an LLM's understanding of assembly. By fine-tuning on data generated through our method, we demonstrate improved LLM performance for binary code summarization and vulnerability detection. Our approach demonstrates consistent gains across different LLM families and model sizes.
Time Series Anomaly Detection using Diffusion-based Models
Nov 02, 2023



Diffusion models have been recently used for anomaly detection (AD) in images. In this paper we investigate whether they can also be leveraged for AD on multivariate time series (MTS). We test two diffusion-based models and compare them to several strong neural baselines. We also extend the PA%K protocol, by computing a ROCK-AUC metric, which is agnostic to both the detection threshold and the ratio K of correctly detected points. Our models outperform the baselines on synthetic datasets and are competitive on real-world datasets, illustrating the potential of diffusion-based methods for AD in multivariate time series.
VeriDark: A Large-Scale Benchmark for Authorship Verification on the Dark Web
Jul 07, 2022
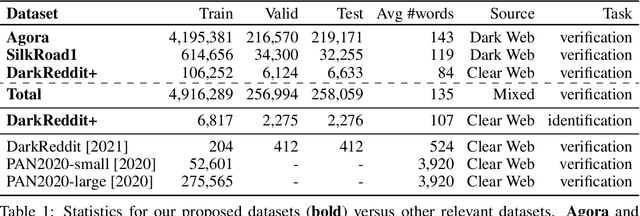
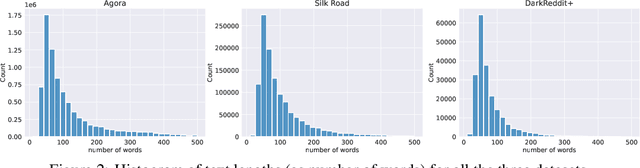
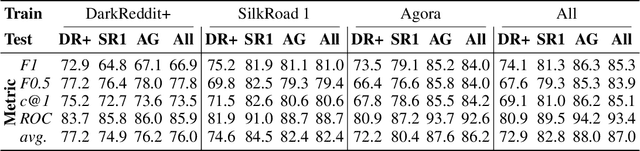
The DarkWeb represents a hotbed for illicit activity, where users communicate on different market forums in order to exchange goods and services. Law enforcement agencies benefit from forensic tools that perform authorship analysis, in order to identify and profile users based on their textual content. However, authorship analysis has been traditionally studied using corpora featuring literary texts such as fragments from novels or fan fiction, which may not be suitable in a cybercrime context. Moreover, the few works that employ authorship analysis tools for cybercrime prevention usually employ ad-hoc experimental setups and datasets. To address these issues, we release VeriDark: a benchmark comprised of three large scale authorship verification datasets and one authorship identification dataset obtained from user activity from either Dark Web related Reddit communities or popular illicit Dark Web market forums. We evaluate competitive NLP baselines on the three datasets and perform an analysis of the predictions to better understand the limitations of such approaches. We make the datasets and baselines publicly available at https://github.com/bit-ml/VeriDark
AnoShift: A Distribution Shift Benchmark for Unsupervised Anomaly Detection
Jun 30, 2022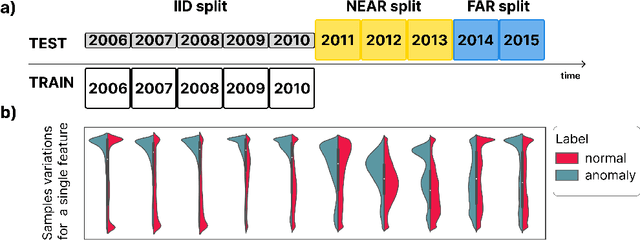

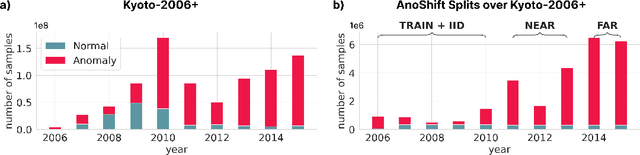
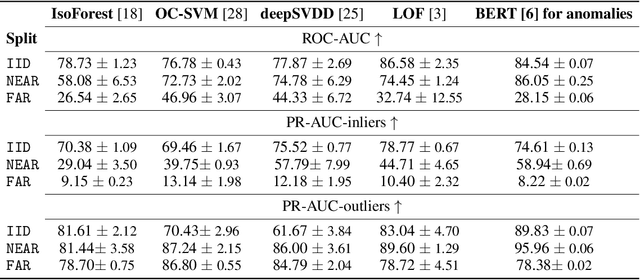
Analyzing the distribution shift of data is a growing research direction in nowadays Machine Learning, leading to emerging new benchmarks that focus on providing a suitable scenario for studying the generalization properties of ML models. The existing benchmarks are focused on supervised learning, and to the best of our knowledge, there is none for unsupervised learning. Therefore, we introduce an unsupervised anomaly detection benchmark with data that shifts over time, built over Kyoto-2006+, a traffic dataset for network intrusion detection. This kind of data meets the premise of shifting the input distribution: it covers a large time span ($10$ years), with naturally occurring changes over time (\eg users modifying their behavior patterns, and software updates). We first highlight the non-stationary nature of the data, using a basic per-feature analysis, t-SNE, and an Optimal Transport approach for measuring the overall distribution distances between years. Next, we propose AnoShift, a protocol splitting the data in IID, NEAR, and FAR testing splits. We validate the performance degradation over time with diverse models (MLM to classical Isolation Forest). Finally, we show that by acknowledging the distribution shift problem and properly addressing it, the performance can be improved compared to the classical IID training (by up to $3\%$, on average). Dataset and code are available at https://github.com/bit-ml/AnoShift/.
Transferring BERT-like Transformers' Knowledge for Authorship Verification
Dec 09, 2021

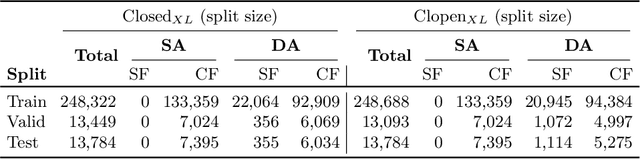

The task of identifying the author of a text spans several decades and was tackled using linguistics, statistics, and, more recently, machine learning. Inspired by the impressive performance gains across a broad range of natural language processing tasks and by the recent availability of the PAN large-scale authorship dataset, we first study the effectiveness of several BERT-like transformers for the task of authorship verification. Such models prove to achieve very high scores consistently. Next, we empirically show that they focus on topical clues rather than on author writing style characteristics, taking advantage of existing biases in the dataset. To address this problem, we provide new splits for PAN-2020, where training and test data are sampled from disjoint topics or authors. Finally, we introduce DarkReddit, a dataset with a different input data distribution. We further use it to analyze the domain generalization performance of models in a low-data regime and how performance varies when using the proposed PAN-2020 splits for fine-tuning. We show that those splits can enhance the models' capability to transfer knowledge over a new, significantly different dataset.
DATE: Detecting Anomalies in Text via Self-Supervision of Transformers
Apr 12, 2021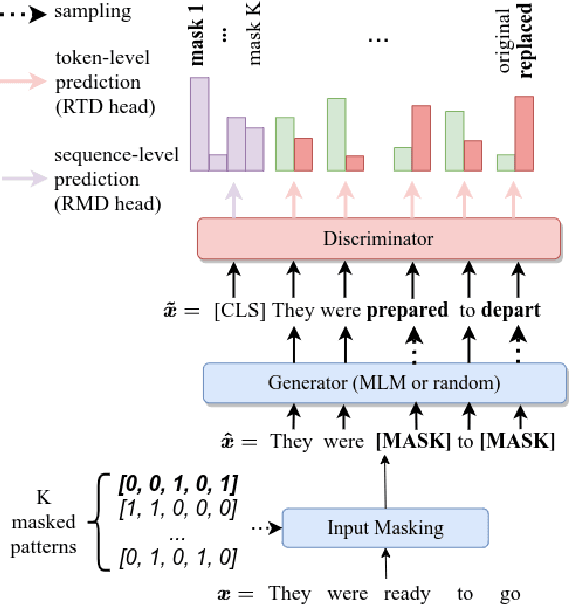

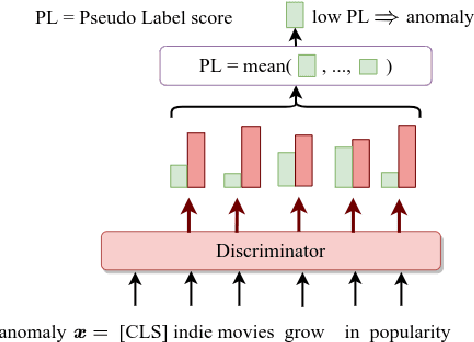

Leveraging deep learning models for Anomaly Detection (AD) has seen widespread use in recent years due to superior performances over traditional methods. Recent deep methods for anomalies in images learn better features of normality in an end-to-end self-supervised setting. These methods train a model to discriminate between different transformations applied to visual data and then use the output to compute an anomaly score. We use this approach for AD in text, by introducing a novel pretext task on text sequences. We learn our DATE model end-to-end, enforcing two independent and complementary self-supervision signals, one at the token-level and one at the sequence-level. Under this new task formulation, we show strong quantitative and qualitative results on the 20Newsgroups and AG News datasets. In the semi-supervised setting, we outperform state-of-the-art results by +13.5% and +6.9%, respectively (AUROC). In the unsupervised configuration, DATE surpasses all other methods even when 10% of its training data is contaminated with outliers (compared with 0% for the others).
Dataset for a Neural Natural Language Interface for Databases (NNLIDB)
Jul 11, 2017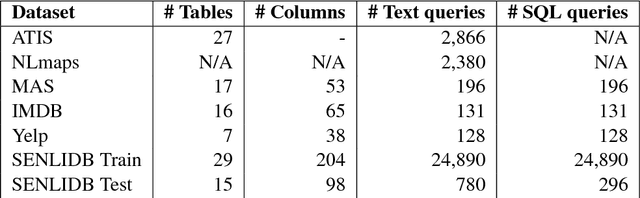
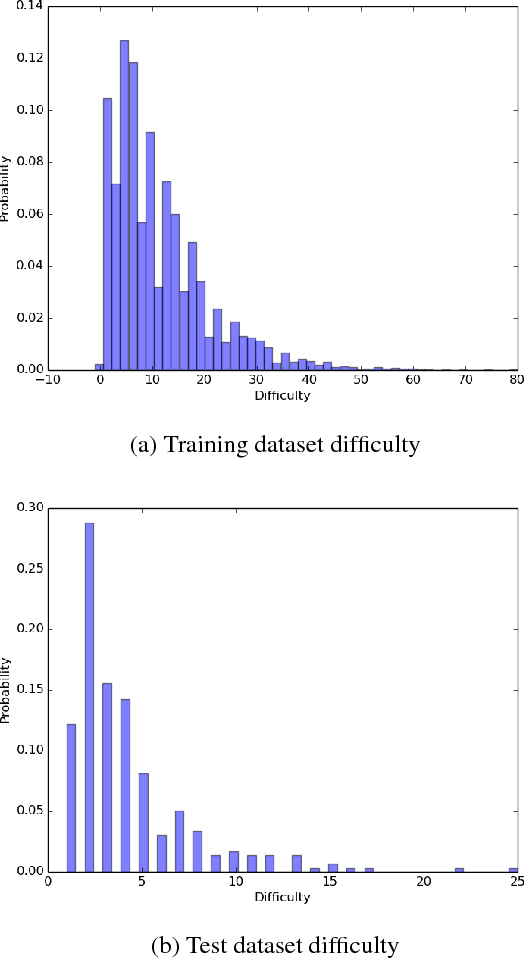
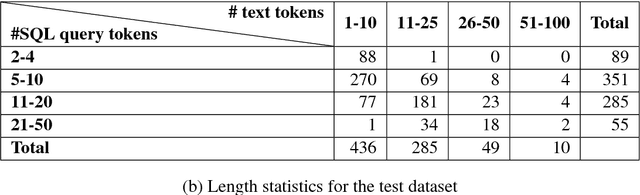
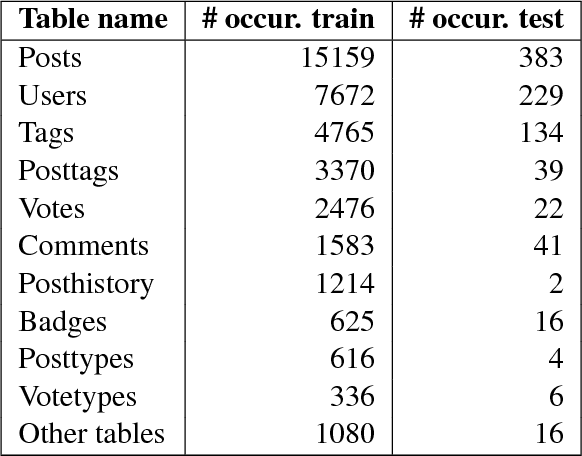
Progress in natural language interfaces to databases (NLIDB) has been slow mainly due to linguistic issues (such as language ambiguity) and domain portability. Moreover, the lack of a large corpus to be used as a standard benchmark has made data-driven approaches difficult to develop and compare. In this paper, we revisit the problem of NLIDBs and recast it as a sequence translation problem. To this end, we introduce a large dataset extracted from the Stack Exchange Data Explorer website, which can be used for training neural natural language interfaces for databases. We also report encouraging baseline results on a smaller manually annotated test corpus, obtained using an attention-based sequence-to-sequence neural network.