 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComplexity-based code embeddings
Jan 01, 2026This paper presents a generic method for transforming the source code of various algorithms to numerical embeddings, by dynamically analysing the behaviour of computer programs against different inputs and by tailoring multiple generic complexity functions for the analysed metrics. The used algorithms embeddings are based on r-Complexity . Using the proposed code embeddings, we present an implementation of the XGBoost algorithm that achieves an average F1-score on a multi-label dataset with 11 classes, built using real-world code snippets submitted for programming competitions on the Codeforces platform.
Dataset for a Neural Natural Language Interface for Databases (NNLIDB)
Jul 11, 2017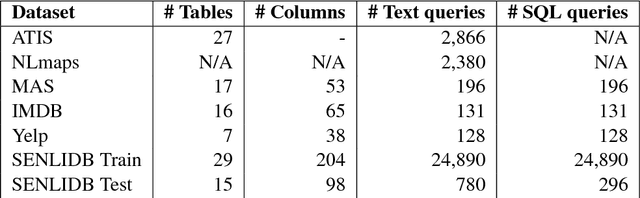
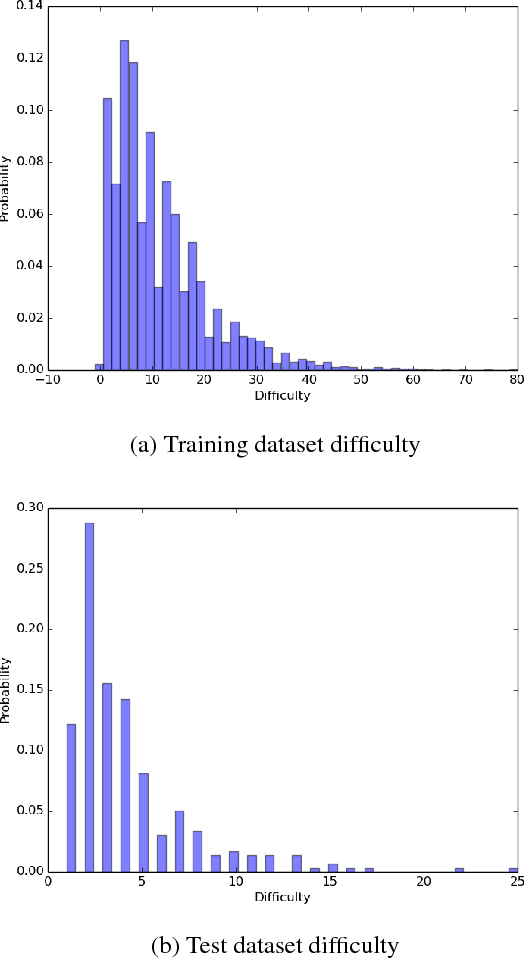
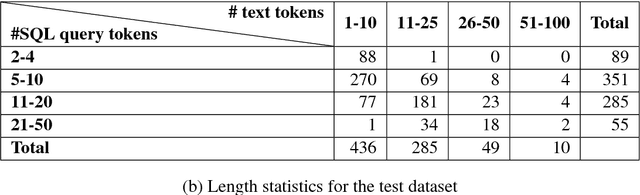
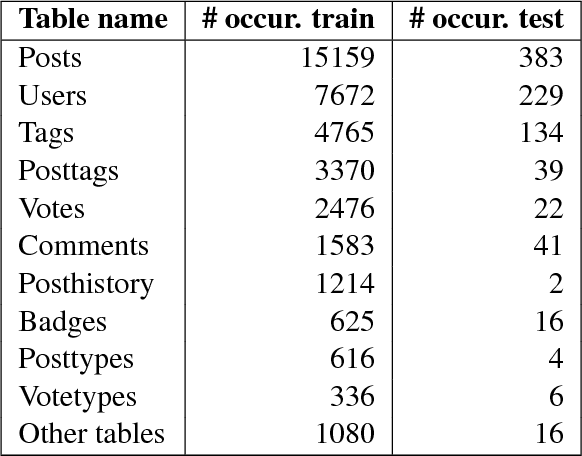
Progress in natural language interfaces to databases (NLIDB) has been slow mainly due to linguistic issues (such as language ambiguity) and domain portability. Moreover, the lack of a large corpus to be used as a standard benchmark has made data-driven approaches difficult to develop and compare. In this paper, we revisit the problem of NLIDBs and recast it as a sequence translation problem. To this end, we introduce a large dataset extracted from the Stack Exchange Data Explorer website, which can be used for training neural natural language interfaces for databases. We also report encouraging baseline results on a smaller manually annotated test corpus, obtained using an attention-based sequence-to-sequence neural network.