 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnoShift: A Distribution Shift Benchmark for Unsupervised Anomaly Detection
Jun 30, 2022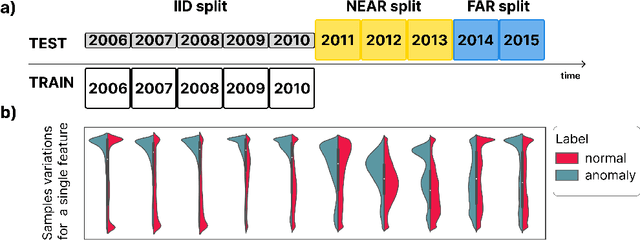

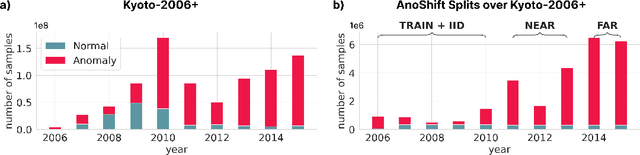
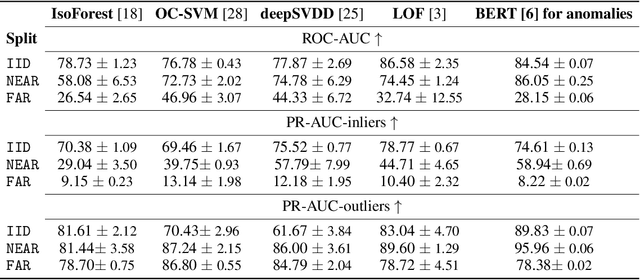
Analyzing the distribution shift of data is a growing research direction in nowadays Machine Learning, leading to emerging new benchmarks that focus on providing a suitable scenario for studying the generalization properties of ML models. The existing benchmarks are focused on supervised learning, and to the best of our knowledge, there is none for unsupervised learning. Therefore, we introduce an unsupervised anomaly detection benchmark with data that shifts over time, built over Kyoto-2006+, a traffic dataset for network intrusion detection. This kind of data meets the premise of shifting the input distribution: it covers a large time span ($10$ years), with naturally occurring changes over time (\eg users modifying their behavior patterns, and software updates). We first highlight the non-stationary nature of the data, using a basic per-feature analysis, t-SNE, and an Optimal Transport approach for measuring the overall distribution distances between years. Next, we propose AnoShift, a protocol splitting the data in IID, NEAR, and FAR testing splits. We validate the performance degradation over time with diverse models (MLM to classical Isolation Forest). Finally, we show that by acknowledging the distribution shift problem and properly addressing it, the performance can be improved compared to the classical IID training (by up to $3\%$, on average). Dataset and code are available at https://github.com/bit-ml/AnoShift/.