 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Multi-Head Convolutional Attention with Various Kernel Sizes for Medical Image Super-Resolution
Apr 12, 2022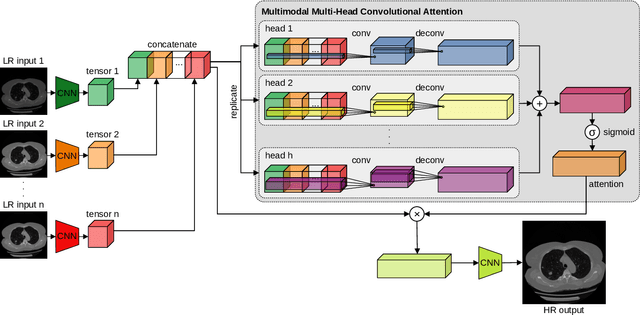
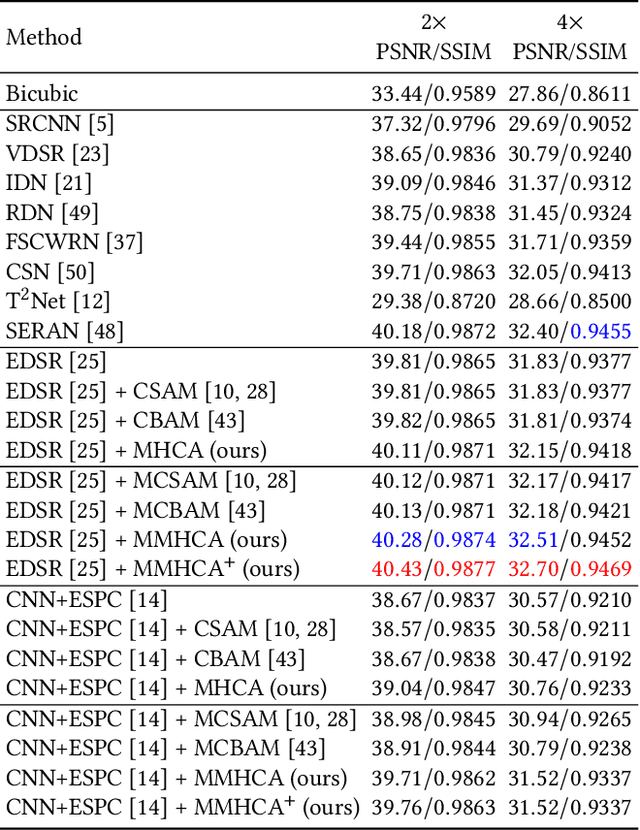
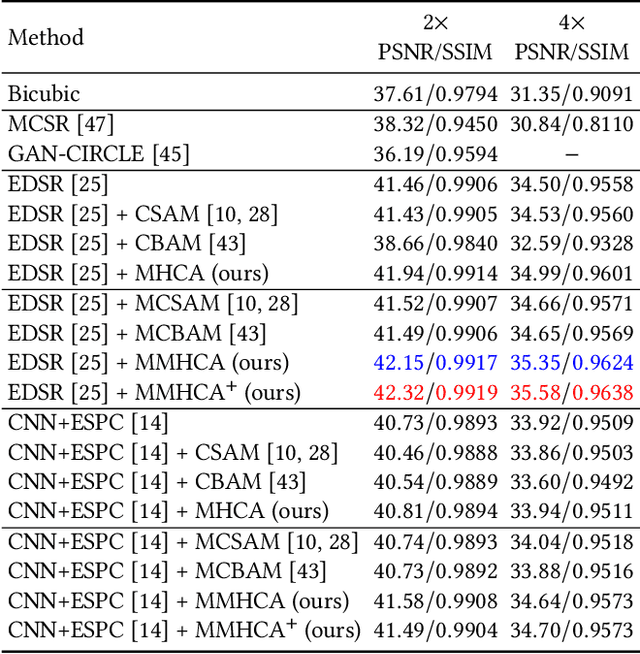
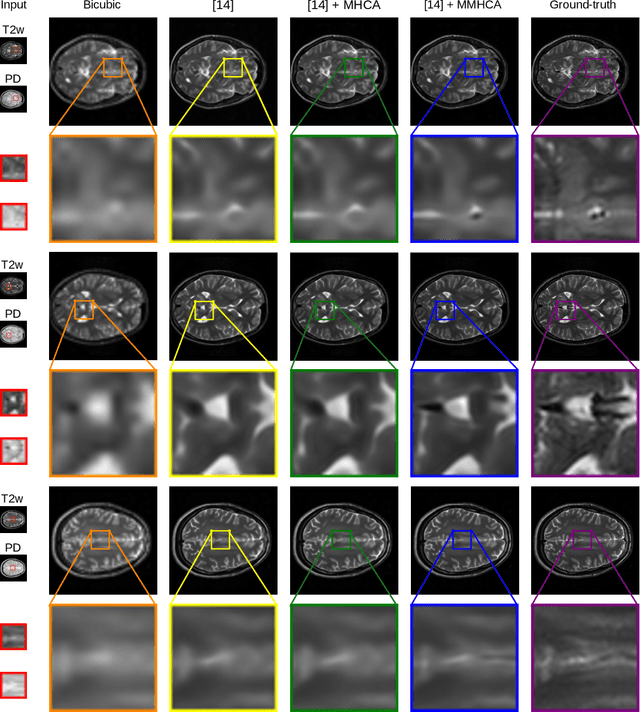
Super-resolving medical images can help physicians in providing more accurate diagnostics. In many situations, computed tomography (CT) or magnetic resonance imaging (MRI) techniques output several scans (modes) during a single investigation, which can jointly be used (in a multimodal fashion) to further boost the quality of super-resolution results. To this end, we propose a novel multimodal multi-head convolutional attention module to super-resolve CT and MRI scans. Our attention module uses the convolution operation to perform joint spatial-channel attention on multiple concatenated input tensors, where the kernel (receptive field) size controls the reduction rate of the spatial attention and the number of convolutional filters controls the reduction rate of the channel attention, respectively. We introduce multiple attention heads, each head having a distinct receptive field size corresponding to a particular reduction rate for the spatial attention. We integrate our multimodal multi-head convolutional attention (MMHCA) into two deep neural architectures for super-resolution and conduct experiments on three data sets. Our empirical results show the superiority of our attention module over the state-of-the-art attention mechanisms used in super-resolution. Moreover, we conduct an ablation study to assess the impact of the components involved in our attention module, e.g. the number of inputs or the number of heads.
CyTran: Cycle-Consistent Transformers for Non-Contrast to Contrast CT Translation
Oct 21, 2021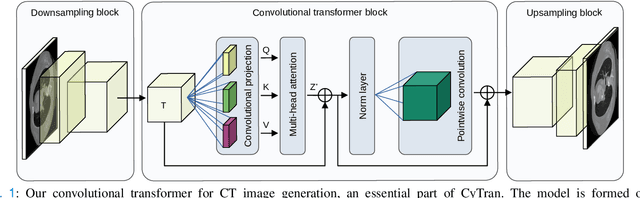
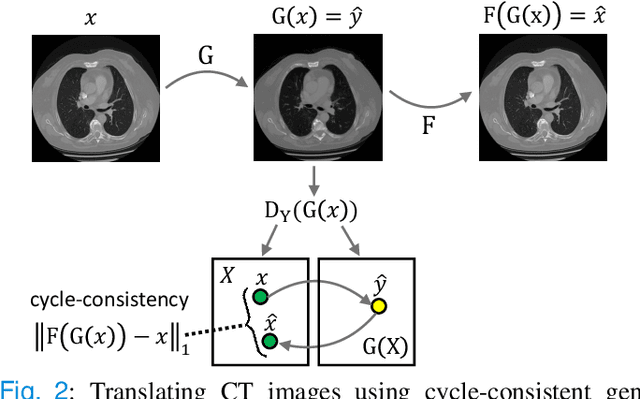
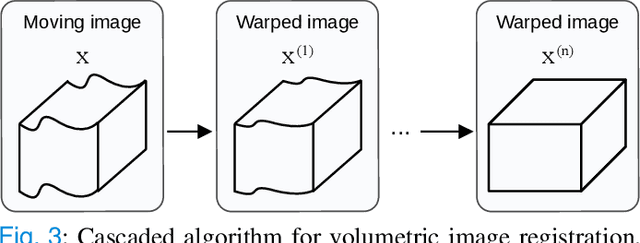
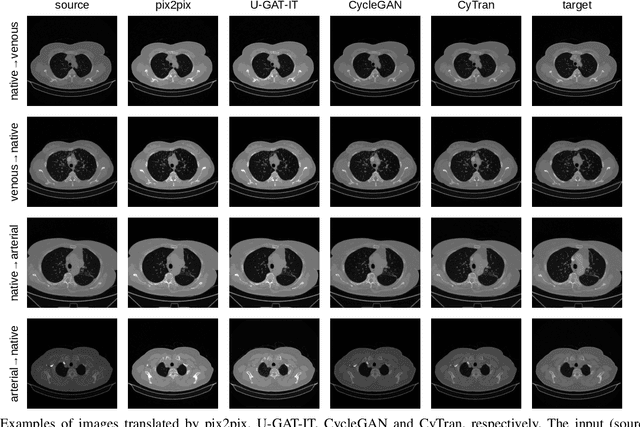
We propose a novel approach to translate unpaired contrast computed tomography (CT) scans to non-contrast CT scans and the other way around. Solving this task has two important applications: (i) to automatically generate contrast CT scans for patients for whom injecting contrast substance is not an option, and (ii) to enhance alignment between contrast and non-contrast CT by reducing the differences induced by the contrast substance before registration. Our approach is based on cycle-consistent generative adversarial convolutional transformers, for short, CyTran. Our neural model can be trained on unpaired images, due to the integration of a cycle-consistency loss. To deal with high-resolution images, we design a hybrid architecture based on convolutional and multi-head attention layers. In addition, we introduce a novel data set, Coltea-Lung-CT-100W, containing 3D triphasic lung CT scans (with a total of 37,290 images) collected from 100 female patients. Each scan contains three phases (non-contrast, early portal venous, and late arterial), allowing us to perform experiments to compare our novel approach with state-of-the-art methods for image style transfer. Our empirical results show that CyTran outperforms all competing methods. Moreover, we show that CyTran can be employed as a preliminary step to improve a state-of-the-art medical image alignment method. We release our novel model and data set as open source at: https://github.com/ristea/cycle-transformer.
Accurate and Efficient Intracranial Hemorrhage Detection and Subtype Classification in 3D CT Scans with Convolutional and Long Short-Term Memory Neural Networks
Aug 01, 2020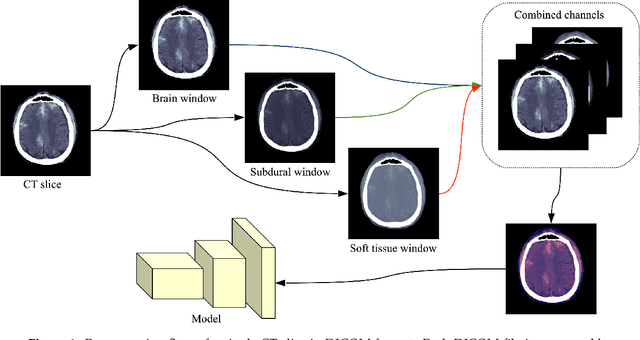
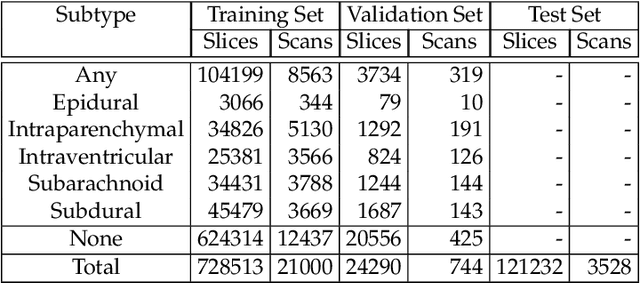
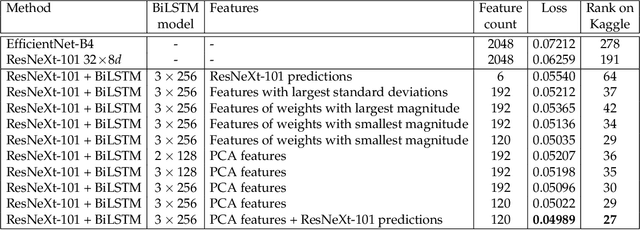
In this paper, we present our system for the RSNA Intracranial Hemorrhage Detection challenge. The proposed system is based on a lightweight deep neural network architecture composed of a convolutional neural network (CNN) that takes as input individual CT slices, and a Long Short-Term Memory (LSTM) network that takes as input feature embeddings provided by the CNN. For efficient processing, we consider various feature selection methods to produce a subset of useful CNN features for the LSTM. Furthermore, we reduce the CT slices by a factor of 2x, allowing ourselves to train the model faster. Even if our model is designed to balance speed and accuracy, we report a weighted mean log loss of 0.04989 on the final test set, which places us in the top 30 ranking (2%) from a total of 1345 participants. Although our computing infrastructure does not allow it, processing CT slices at their original scale is likely to improve performance. In order to enable others to reproduce our results, we provide our code as open source at https://github.com/warchildmd/ihd. After the challenge, we conducted a subjective intracranial hemorrhage detection assessment by radiologists, indicating that the performance of our deep model is on par with that of doctors specialized in reading CT scans. Another contribution of our work is to integrate Grad-CAM visualizations in our system, providing useful explanations for its predictions. We therefore consider our system as a viable option when a fast diagnosis or a second opinion on intracranial hemorrhage detection are needed.
Convolutional Neural Networks with Intermediate Loss for 3D Super-Resolution of CT and MRI Scans
Jan 05, 2020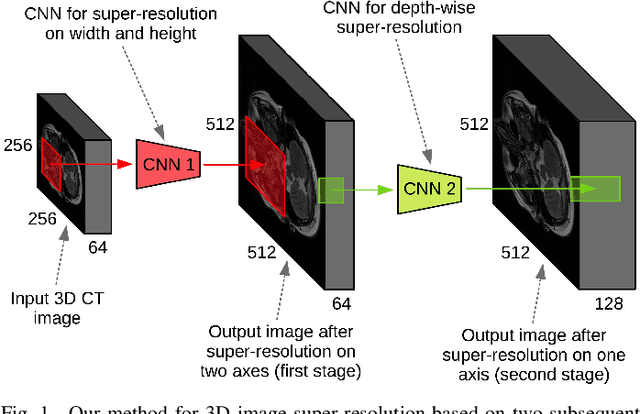

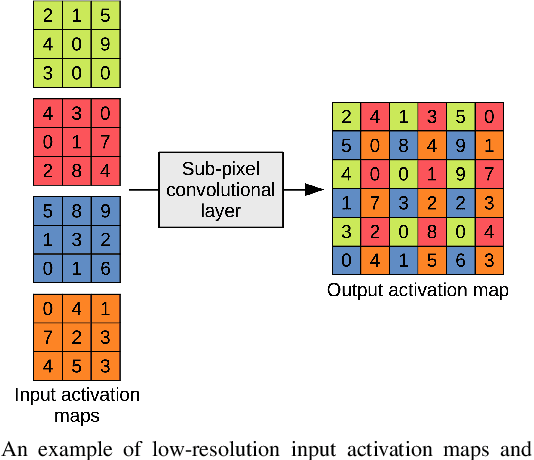
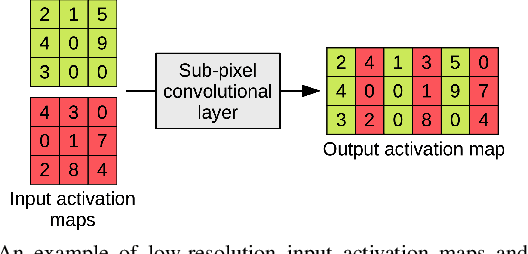
CT scanners that are commonly-used in hospitals nowadays produce low-resolution images, up to 512 pixels in size. One pixel in the image corresponds to a one millimeter piece of tissue. In order to accurately segment tumors and make treatment plans, doctors need CT scans of higher resolution. The same problem appears in MRI. In this paper, we propose an approach for the single-image super-resolution of 3D CT or MRI scans. Our method is based on deep convolutional neural networks (CNNs) composed of 10 convolutional layers and an intermediate upscaling layer that is placed after the first 6 convolutional layers. Our first CNN, which increases the resolution on two axes (width and height), is followed by a second CNN, which increases the resolution on the third axis (depth). Different from other methods, we compute the loss with respect to the ground-truth high-resolution output right after the upscaling layer, in addition to computing the loss after the last convolutional layer. The intermediate loss forces our network to produce a better output, closer to the ground-truth. A widely-used approach to obtain sharp results is to add Gaussian blur using a fixed standard deviation. In order to avoid overfitting to a fixed standard deviation, we apply Gaussian smoothing with various standard deviations, unlike other approaches. We evaluate our method in the context of 2D and 3D super-resolution of CT and MRI scans from two databases, comparing it to relevant related works from the literature and baselines based on various interpolation schemes, using 2x and 4x scaling factors. The empirical results show that our approach attains superior results to all other methods. Moreover, our human annotation study reveals that both doctors and regular annotators chose our method in favor of Lanczos interpolation in 97.55% cases for 2x upscaling factor and in 96.69% cases for 4x upscaling factor.