 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvolutional Neural Networks with Intermediate Loss for 3D Super-Resolution of CT and MRI Scans
Paper and Code
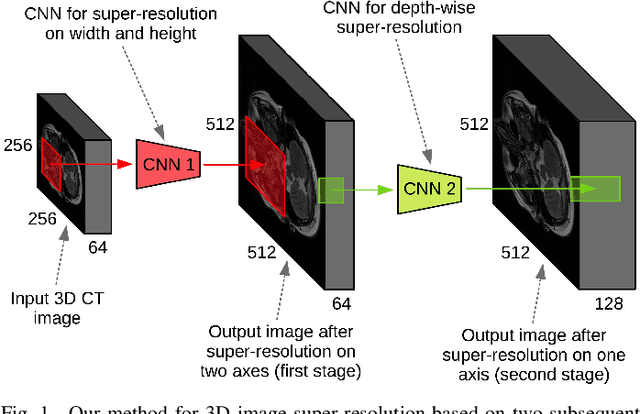

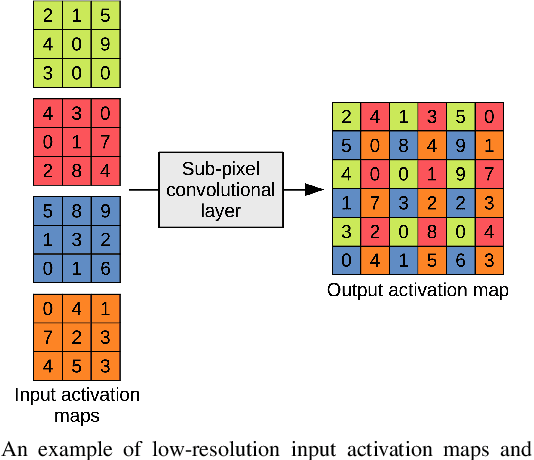
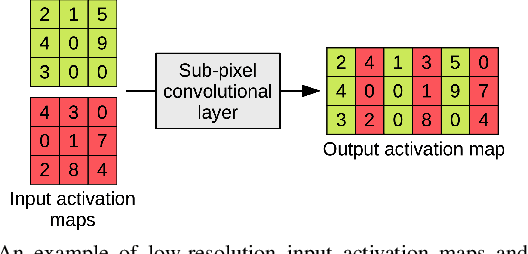
CT scanners that are commonly-used in hospitals nowadays produce low-resolution images, up to 512 pixels in size. One pixel in the image corresponds to a one millimeter piece of tissue. In order to accurately segment tumors and make treatment plans, doctors need CT scans of higher resolution. The same problem appears in MRI. In this paper, we propose an approach for the single-image super-resolution of 3D CT or MRI scans. Our method is based on deep convolutional neural networks (CNNs) composed of 10 convolutional layers and an intermediate upscaling layer that is placed after the first 6 convolutional layers. Our first CNN, which increases the resolution on two axes (width and height), is followed by a second CNN, which increases the resolution on the third axis (depth). Different from other methods, we compute the loss with respect to the ground-truth high-resolution output right after the upscaling layer, in addition to computing the loss after the last convolutional layer. The intermediate loss forces our network to produce a better output, closer to the ground-truth. A widely-used approach to obtain sharp results is to add Gaussian blur using a fixed standard deviation. In order to avoid overfitting to a fixed standard deviation, we apply Gaussian smoothing with various standard deviations, unlike other approaches. We evaluate our method in the context of 2D and 3D super-resolution of CT and MRI scans from two databases, comparing it to relevant related works from the literature and baselines based on various interpolation schemes, using 2x and 4x scaling factors. The empirical results show that our approach attains superior results to all other methods. Moreover, our human annotation study reveals that both doctors and regular annotators chose our method in favor of Lanczos interpolation in 97.55% cases for 2x upscaling factor and in 96.69% cases for 4x upscaling factor.