 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAether Weaver: Multimodal Affective Narrative Co-Generation with Dynamic Scene Graphs
Jul 29, 2025We introduce Aether Weaver, a novel, integrated framework for multimodal narrative co-generation that overcomes limitations of sequential text-to-visual pipelines. Our system concurrently synthesizes textual narratives, dynamic scene graph representations, visual scenes, and affective soundscapes, driven by a tightly integrated, co-generation mechanism. At its core, the Narrator, a large language model, generates narrative text and multimodal prompts, while the Director acts as a dynamic scene graph manager, and analyzes the text to build and maintain a structured representation of the story's world, ensuring spatio-temporal and relational consistency for visual rendering and subsequent narrative generation. Additionally, a Narrative Arc Controller guides the high-level story structure, influencing multimodal affective consistency, further complemented by an Affective Tone Mapper that ensures congruent emotional expression across all modalities. Through qualitative evaluations on a diverse set of narrative prompts encompassing various genres, we demonstrate that Aether Weaver significantly enhances narrative depth, visual fidelity, and emotional resonance compared to cascaded baseline approaches. This integrated framework provides a robust platform for rapid creative prototyping and immersive storytelling experiences.
UPose3D: Uncertainty-Aware 3D Human Pose Estimation with Cross-View and Temporal Cues
Apr 23, 2024We introduce UPose3D, a novel approach for multi-view 3D human pose estimation, addressing challenges in accuracy and scalability. Our method advances existing pose estimation frameworks by improving robustness and flexibility without requiring direct 3D annotations. At the core of our method, a pose compiler module refines predictions from a 2D keypoints estimator that operates on a single image by leveraging temporal and cross-view information. Our novel cross-view fusion strategy is scalable to any number of cameras, while our synthetic data generation strategy ensures generalization across diverse actors, scenes, and viewpoints. Finally, UPose3D leverages the prediction uncertainty of both the 2D keypoint estimator and the pose compiler module. This provides robustness to outliers and noisy data, resulting in state-of-the-art performance in out-of-distribution settings. In addition, for in-distribution settings, UPose3D yields a performance rivaling methods that rely on 3D annotated data, while being the state-of-the-art among methods relying only on 2D supervision.
SkelFormer: Markerless 3D Pose and Shape Estimation using Skeletal Transformers
Apr 19, 2024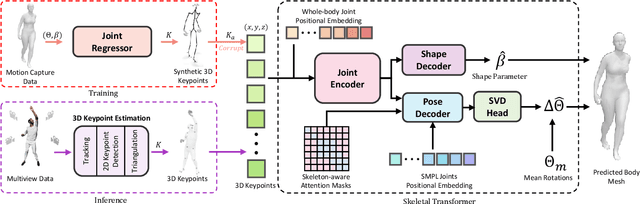
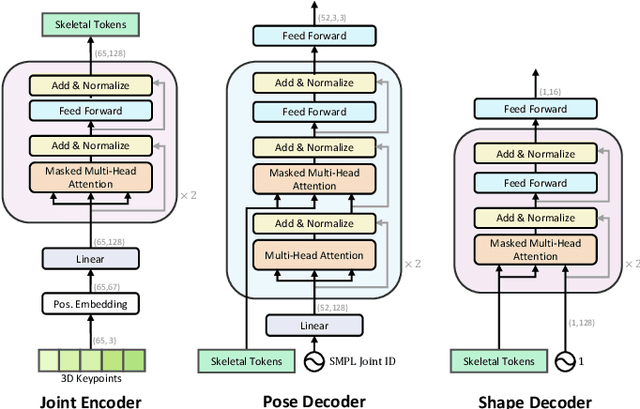

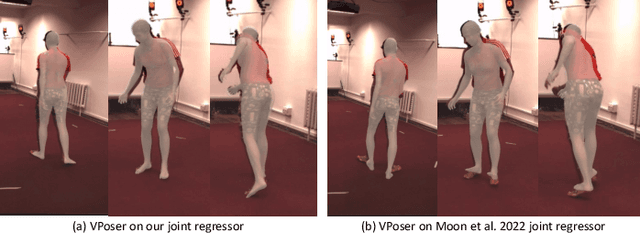
We introduce SkelFormer, a novel markerless motion capture pipeline for multi-view human pose and shape estimation. Our method first uses off-the-shelf 2D keypoint estimators, pre-trained on large-scale in-the-wild data, to obtain 3D joint positions. Next, we design a regression-based inverse-kinematic skeletal transformer that maps the joint positions to pose and shape representations from heavily noisy observations. This module integrates prior knowledge about pose space and infers the full pose state at runtime. Separating the 3D keypoint detection and inverse-kinematic problems, along with the expressive representations learned by our skeletal transformer, enhance the generalization of our method to unseen noisy data. We evaluate our method on three public datasets in both in-distribution and out-of-distribution settings using three datasets, and observe strong performance with respect to prior works. Moreover, ablation experiments demonstrate the impact of each of the modules of our architecture. Finally, we study the performance of our method in dealing with noise and heavy occlusions and find considerable robustness with respect to other solutions.
ZeroEGGS: Zero-shot Example-based Gesture Generation from Speech
Sep 23, 2022
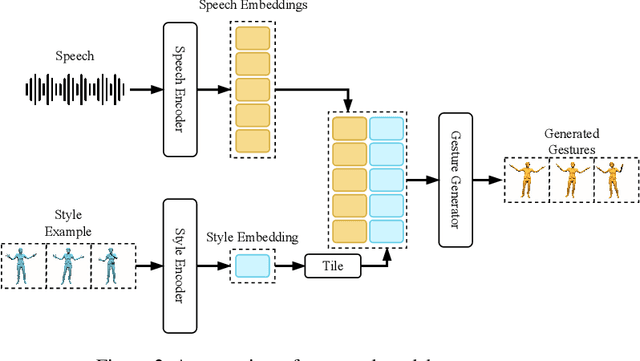

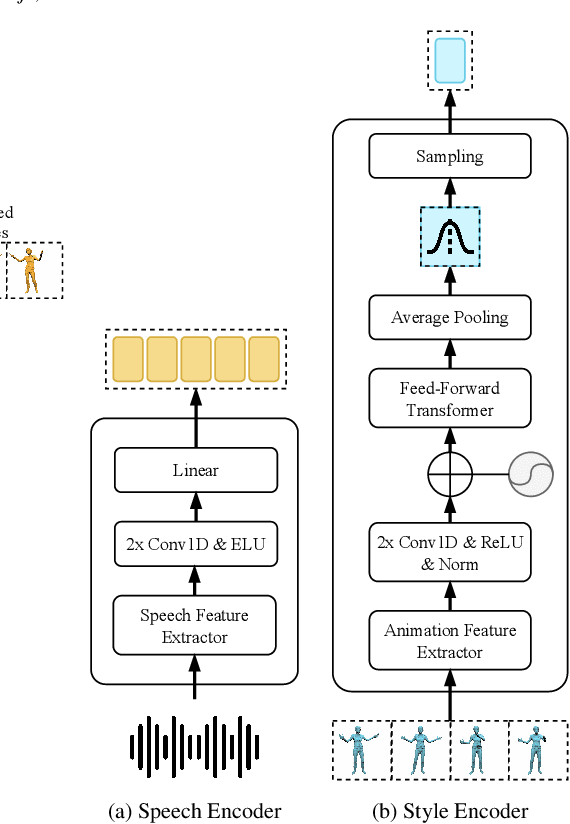
We present ZeroEGGS, a neural network framework for speech-driven gesture generation with zero-shot style control by example. This means style can be controlled via only a short example motion clip, even for motion styles unseen during training. Our model uses a Variational framework to learn a style embedding, making it easy to modify style through latent space manipulation or blending and scaling of style embeddings. The probabilistic nature of our framework further enables the generation of a variety of outputs given the same input, addressing the stochastic nature of gesture motion. In a series of experiments, we first demonstrate the flexibility and generalizability of our model to new speakers and styles. In a user study, we then show that our model outperforms previous state-of-the-art techniques in naturalness of motion, appropriateness for speech, and style portrayal. Finally, we release a high-quality dataset of full-body gesture motion including fingers, with speech, spanning across 19 different styles.
Estimating Pose from Pressure Data for Smart Beds with Deep Image-based Pose Estimators
Jun 13, 2022In-bed pose estimation has shown value in fields such as hospital patient monitoring, sleep studies, and smart homes. In this paper, we explore different strategies for detecting body pose from highly ambiguous pressure data, with the aid of pre-existing pose estimators. We examine the performance of pre-trained pose estimators by using them either directly or by re-training them on two pressure datasets. We also explore other strategies utilizing a learnable pre-processing domain adaptation step, which transforms the vague pressure maps to a representation closer to the expected input space of common purpose pose estimation modules. Accordingly, we used a fully convolutional network with multiple scales to provide the pose-specific characteristics of the pressure maps to the pre-trained pose estimation module. Our complete analysis of different approaches shows that the combination of learnable pre-processing module along with re-training pre-existing image-based pose estimators on the pressure data is able to overcome issues such as highly vague pressure points to achieve very high pose estimation accuracy.
* The version of record of this article, first published in Applied Intelligence, is available online at Publisher's website https://doi.org/10.1007/s10489-021-02418-y. arXiv admin note: substantial text overlap with arXiv:1908.08919
Gait Recognition using Multi-Scale Partial Representation Transformation with Capsules
Oct 18, 2020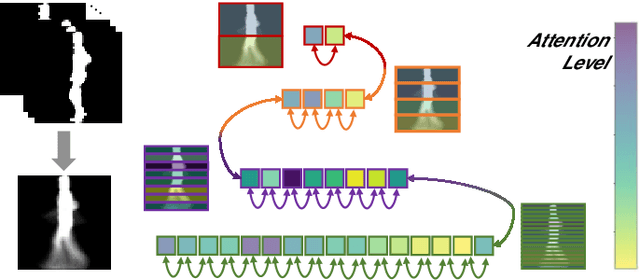
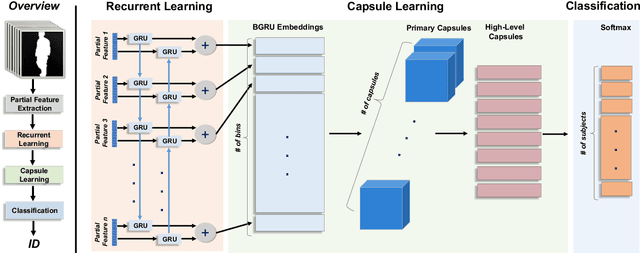

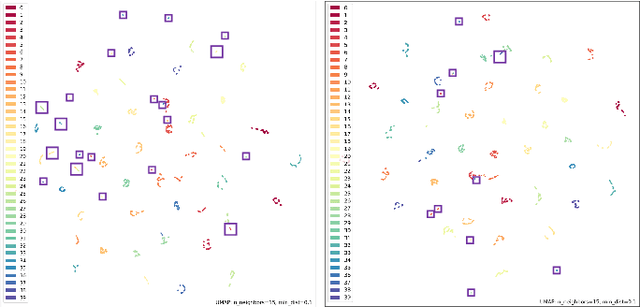
Gait recognition, referring to the identification of individuals based on the manner in which they walk, can be very challenging due to the variations in the viewpoint of the camera and the appearance of individuals. Current methods for gait recognition have been dominated by deep learning models, notably those based on partial feature representations. In this context, we propose a novel deep network, learning to transfer multi-scale partial gait representations using capsules to obtain more discriminative gait features. Our network first obtains multi-scale partial representations using a state-of-the-art deep partial feature extractor. It then recurrently learns the correlations and co-occurrences of the patterns among the partial features in forward and backward directions using Bi-directional Gated Recurrent Units (BGRU). Finally, a capsule network is adopted to learn deeper part-whole relationships and assigns more weights to the more relevant features while ignoring the spurious dimensions. That way, we obtain final features that are more robust to both viewing and appearance changes. The performance of our method has been extensively tested on two gait recognition datasets, CASIA-B and OU-MVLP, using four challenging test protocols. The results of our method have been compared to the state-of-the-art gait recognition solutions, showing the superiority of our model, notably when facing challenging viewing and carrying conditions.
MoVi: A Large Multipurpose Motion and Video Dataset
Mar 04, 2020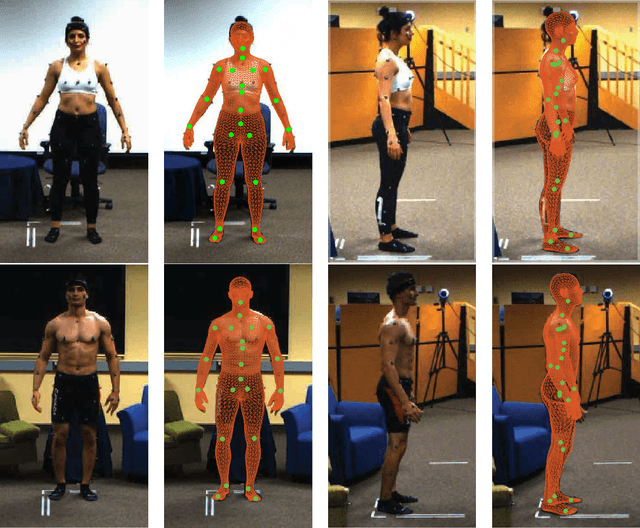
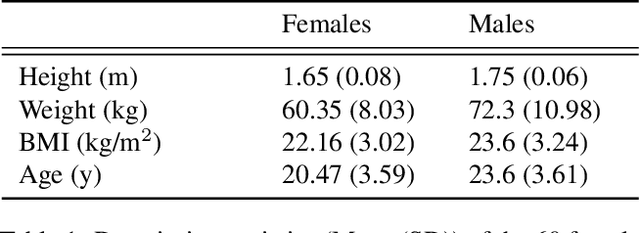
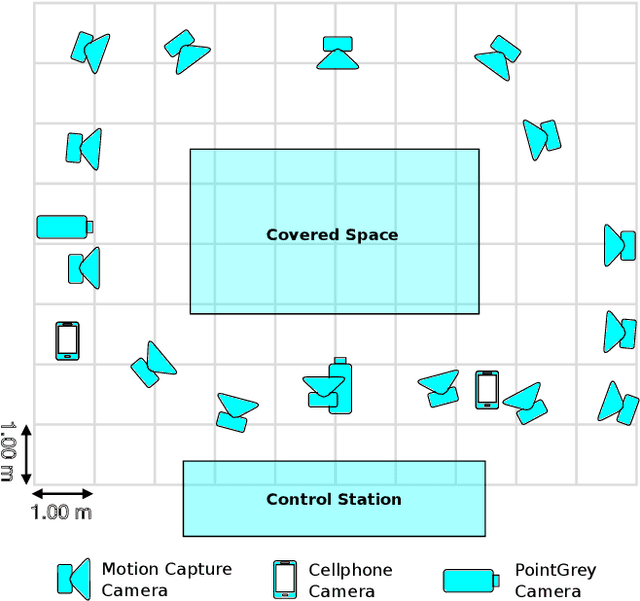
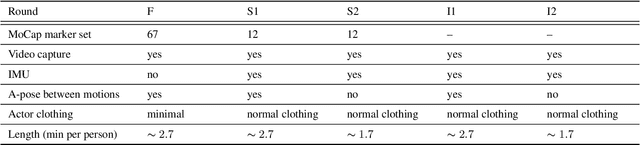
Human movements are both an area of intense study and the basis of many applications such as character animation. For many applications, it is crucial to identify movements from videos or analyze datasets of movements. Here we introduce a new human Motion and Video dataset MoVi, which we make available publicly. It contains 60 female and 30 male actors performing a collection of 20 predefined everyday actions and sports movements, and one self-chosen movement. In five capture rounds, the same actors and movements were recorded using different hardware systems, including an optical motion capture system, video cameras, and inertial measurement units (IMU). For some of the capture rounds, the actors were recorded when wearing natural clothing, for the other rounds they wore minimal clothing. In total, our dataset contains 9 hours of motion capture data, 17 hours of video data from 4 different points of view (including one hand-held camera), and 6.6 hours of IMU data. In this paper, we describe how the dataset was collected and post-processed; We present state-of-the-art estimates of skeletal motions and full-body shape deformations associated with skeletal motion. We discuss examples for potential studies this dataset could enable.
In-bed Pressure-based Pose Estimation using Image Space Representation Learning
Aug 21, 2019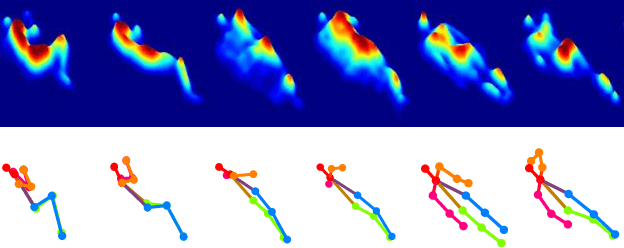

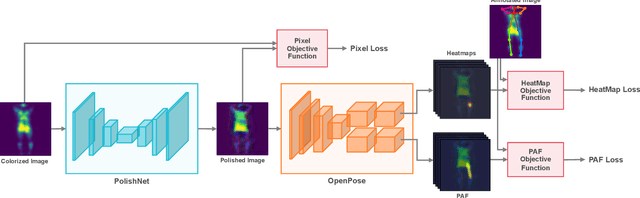

In-bed pose estimation has shown value in fields such as hospital patient monitoring, sleep studies, and smart homes. In this paper, we present a novel in-bed pressure-based pose estimation approach capable of accurately detecting body parts from highly ambiguous pressure data. We exploit the idea of using a learnable pre-processing step, which transforms the vague pressure maps to a representation close to the expected input space of common purpose pose identification modules, which fail if solely used on the pressure data. To this end, a fully convolutional network with multiple scales is used as the learnable pre-processing step to provide the pose-specific characteristics of the pressure maps to the pre-trained pose identification module. A combination of loss functions is used to model the constraints, ensuring that unclear body parts are reconstructed correctly while preventing the pre-processing block from generating arbitrary images. The evaluation results show high visual fidelity in the generated pre-processed images as well as high detection rates in pose estimation. Furthermore, we show that the trained pre-processing block can be effective for pose identification models for which it has not been trained as well.
Auto-labelling of Markers in Optical Motion Capture by Permutation Learning
Jul 31, 2019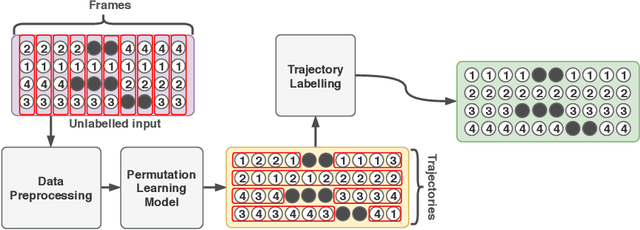

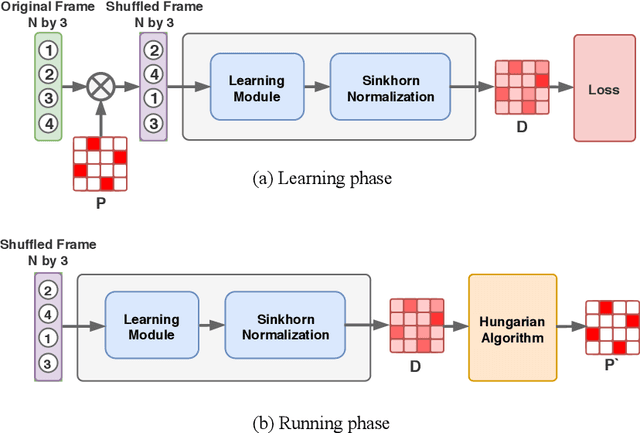
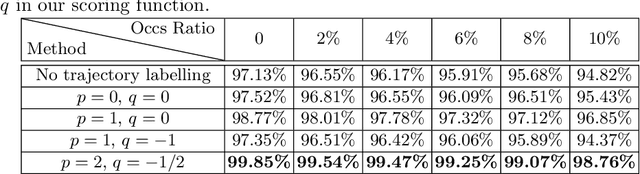
Optical marker-based motion capture is a vital tool in applications such as motion and behavioural analysis, animation, and biomechanics. Labelling, that is, assigning optical markers to the pre-defined positions on the body is a time consuming and labour intensive postprocessing part of current motion capture pipelines. The problem can be considered as a ranking process in which markers shuffled by an unknown permutation matrix are sorted to recover the correct order. In this paper, we present a framework for automatic marker labelling which first estimates a permutation matrix for each individual frame using a differentiable permutation learning model and then utilizes temporal consistency to identify and correct remaining labelling errors. Experiments conducted on the test data show the effectiveness of our framework.