 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUPose3D: Uncertainty-Aware 3D Human Pose Estimation with Cross-View and Temporal Cues
Apr 23, 2024We introduce UPose3D, a novel approach for multi-view 3D human pose estimation, addressing challenges in accuracy and scalability. Our method advances existing pose estimation frameworks by improving robustness and flexibility without requiring direct 3D annotations. At the core of our method, a pose compiler module refines predictions from a 2D keypoints estimator that operates on a single image by leveraging temporal and cross-view information. Our novel cross-view fusion strategy is scalable to any number of cameras, while our synthetic data generation strategy ensures generalization across diverse actors, scenes, and viewpoints. Finally, UPose3D leverages the prediction uncertainty of both the 2D keypoint estimator and the pose compiler module. This provides robustness to outliers and noisy data, resulting in state-of-the-art performance in out-of-distribution settings. In addition, for in-distribution settings, UPose3D yields a performance rivaling methods that rely on 3D annotated data, while being the state-of-the-art among methods relying only on 2D supervision.
SkelFormer: Markerless 3D Pose and Shape Estimation using Skeletal Transformers
Apr 19, 2024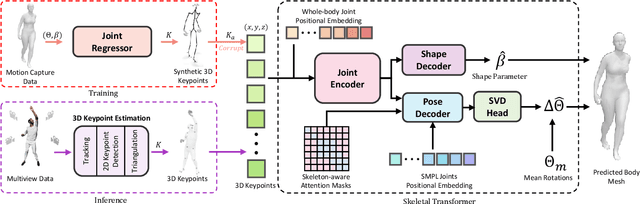
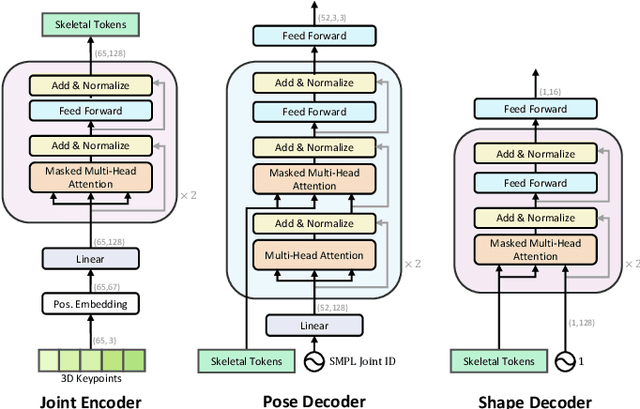

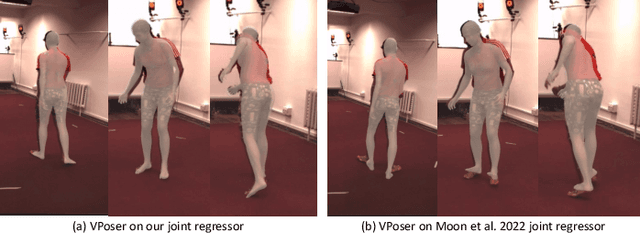
We introduce SkelFormer, a novel markerless motion capture pipeline for multi-view human pose and shape estimation. Our method first uses off-the-shelf 2D keypoint estimators, pre-trained on large-scale in-the-wild data, to obtain 3D joint positions. Next, we design a regression-based inverse-kinematic skeletal transformer that maps the joint positions to pose and shape representations from heavily noisy observations. This module integrates prior knowledge about pose space and infers the full pose state at runtime. Separating the 3D keypoint detection and inverse-kinematic problems, along with the expressive representations learned by our skeletal transformer, enhance the generalization of our method to unseen noisy data. We evaluate our method on three public datasets in both in-distribution and out-of-distribution settings using three datasets, and observe strong performance with respect to prior works. Moreover, ablation experiments demonstrate the impact of each of the modules of our architecture. Finally, we study the performance of our method in dealing with noise and heavy occlusions and find considerable robustness with respect to other solutions.