 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkelFormer: Markerless 3D Pose and Shape Estimation using Skeletal Transformers
Paper and Code
Apr 19, 2024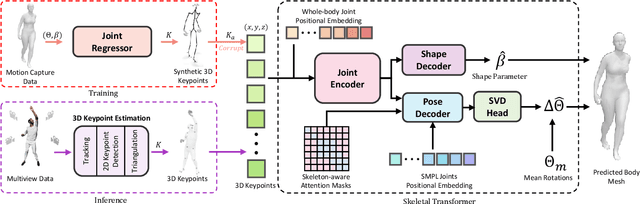
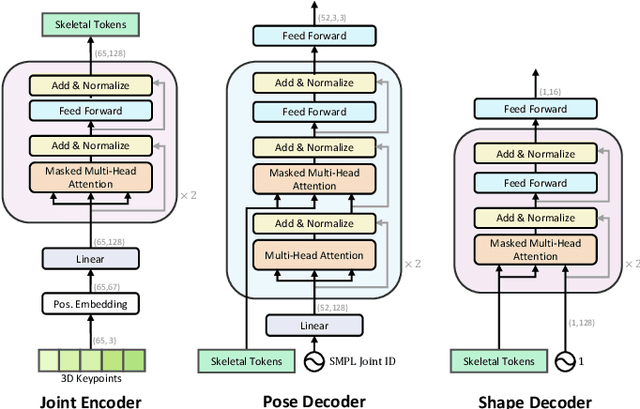

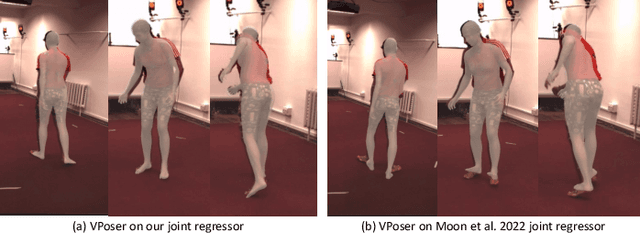
We introduce SkelFormer, a novel markerless motion capture pipeline for multi-view human pose and shape estimation. Our method first uses off-the-shelf 2D keypoint estimators, pre-trained on large-scale in-the-wild data, to obtain 3D joint positions. Next, we design a regression-based inverse-kinematic skeletal transformer that maps the joint positions to pose and shape representations from heavily noisy observations. This module integrates prior knowledge about pose space and infers the full pose state at runtime. Separating the 3D keypoint detection and inverse-kinematic problems, along with the expressive representations learned by our skeletal transformer, enhance the generalization of our method to unseen noisy data. We evaluate our method on three public datasets in both in-distribution and out-of-distribution settings using three datasets, and observe strong performance with respect to prior works. Moreover, ablation experiments demonstrate the impact of each of the modules of our architecture. Finally, we study the performance of our method in dealing with noise and heavy occlusions and find considerable robustness with respect to other solutions.