 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkullptor: High Fidelity 3D Head Reconstruction in Seconds with Multi-View Normal Prediction
Feb 24, 2026Reconstructing high-fidelity 3D head geometry from images is critical for a wide range of applications, yet existing methods face fundamental limitations. Traditional photogrammetry achieves exceptional detail but requires extensive camera arrays (25-200+ views), substantial computation, and manual cleanup in challenging areas like facial hair. Recent alternatives present a fundamental trade-off: foundation models enable efficient single-image reconstruction but lack fine geometric detail, while optimization-based methods achieve higher fidelity but require dense views and expensive computation. We bridge this gap with a hybrid approach that combines the strengths of both paradigms. Our method introduces a multi-view surface normal prediction model that extends monocular foundation models with cross-view attention to produce geometrically consistent normals in a feed-forward pass. We then leverage these predictions as strong geometric priors within an inverse rendering optimization framework to recover high-frequency surface details. Our approach outperforms state-of-the-art single-image and multi-view methods, achieving high-fidelity reconstruction on par with dense-view photogrammetry while reducing camera requirements and computational cost. The code and model will be released.
Geometry-Aware Texture Generation for 3D Head Modeling with Artist-driven Control
May 07, 2025Creating realistic 3D head assets for virtual characters that match a precise artistic vision remains labor-intensive. We present a novel framework that streamlines this process by providing artists with intuitive control over generated 3D heads. Our approach uses a geometry-aware texture synthesis pipeline that learns correlations between head geometry and skin texture maps across different demographics. The framework offers three levels of artistic control: manipulation of overall head geometry, adjustment of skin tone while preserving facial characteristics, and fine-grained editing of details such as wrinkles or facial hair. Our pipeline allows artists to make edits to a single texture map using familiar tools, with our system automatically propagating these changes coherently across the remaining texture maps needed for realistic rendering. Experiments demonstrate that our method produces diverse results with clean geometries. We showcase practical applications focusing on intuitive control for artists, including skin tone adjustments and simplified editing workflows for adding age-related details or removing unwanted features from scanned models. This integrated approach aims to streamline the artistic workflow in virtual character creation.
SEREP: Semantic Facial Expression Representation for Robust In-the-Wild Capture and Retargeting
Dec 18, 2024Monocular facial performance capture in-the-wild is challenging due to varied capture conditions, face shapes, and expressions. Most current methods rely on linear 3D Morphable Models, which represent facial expressions independently of identity at the vertex displacement level. We propose SEREP (Semantic Expression Representation), a model that disentangles expression from identity at the semantic level. It first learns an expression representation from unpaired 3D facial expressions using a cycle consistency loss. Then we train a model to predict expression from monocular images using a novel semi-supervised scheme that relies on domain adaptation. In addition, we introduce MultiREX, a benchmark addressing the lack of evaluation resources for the expression capture task. Our experiments show that SEREP outperforms state-of-the-art methods, capturing challenging expressions and transferring them to novel identities.
MoSAR: Monocular Semi-Supervised Model for Avatar Reconstruction using Differentiable Shading
Dec 22, 2023



Reconstructing an avatar from a portrait image has many applications in multimedia, but remains a challenging research problem. Extracting reflectance maps and geometry from one image is ill-posed: recovering geometry is a one-to-many mapping problem and reflectance and light are difficult to disentangle. Accurate geometry and reflectance can be captured under the controlled conditions of a light stage, but it is costly to acquire large datasets in this fashion. Moreover, training solely with this type of data leads to poor generalization with in-the-wild images. This motivates the introduction of MoSAR, a method for 3D avatar generation from monocular images. We propose a semi-supervised training scheme that improves generalization by learning from both light stage and in-the-wild datasets. This is achieved using a novel differentiable shading formulation. We show that our approach effectively disentangles the intrinsic face parameters, producing relightable avatars. As a result, MoSAR estimates a richer set of skin reflectance maps, and generates more realistic avatars than existing state-of-the-art methods. We also introduce a new dataset, named FFHQ-UV-Intrinsics, the first public dataset providing intrinsic face attributes at scale (diffuse, specular, ambient occlusion and translucency maps) for a total of 10k subjects. The project website and the dataset are available on the following link: https://ubisoft-laforge.github.io/character/mosar/
S2F2: Self-Supervised High Fidelity Face Reconstruction from Monocular Image
Apr 05, 2022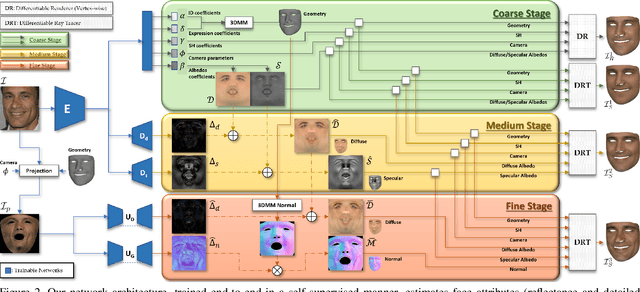


We present a novel face reconstruction method capable of reconstructing detailed face geometry, spatially varying face reflectance from a single monocular image. We build our work upon the recent advances of DNN-based auto-encoders with differentiable ray tracing image formation, trained in self-supervised manner. While providing the advantage of learning-based approaches and real-time reconstruction, the latter methods lacked fidelity. In this work, we achieve, for the first time, high fidelity face reconstruction using self-supervised learning only. Our novel coarse-to-fine deep architecture allows us to solve the challenging problem of decoupling face reflectance from geometry using a single image, at high computational speed. Compared to state-of-the-art methods, our method achieves more visually appealing reconstruction.
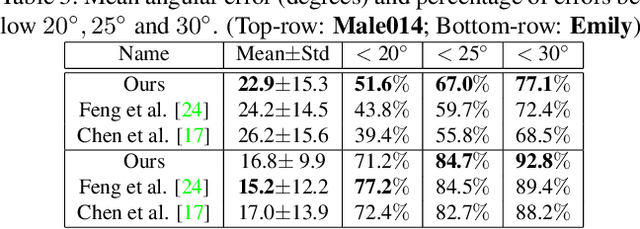
Towards High Fidelity Monocular Face Reconstruction with Rich Reflectance using Self-supervised Learning and Ray Tracing
Mar 29, 2021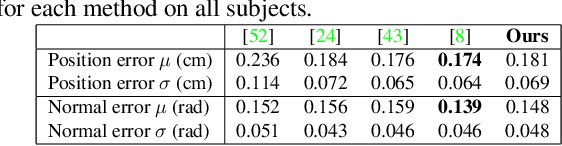
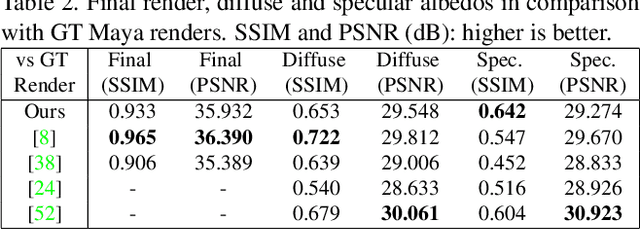
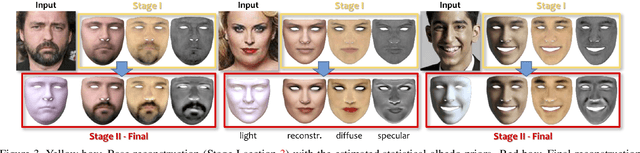
Robust face reconstruction from monocular image in general lighting conditions is challenging. Methods combining deep neural network encoders with differentiable rendering have opened up the path for very fast monocular reconstruction of geometry, lighting and reflectance. They can also be trained in self-supervised manner for increased robustness and better generalization. However, their differentiable rasterization based image formation models, as well as underlying scene parameterization, limit them to Lambertian face reflectance and to poor shape details. More recently, ray tracing was introduced for monocular face reconstruction within a classic optimization-based framework and enables state-of-the art results. However optimization-based approaches are inherently slow and lack robustness. In this paper, we build our work on the aforementioned approaches and propose a new method that greatly improves reconstruction quality and robustness in general scenes. We achieve this by combining a CNN encoder with a differentiable ray tracer, which enables us to base the reconstruction on much more advanced personalized diffuse and specular albedos, a more sophisticated illumination model and a plausible representation of self-shadows. This enables to take a big leap forward in reconstruction quality of shape, appearance and lighting even in scenes with difficult illumination. With consistent face attributes reconstruction, our method leads to practical applications such as relighting and self-shadows removal. Compared to state-of-the-art methods, our results show improved accuracy and validity of the approach.
PhotoApp: Photorealistic Appearance Editing of Head Portraits
Mar 13, 2021
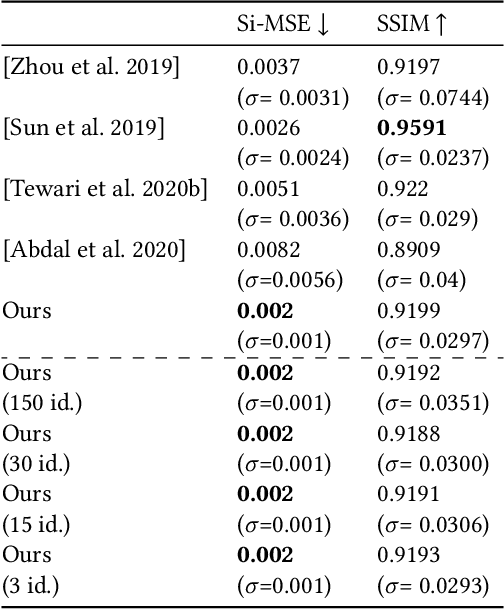
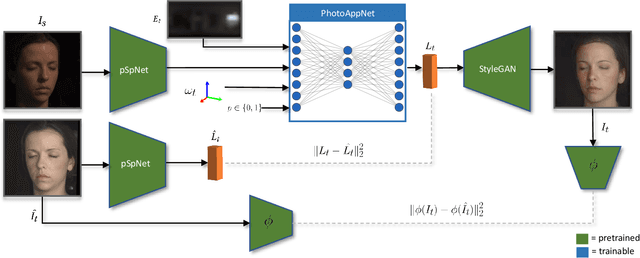
Photorealistic editing of portraits is a challenging task as humans are very sensitive to inconsistencies in faces. We present an approach for high-quality intuitive editing of the camera viewpoint and scene illumination in a portrait image. This requires our method to capture and control the full reflectance field of the person in the image. Most editing approaches rely on supervised learning using training data captured with setups such as light and camera stages. Such datasets are expensive to acquire, not readily available and do not capture all the rich variations of in-the-wild portrait images. In addition, most supervised approaches only focus on relighting, and do not allow camera viewpoint editing. Thus, they only capture and control a subset of the reflectance field. Recently, portrait editing has been demonstrated by operating in the generative model space of StyleGAN. While such approaches do not require direct supervision, there is a significant loss of quality when compared to the supervised approaches. In this paper, we present a method which learns from limited supervised training data. The training images only include people in a fixed neutral expression with eyes closed, without much hair or background variations. Each person is captured under 150 one-light-at-a-time conditions and under 8 camera poses. Instead of training directly in the image space, we design a supervised problem which learns transformations in the latent space of StyleGAN. This combines the best of supervised learning and generative adversarial modeling. We show that the StyleGAN prior allows for generalisation to different expressions, hairstyles and backgrounds. This produces high-quality photorealistic results for in-the-wild images and significantly outperforms existing methods. Our approach can edit the illumination and pose simultaneously, and runs at interactive rates.
Practical Face Reconstruction via Differentiable Ray Tracing
Jan 13, 2021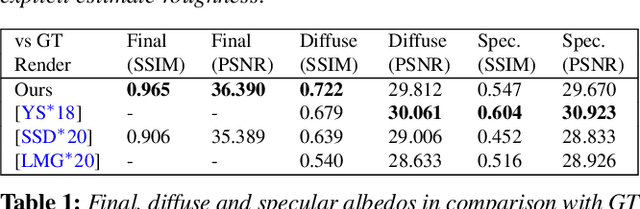
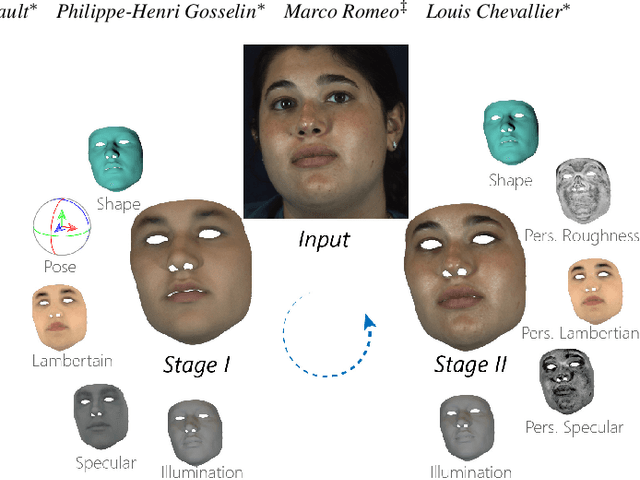
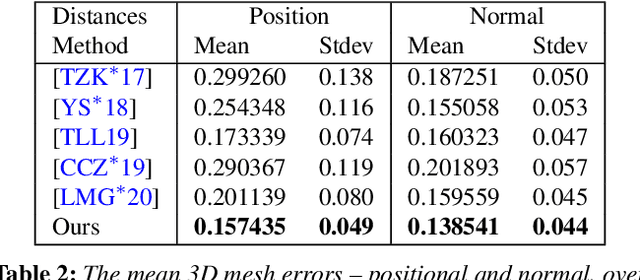
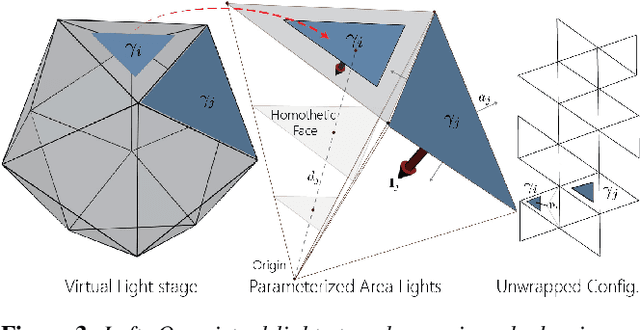
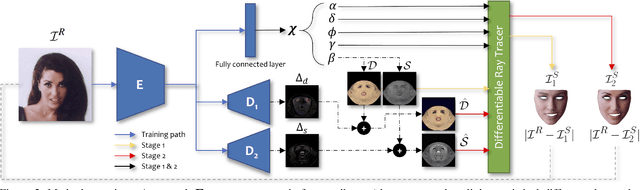
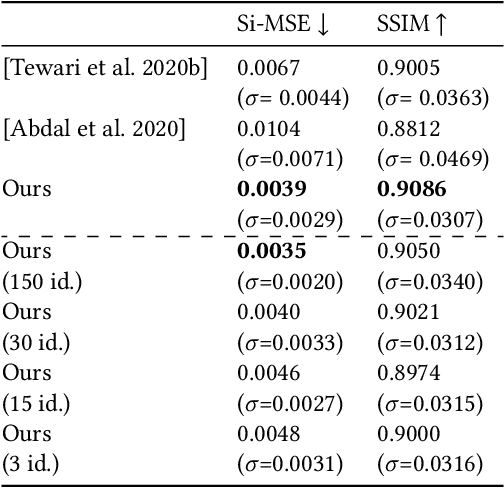
We present a differentiable ray-tracing based novel face reconstruction approach where scene attributes - 3D geometry, reflectance (diffuse, specular and roughness), pose, camera parameters, and scene illumination - are estimated from unconstrained monocular images. The proposed method models scene illumination via a novel, parameterized virtual light stage, which in-conjunction with differentiable ray-tracing, introduces a coarse-to-fine optimization formulation for face reconstruction. Our method can not only handle unconstrained illumination and self-shadows conditions, but also estimates diffuse and specular albedos. To estimate the face attributes consistently and with practical semantics, a two-stage optimization strategy systematically uses a subset of parametric attributes, where subsequent attribute estimations factor those previously estimated. For example, self-shadows estimated during the first stage, later prevent its baking into the personalized diffuse and specular albedos in the second stage. We show the efficacy of our approach in several real-world scenarios, where face attributes can be estimated even under extreme illumination conditions. Ablation studies, analyses and comparisons against several recent state-of-the-art methods show improved accuracy and versatility of our approach. With consistent face attributes reconstruction, our method leads to several style -- illumination, albedo, self-shadow -- edit and transfer applications, as discussed in the paper.
Face Reflectance and Geometry Modeling via Differentiable Ray Tracing
Oct 03, 2019
We present a novel strategy to automatically reconstruct 3D faces from monocular images with explicitly disentangled facial geometry (pose, identity and expression), reflectance (diffuse and specular albedo), and self-shadows. The scene lights are modeled as a virtual light stage with pre-oriented area lights used in conjunction with differentiable Monte-Carlo ray tracing to optimize the scene and face parameters. With correctly disentangled self-shadows and specular reflection parameters, we can not only obtain robust facial geometry reconstruction, but also gain explicit control over these parameters, with several practical applications. We can change facial expressions with accurate resultant self-shadows or relight the scene and obtain accurate specular reflection and several other parameter combinations.