 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge$\textit{FacialFilmroll}$: High-resolution multi-shot video editing
Oct 05, 2021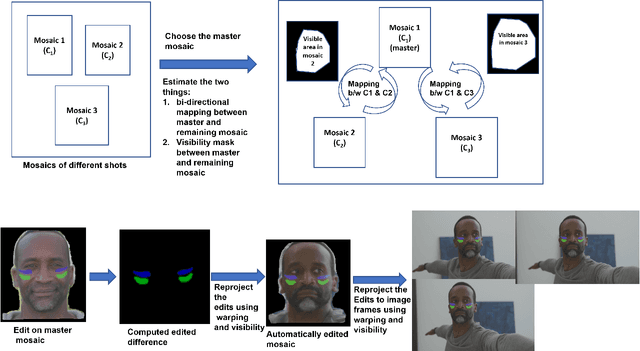
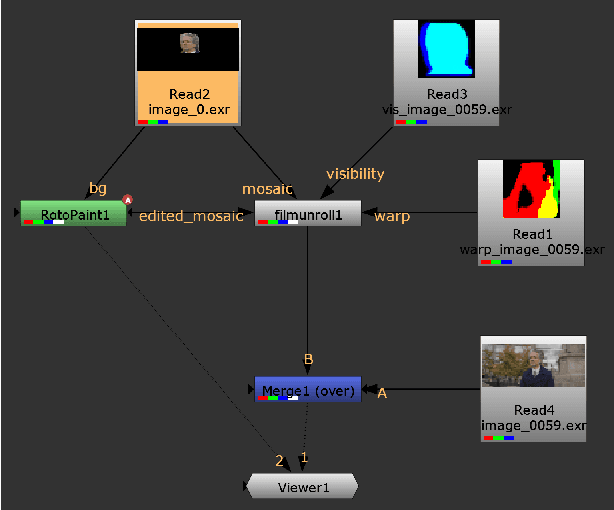


We present $\textit{FacialFilmroll}$, a solution for spatially and temporally consistent editing of faces in one or multiple shots. We build upon unwrap mosaic [Rav-Acha et al. 2008] by specializing it to faces. We leverage recent techniques to fit a 3D face model on monocular videos to (i) improve the quality of the mosaic for edition and (ii) permit the automatic transfer of edits from one shot to other shots of the same actor. We explain how $\textit{FacialFilmroll}$ is integrated in post-production facility. Finally, we present video editing results using $\textit{FacialFilmroll}$ on high resolution videos.
* European Conference on Visual Media Production (CVMP '21)
Practical Face Reconstruction via Differentiable Ray Tracing
Jan 13, 2021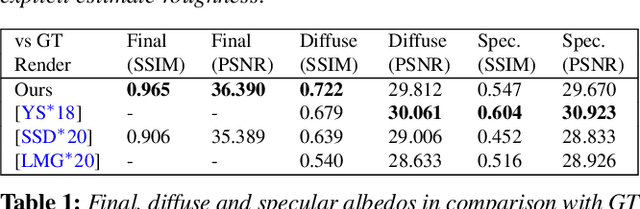
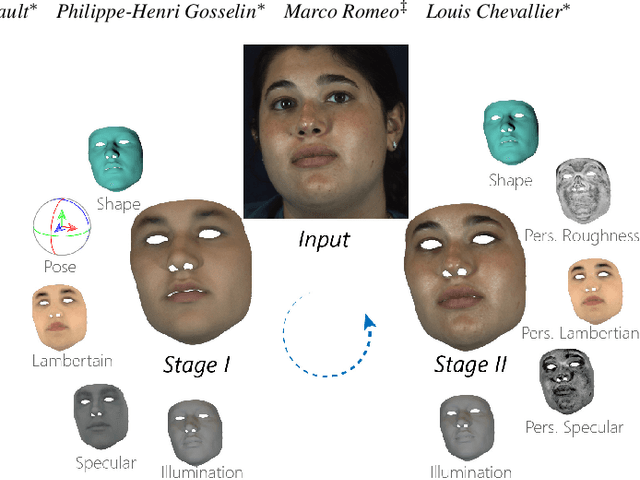
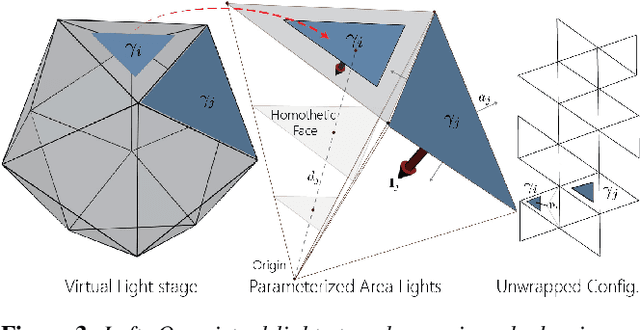
We present a differentiable ray-tracing based novel face reconstruction approach where scene attributes - 3D geometry, reflectance (diffuse, specular and roughness), pose, camera parameters, and scene illumination - are estimated from unconstrained monocular images. The proposed method models scene illumination via a novel, parameterized virtual light stage, which in-conjunction with differentiable ray-tracing, introduces a coarse-to-fine optimization formulation for face reconstruction. Our method can not only handle unconstrained illumination and self-shadows conditions, but also estimates diffuse and specular albedos. To estimate the face attributes consistently and with practical semantics, a two-stage optimization strategy systematically uses a subset of parametric attributes, where subsequent attribute estimations factor those previously estimated. For example, self-shadows estimated during the first stage, later prevent its baking into the personalized diffuse and specular albedos in the second stage. We show the efficacy of our approach in several real-world scenarios, where face attributes can be estimated even under extreme illumination conditions. Ablation studies, analyses and comparisons against several recent state-of-the-art methods show improved accuracy and versatility of our approach. With consistent face attributes reconstruction, our method leads to several style -- illumination, albedo, self-shadow -- edit and transfer applications, as discussed in the paper.
JUMPS: Joints Upsampling Method for Pose Sequences
Jul 03, 2020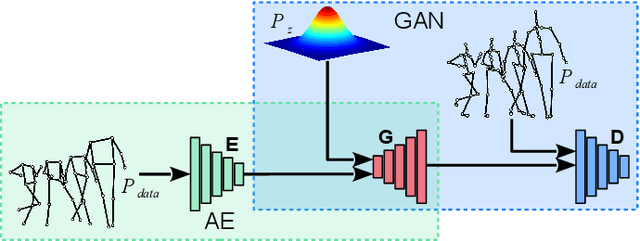
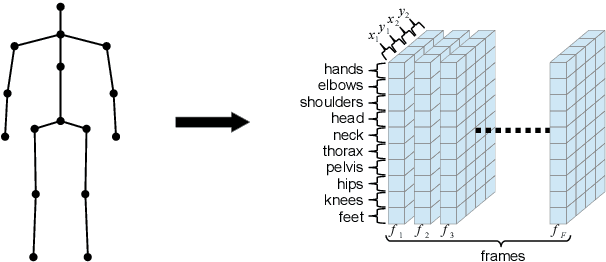
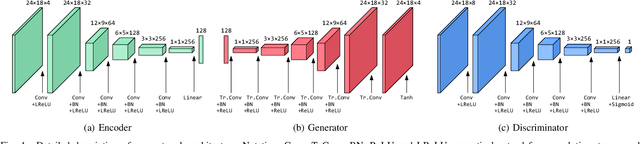
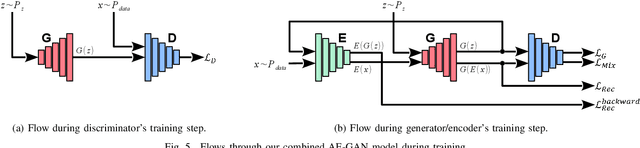
Human Pose Estimation is a low-level task useful for surveillance, human action recognition, and scene understanding at large. It also offers promising perspectives for the animation of synthetic characters. For all these applications, and especially the latter, estimating the positions of many joints is desirable for improved performance and realism. To this purpose, we propose a novel method called JUMPS for increasing the number of joints in 2D pose estimates and recovering occluded or missing joints. We believe this is the first attempt to address the issue. We build on a deep generative model that combines a GAN and an encoder. The GAN learns the distribution of high-resolution human pose sequences, the encoder maps the input low-resolution sequences to its latent space. Inpainting is obtained by computing the latent representation whose decoding by the GAN generator optimally matches the joints locations at the input. Post-processing a 2D pose sequence using our method provides a richer representation of the character motion. We show experimentally that the localization accuracy of the additional joints is on average on par with the original pose estimates.