 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD-Garment: Physics-Conditioned Latent Diffusion for Dynamic Garment Deformations
Apr 04, 2025Adjusting and deforming 3D garments to body shapes, body motion, and cloth material is an important problem in virtual and augmented reality. Applications are numerous, ranging from virtual change rooms to the entertainment and gaming industry. This problem is challenging as garment dynamics influence geometric details such as wrinkling patterns, which depend on physical input including the wearer's body shape and motion, as well as cloth material features. Existing work studies learning-based modeling techniques to generate garment deformations from example data, and physics-inspired simulators to generate realistic garment dynamics. We propose here a learning-based approach trained on data generated with a physics-based simulator. Compared to prior work, our 3D generative model learns garment deformations for loose cloth geometry, especially for large deformations and dynamic wrinkles driven by body motion and cloth material. Furthermore, the model can be efficiently fitted to observations captured using vision sensors. We propose to leverage the capability of diffusion models to learn fine-scale detail: we model the 3D garment in a 2D parameter space, and learn a latent diffusion model using this representation independent from the mesh resolution. This allows to condition global and local geometric information with body and material information. We quantitatively and qualitatively evaluate our method on both simulated data and data captured with a multi-view acquisition platform. Compared to strong baselines, our method is more accurate in terms of Chamfer distance.
Exploiting Latent Properties to Optimize Neural Codecs
Jan 02, 2025



End-to-end image and video codecs are becoming increasingly competitive, compared to traditional compression techniques that have been developed through decades of manual engineering efforts. These trainable codecs have many advantages over traditional techniques, such as their straightforward adaptation to perceptual distortion metrics and high performance in specific fields thanks to their learning ability. However, current state-of-the-art neural codecs do not fully exploit the benefits of vector quantization and the existence of the entropy gradient in decoding devices. In this paper, we propose to leverage these two properties (vector quantization and entropy gradient) to improve the performance of off-the-shelf codecs. Firstly, we demonstrate that using non-uniform scalar quantization cannot improve performance over uniform quantization. We thus suggest using predefined optimal uniform vector quantization to improve performance. Secondly, we show that the entropy gradient, available at the decoder, is correlated with the reconstruction error gradient, which is not available at the decoder. We therefore use the former as a proxy to enhance compression performance. Our experimental results show that these approaches save between 1 to 3% of the rate for the same quality across various pretrained methods. In addition, the entropy gradient based solution improves traditional codec performance significantly as well.
Improved Positional Encoding for Implicit Neural Representation based Compact Data Representation
Nov 10, 2023Positional encodings are employed to capture the high frequency information of the encoded signals in implicit neural representation (INR). In this paper, we propose a novel positional encoding method which improves the reconstruction quality of the INR. The proposed embedding method is more advantageous for the compact data representation because it has a greater number of frequency basis than the existing methods. Our experiments shows that the proposed method achieves significant gain in the rate-distortion performance without introducing any additional complexity in the compression task and higher reconstruction quality in novel view synthesis.
Latent-Shift: Gradient of Entropy Helps Neural Codecs
Aug 01, 2023
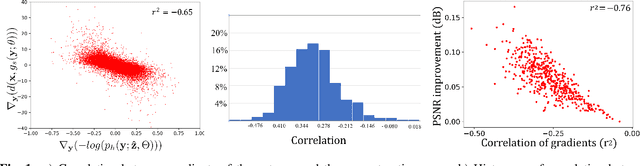
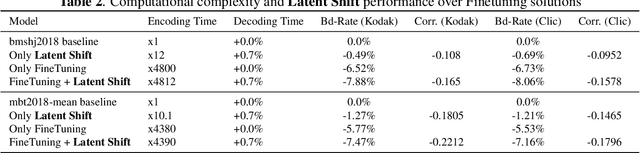
End-to-end image/video codecs are getting competitive compared to traditional compression techniques that have been developed through decades of manual engineering efforts. These trainable codecs have many advantages over traditional techniques such as easy adaptation on perceptual distortion metrics and high performance on specific domains thanks to their learning ability. However, state of the art neural codecs does not take advantage of the existence of gradient of entropy in decoding device. In this paper, we theoretically show that gradient of entropy (available at decoder side) is correlated with the gradient of the reconstruction error (which is not available at decoder side). We then demonstrate experimentally that this gradient can be used on various compression methods, leading to a $1-2\%$ rate savings for the same quality. Our method is orthogonal to other improvements and brings independent rate savings.
RQAT-INR: Improved Implicit Neural Image Compression
Mar 06, 2023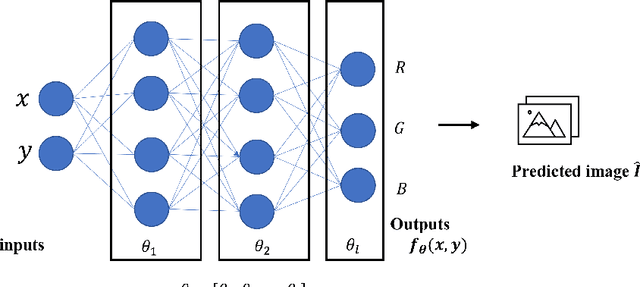
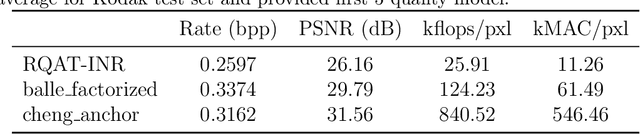
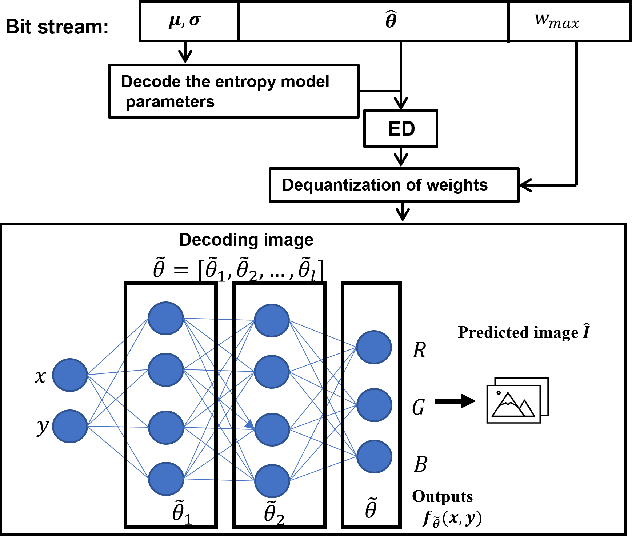
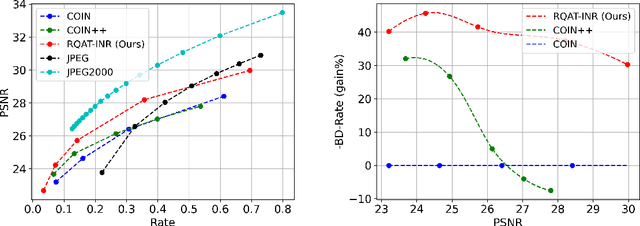
Deep variational autoencoders for image and video compression have gained significant attraction in the recent years, due to their potential to offer competitive or better compression rates compared to the decades long traditional codecs such as AVC, HEVC or VVC. However, because of complexity and energy consumption, these approaches are still far away from practical usage in industry. More recently, implicit neural representation (INR) based codecs have emerged, and have lower complexity and energy usage to classical approaches at decoding. However, their performances are not in par at the moment with state-of-the-art methods. In this research, we first show that INR based image codec has a lower complexity than VAE based approaches, then we propose several improvements for INR-based image codec and outperformed baseline model by a large margin.
Reducing The Mismatch Between Marginal and Learned Distributions in Neural Video Compression
Oct 12, 2022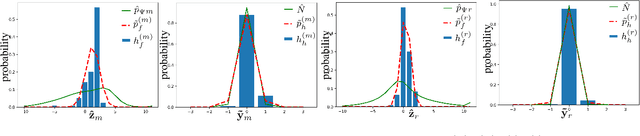
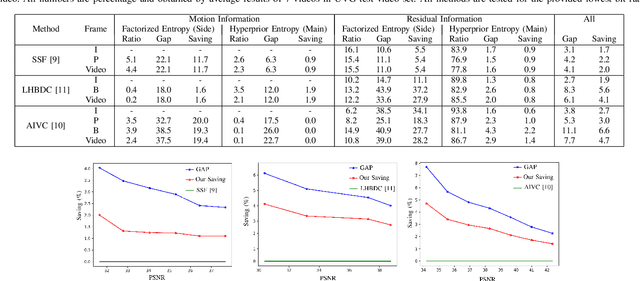
During the last four years, we have witnessed the success of end-to-end trainable models for image compression. Compared to decades of incremental work, these machine learning (ML) techniques learn all the components of the compression technique, which explains their actual superiority. However, end-to-end ML models have not yet reached the performance of traditional video codecs such as VVC. Possible explanations can be put forward: lack of data to account for the temporal redundancy, or inefficiency of latent's density estimation in the neural model. The latter problem can be defined by the discrepancy between the latent's marginal distribution and the learned prior distribution. This mismatch, known as amortization gap of entropy model, enlarges the file size of compressed data. In this paper, we propose to evaluate the amortization gap for three state-of-the-art ML video compression methods. Second, we propose an efficient and generic method to solve the amortization gap and show that it leads to an improvement between $2\%$ to $5\%$ without impacting reconstruction quality.
Video Coding Using Learned Latent GAN Compression
Jul 12, 2022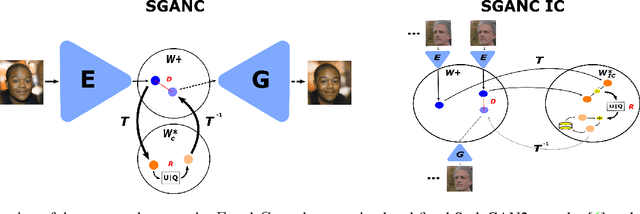

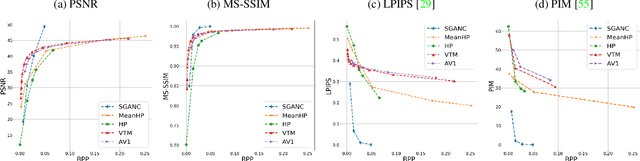

We propose in this paper a new paradigm for facial video compression. We leverage the generative capacity of GANs such as StyleGAN to represent and compress a video, including intra and inter compression. Each frame is inverted in the latent space of StyleGAN, from which the optimal compression is learned. To do so, a diffeomorphic latent representation is learned using a normalizing flows model, where an entropy model can be optimized for image coding. In addition, we propose a new perceptual loss that is more efficient than other counterparts. Finally, an entropy model for video inter coding with residual is also learned in the previously constructed latent representation. Our method (SGANC) is simple, faster to train, and achieves better results for image and video coding compared to state-of-the-art codecs such as VTM, AV1, and recent deep learning techniques. In particular, it drastically minimizes perceptual distortion at low bit rates.
$\textit{FacialFilmroll}$: High-resolution multi-shot video editing
Oct 05, 2021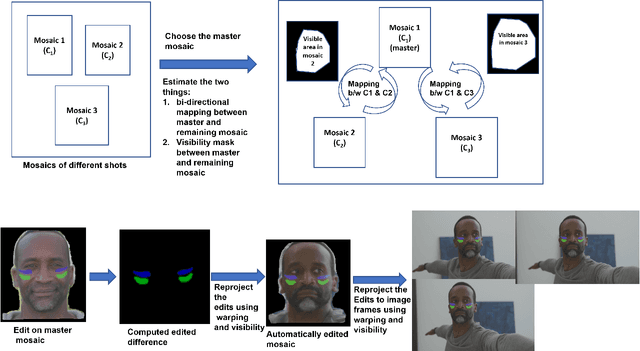
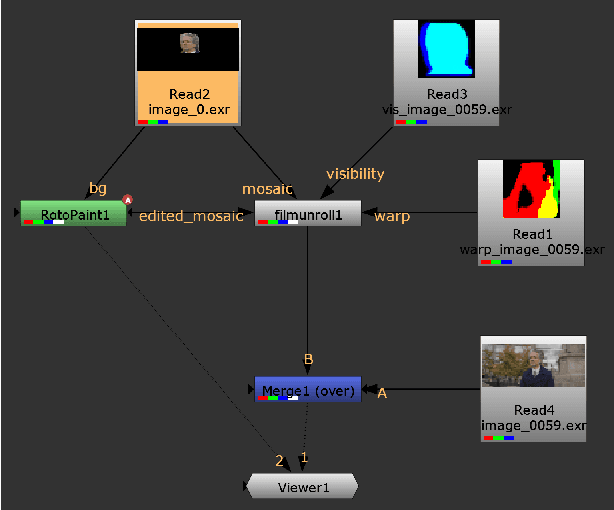


We present $\textit{FacialFilmroll}$, a solution for spatially and temporally consistent editing of faces in one or multiple shots. We build upon unwrap mosaic [Rav-Acha et al. 2008] by specializing it to faces. We leverage recent techniques to fit a 3D face model on monocular videos to (i) improve the quality of the mosaic for edition and (ii) permit the automatic transfer of edits from one shot to other shots of the same actor. We explain how $\textit{FacialFilmroll}$ is integrated in post-production facility. Finally, we present video editing results using $\textit{FacialFilmroll}$ on high resolution videos.
* European Conference on Visual Media Production (CVMP '21)
Semantic and Geometric Unfolding of StyleGAN Latent Space
Jul 09, 2021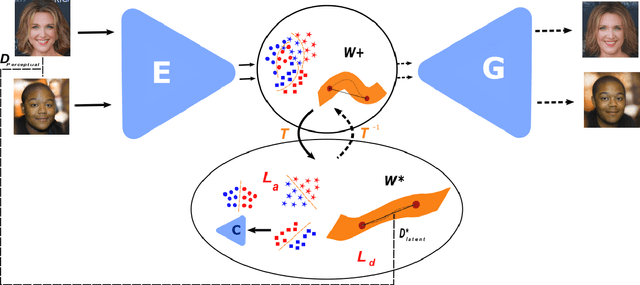
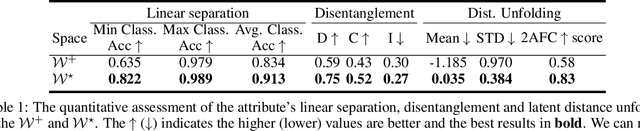

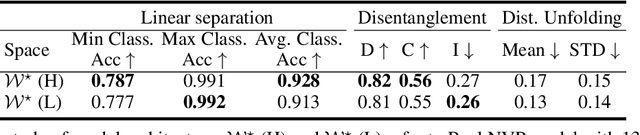
Generative adversarial networks (GANs) have proven to be surprisingly efficient for image editing by inverting and manipulating the latent code corresponding to a natural image. This property emerges from the disentangled nature of the latent space. In this paper, we identify two geometric limitations of such latent space: (a) euclidean distances differ from image perceptual distance, and (b) disentanglement is not optimal and facial attribute separation using linear model is a limiting hypothesis. We thus propose a new method to learn a proxy latent representation using normalizing flows to remedy these limitations, and show that this leads to a more efficient space for face image editing.
Pushing the right boundaries matters! Wasserstein Adversarial Training for Label Noise
Apr 08, 2019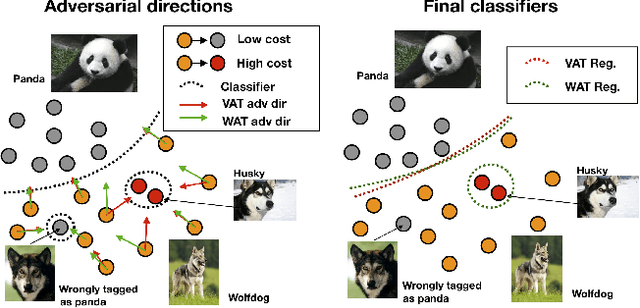
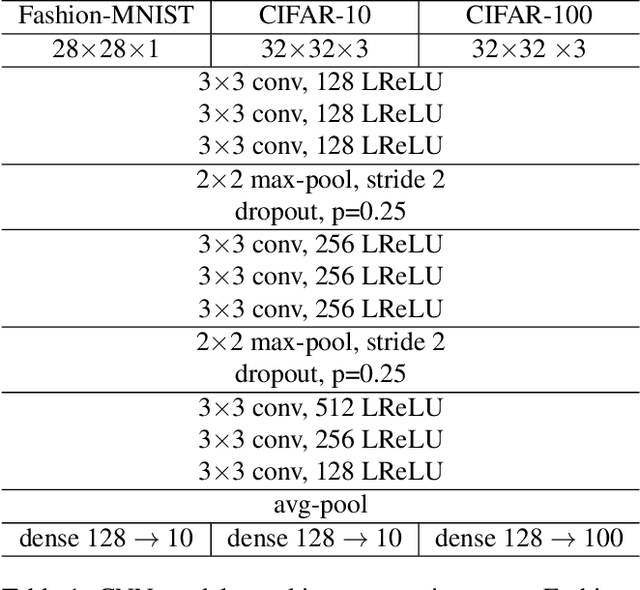
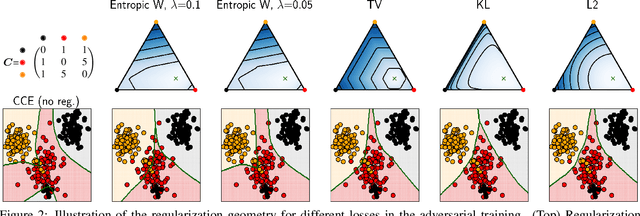
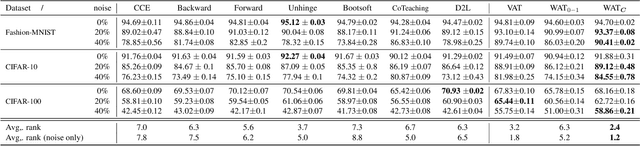
Noisy labels often occur in vision datasets, especially when they are issued from crowdsourcing or Web scraping. In this paper, we propose a new regularization method which enables one to learn robust classifiers in presence of noisy data. To achieve this goal, we augment the virtual adversarial loss with a Wasserstein distance. This distance allows us to take into account specific relations between classes by leveraging on the geometric properties of this optimal transport distance. Notably, we encode the class similarities in the ground cost that is used to compute the Wasserstein distance. As a consequence, we can promote smoothness between classes that are very dissimilar, while keeping the classification decision function sufficiently complex for similar classes. While designing this ground cost can be left as a problem-specific modeling task, we show in this paper that using the semantic relations between classes names already leads to good results.Our proposed Wasserstein Adversarial Training (WAT) outperforms state of the art on four datasets corrupted with noisy labels: three classical benchmarks and one real case in remote sensing image semantic segmentation.