 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Latent Properties to Optimize Neural Codecs
Jan 02, 2025



End-to-end image and video codecs are becoming increasingly competitive, compared to traditional compression techniques that have been developed through decades of manual engineering efforts. These trainable codecs have many advantages over traditional techniques, such as their straightforward adaptation to perceptual distortion metrics and high performance in specific fields thanks to their learning ability. However, current state-of-the-art neural codecs do not fully exploit the benefits of vector quantization and the existence of the entropy gradient in decoding devices. In this paper, we propose to leverage these two properties (vector quantization and entropy gradient) to improve the performance of off-the-shelf codecs. Firstly, we demonstrate that using non-uniform scalar quantization cannot improve performance over uniform quantization. We thus suggest using predefined optimal uniform vector quantization to improve performance. Secondly, we show that the entropy gradient, available at the decoder, is correlated with the reconstruction error gradient, which is not available at the decoder. We therefore use the former as a proxy to enhance compression performance. Our experimental results show that these approaches save between 1 to 3% of the rate for the same quality across various pretrained methods. In addition, the entropy gradient based solution improves traditional codec performance significantly as well.
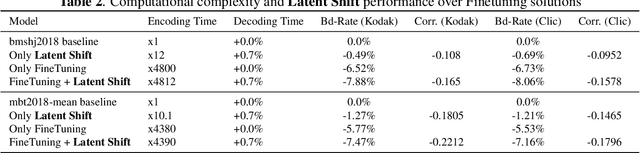
Latent-Shift: Gradient of Entropy Helps Neural Codecs
Aug 01, 2023
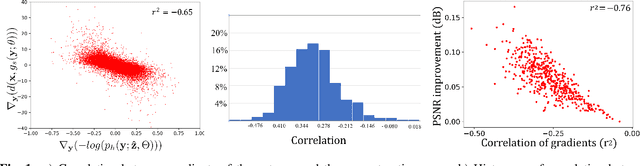
End-to-end image/video codecs are getting competitive compared to traditional compression techniques that have been developed through decades of manual engineering efforts. These trainable codecs have many advantages over traditional techniques such as easy adaptation on perceptual distortion metrics and high performance on specific domains thanks to their learning ability. However, state of the art neural codecs does not take advantage of the existence of gradient of entropy in decoding device. In this paper, we theoretically show that gradient of entropy (available at decoder side) is correlated with the gradient of the reconstruction error (which is not available at decoder side). We then demonstrate experimentally that this gradient can be used on various compression methods, leading to a $1-2\%$ rate savings for the same quality. Our method is orthogonal to other improvements and brings independent rate savings.
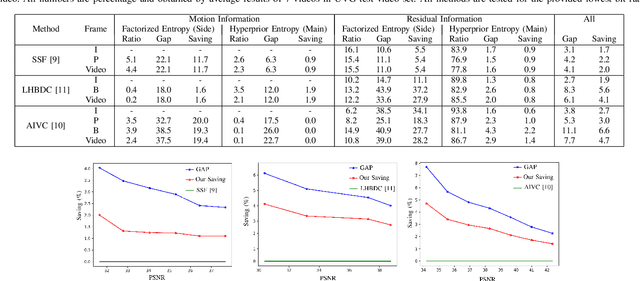
Entropy Coding Improvement for Low-complexity Compressive Auto-encoders
Mar 10, 2023End-to-end image and video compression using auto-encoders (AE) offers new appealing perspectives in terms of rate-distortion gains and applications. While most complex models are on par with the latest compression standard like VVC/H.266 on objective metrics, practical implementation and complexity remain strong issues for real-world applications. In this paper, we propose a practical implementation suitable for realistic applications, leading to a low-complexity model. We demonstrate that some gains can be achieved on top of a state-of-the-art low-complexity AE, even when using simpler implementation. Improvements include off-training entropy coding improvement and encoder side Rate Distortion Optimized Quantization. Results show a 19% improvement in BDrate on basic implementation of fully-factorized model, and 15.3% improvement compared to the original implementation. The proposed implementation also allows a direct integration of such approaches on a variety of platforms.
RQAT-INR: Improved Implicit Neural Image Compression
Mar 06, 2023
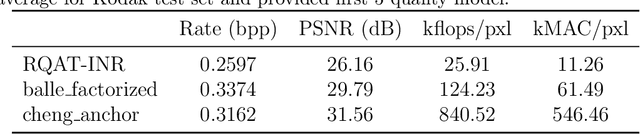
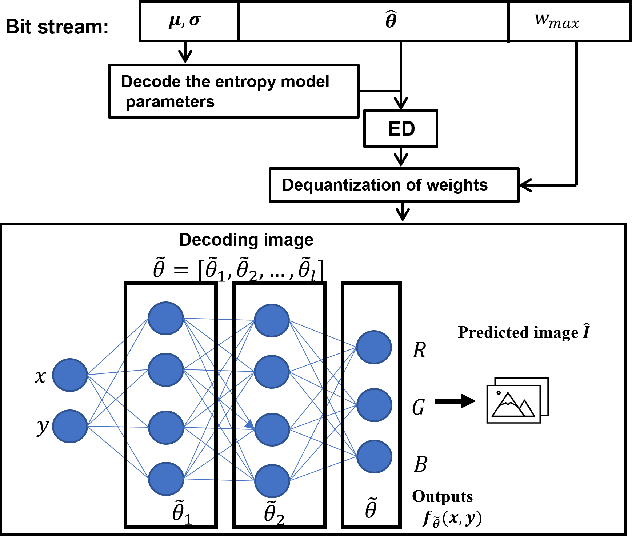
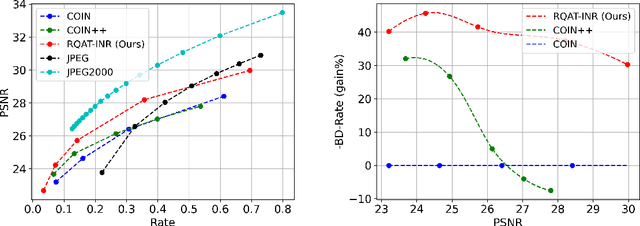
Deep variational autoencoders for image and video compression have gained significant attraction in the recent years, due to their potential to offer competitive or better compression rates compared to the decades long traditional codecs such as AVC, HEVC or VVC. However, because of complexity and energy consumption, these approaches are still far away from practical usage in industry. More recently, implicit neural representation (INR) based codecs have emerged, and have lower complexity and energy usage to classical approaches at decoding. However, their performances are not in par at the moment with state-of-the-art methods. In this research, we first show that INR based image codec has a lower complexity than VAE based approaches, then we propose several improvements for INR-based image codec and outperformed baseline model by a large margin.
Reducing The Mismatch Between Marginal and Learned Distributions in Neural Video Compression
Oct 12, 2022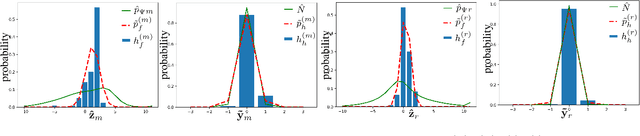
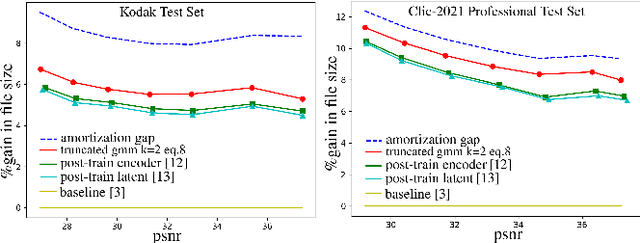
During the last four years, we have witnessed the success of end-to-end trainable models for image compression. Compared to decades of incremental work, these machine learning (ML) techniques learn all the components of the compression technique, which explains their actual superiority. However, end-to-end ML models have not yet reached the performance of traditional video codecs such as VVC. Possible explanations can be put forward: lack of data to account for the temporal redundancy, or inefficiency of latent's density estimation in the neural model. The latter problem can be defined by the discrepancy between the latent's marginal distribution and the learned prior distribution. This mismatch, known as amortization gap of entropy model, enlarges the file size of compressed data. In this paper, we propose to evaluate the amortization gap for three state-of-the-art ML video compression methods. Second, we propose an efficient and generic method to solve the amortization gap and show that it leads to an improvement between $2\%$ to $5\%$ without impacting reconstruction quality.
Improving The Reconstruction Quality by Overfitted Decoder Bias in Neural Image Compression
Oct 10, 2022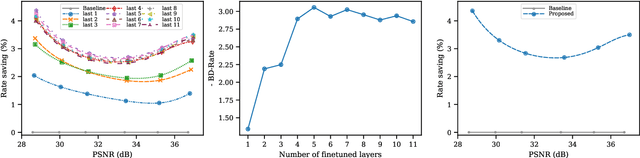


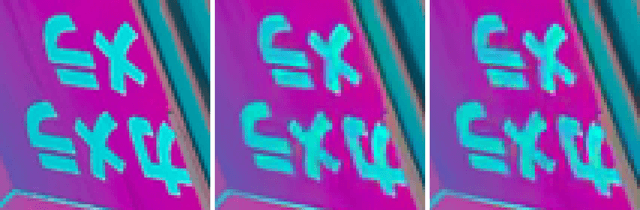
End-to-end trainable models have reached the performance of traditional handcrafted compression techniques on videos and images. Since the parameters of these models are learned over large training sets, they are not optimal for any given image to be compressed. In this paper, we propose an instance-based fine-tuning of a subset of decoder's bias to improve the reconstruction quality in exchange for extra encoding time and minor additional signaling cost. The proposed method is applicable to any end-to-end compression methods, improving the state-of-the-art neural image compression BD-rate by $3-5\%$.
Reducing The Amortization Gap of Entropy Bottleneck In End-to-End Image Compression
Sep 02, 2022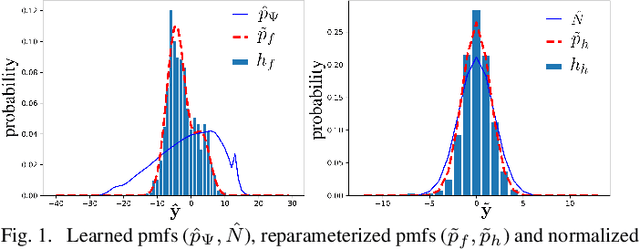
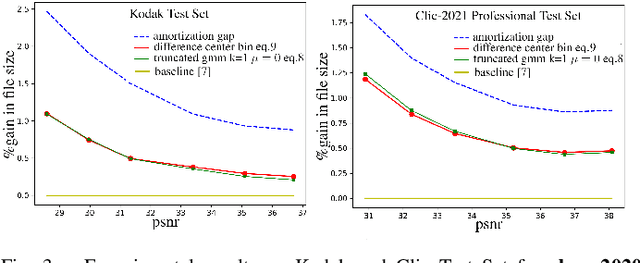
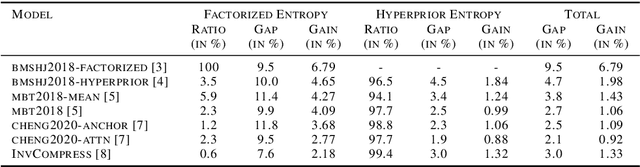
End-to-end deep trainable models are about to exceed the performance of the traditional handcrafted compression techniques on videos and images. The core idea is to learn a non-linear transformation, modeled as a deep neural network, mapping input image into latent space, jointly with an entropy model of the latent distribution. The decoder is also learned as a deep trainable network, and the reconstructed image measures the distortion. These methods enforce the latent to follow some prior distributions. Since these priors are learned by optimization over the entire training set, the performance is optimal in average. However, it cannot fit exactly on every single new instance, hence damaging the compression performance by enlarging the bit-stream. In this paper, we propose a simple yet efficient instance-based parameterization method to reduce this amortization gap at a minor cost. The proposed method is applicable to any end-to-end compressing methods, improving the compression bitrate by 1% without any impact on the reconstruction quality.
Breaking the Limits of Message Passing Graph Neural Networks
Jun 08, 2021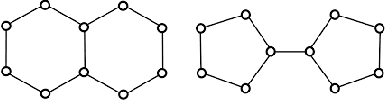
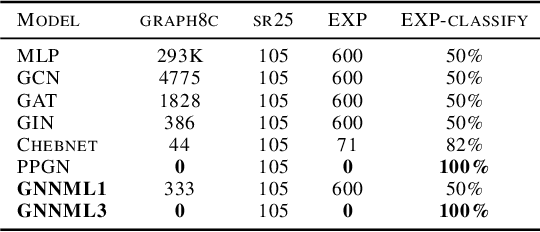
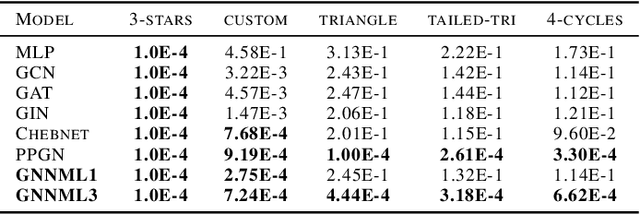
Since the Message Passing (Graph) Neural Networks (MPNNs) have a linear complexity with respect to the number of nodes when applied to sparse graphs, they have been widely implemented and still raise a lot of interest even though their theoretical expressive power is limited to the first order Weisfeiler-Lehman test (1-WL). In this paper, we show that if the graph convolution supports are designed in spectral-domain by a non-linear custom function of eigenvalues and masked with an arbitrary large receptive field, the MPNN is theoretically more powerful than the 1-WL test and experimentally as powerful as a 3-WL existing models, while remaining spatially localized. Moreover, by designing custom filter functions, outputs can have various frequency components that allow the convolution process to learn different relationships between a given input graph signal and its associated properties. So far, the best 3-WL equivalent graph neural networks have a computational complexity in $\mathcal{O}(n^3)$ with memory usage in $\mathcal{O}(n^2)$, consider non-local update mechanism and do not provide the spectral richness of output profile. The proposed method overcomes all these aforementioned problems and reaches state-of-the-art results in many downstream tasks.
Bridging the Gap Between Spectral and Spatial Domains in Graph Neural Networks
Mar 26, 2020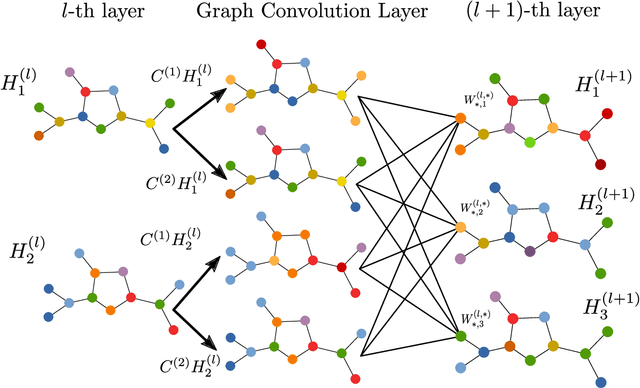
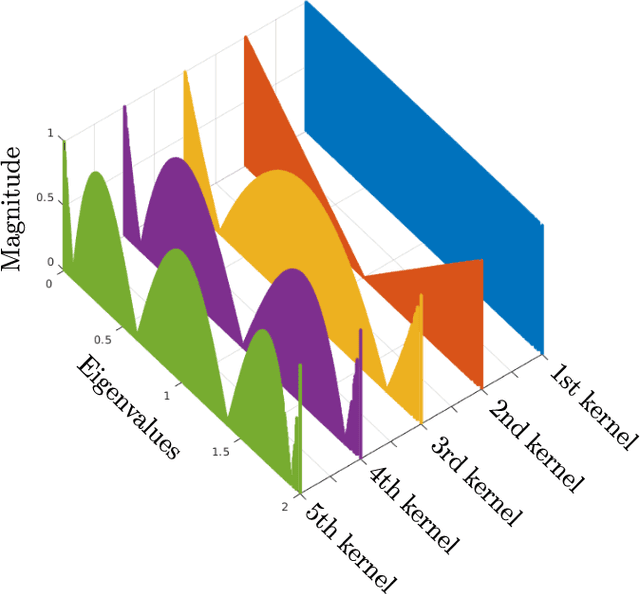
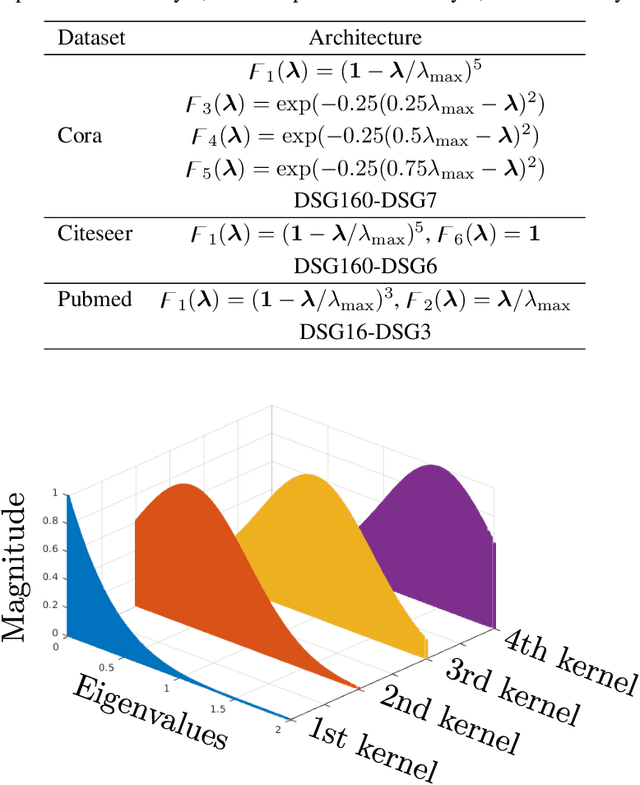
This paper aims at revisiting Graph Convolutional Neural Networks by bridging the gap between spectral and spatial design of graph convolutions. We theoretically demonstrate some equivalence of the graph convolution process regardless it is designed in the spatial or the spectral domain. The obtained general framework allows to lead a spectral analysis of the most popular ConvGNNs, explaining their performance and showing their limits. Moreover, the proposed framework is used to design new convolutions in spectral domain with a custom frequency profile while applying them in the spatial domain. We also propose a generalization of the depthwise separable convolution framework for graph convolutional networks, what allows to decrease the total number of trainable parameters by keeping the capacity of the model. To the best of our knowledge, such a framework has never been used in the GNNs literature. Our proposals are evaluated on both transductive and inductive graph learning problems. Obtained results show the relevance of the proposed method and provide one of the first experimental evidence of transferability of spectral filter coefficients from one graph to another. Our source codes are publicly available at: https://github.com/balcilar/Spectral-Designed-Graph-Convolutions
Audio Captcha Recognition Using RastaPLP Features by SVM
Jan 08, 2019
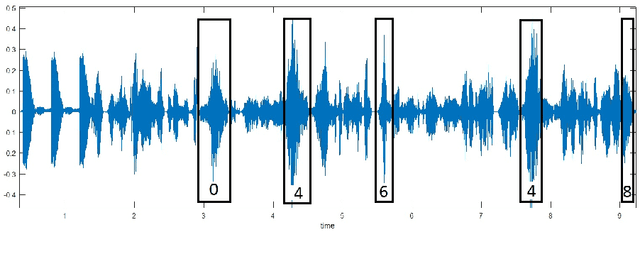
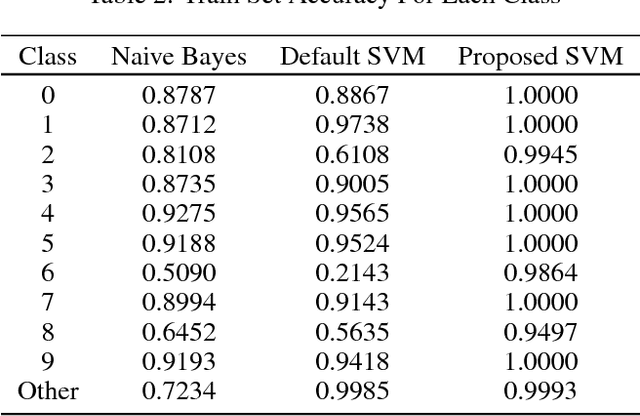
Nowadays, CAPTCHAs are computer generated tests that human can pass but current computer systems can not. They have common usage in various web services in order to be able to detect a human from computer programs autonomously. In this way, owners can protect their web services from bots. In addition to visual CAPTCHAs which consist of distorted images, mostly test images, that a user must write some description about that image, there are a significant amount of audio CAPTCHAs as well. Briefly, audio CAPTCHAs are sound files which consist of human sound under heavy noise where the speaker pronounces a bunch of digits consecutively. Generally, in those sound files, there are some periodic and non-periodic noises to get difficult to recognize them with a program but not for a human listener. We gathered numerous randomly collected audio file to train and then test them using our SVM algorithm to be able to extract digits out of each conversation.