 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContext Adaptive Extended Chain Coding for Semantic Map Compression
Mar 03, 2026Semantic maps are increasingly utilized in areas such as robotics, autonomous systems, and extended reality, motivating the investigation of efficient compression methods that preserve structured semantic information. This paper studies lossless compression of semantic maps through a novel chain-coding-based framework that explicitly exploits contour topology and shared boundaries between adjacent semantic regions. We propose an extended chain code (ECC) to represent long-range contour transitions more compactly, while retaining a legacy three-orthogonal chain code (3OT) as a fallback mode for further efficiency. To efficiently encode sequences of ECC symbols, a context-adaptive entropy coding scheme based on Markov modeling is employed. Furthermore, a skip-coding mechanism is introduced to eliminate redundant representations of shared contours between adjacent semantic regions, supporting both complete and partial skips via run-length signaling. Experimental results demonstrate that the proposed method achieves an average bitrate reduction of 18\% compared with a state-of-the-art benchmark on semantic map datasets. In addition, the proposed encoder and decoder achieve up to 98\% and 50\% runtime reduction, respectively, relative to a modern generic lossless codec. Extended evaluations on occupancy maps further confirm consistent compression gains across the majority of tested scenarios.
Wrapper-Aware Rate-Distortion Optimization in Feature Coding for Machines
Jan 29, 2026Feature coding for machines (FCM) is a lossy compression paradigm for split-inference. The transmitter encodes the outputs of the first part of a neural network before sending them to the receiver for completing the inference. Practical FCM methods ``sandwich'' a traditional codec between pre- and post-processing neural networks, called wrappers, to make features easier to compress using video codecs. Since traditional codecs are non-differentiable, the wrappers are trained using a proxy codec, which is later replaced by a standard codec after training. These codecs perform rate-distortion optimization (RDO) based on the sum of squared errors (SSE). Because the RDO does not consider the post-processing wrapper, the inner codec can invest bits in preserving information that the post-processing later discards. In this paper, we modify the bit-allocation in the inner codec via a wrapper-aware weighted SSE metric. To make wrapper-aware RDO (WA-RDO) practical for FCM, we propose: 1) temporal reuse of weights across a group of pictures and 2) fixed, architecture- and task-dependent weights trained offline. Under MPEG test conditions, our methods implemented on HEVC match the VVC-based FCM state-of-the-art, effectively bridging a codec generation gap with minimal runtime overhead relative to SSE-RDO HEVC.
Feature Compression for Machines with Range-Based Channel Truncation and Frame Packing
Dec 11, 2025This paper proposes a method that enhances the compression performance of the current model under development for the upcoming MPEG standard on Feature Coding for Machines (FCM). This standard aims at providing inter-operable compressed bitstreams of features in the context of split computing, i.e., when the inference of a large computer vision neural-network (NN)-based model is split between two devices. Intermediate features can consist of multiple 3D tensors that can be reduced and entropy coded to limit the required bandwidth of such transmission. In the envisioned design for the MPEG-FCM standard, intermediate feature tensors may be reduced using Neural layers before being converted into 2D video frames that can be coded using existing video compression standards. This paper introduces an additional channel truncation and packing method which enables the system to preserve the relevant channels, depending on the statistics of the features at inference time, while preserving the computer vision task performance at the receiver. Implemented within the MPEG-FCM test model, the proposed method yields an average reduction in rate by 10.59% for a given accuracy on multiple computer vision tasks and datasets.
* 10 pages, 8 figures. Extended version of the paper with the same title presented at IEEE DCC 2025
Efficient Feature Compression for Machines with Global Statistics Preservation
Dec 10, 2025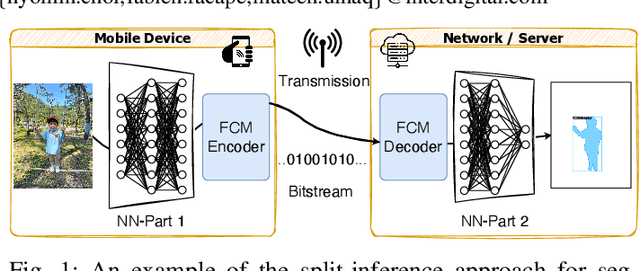
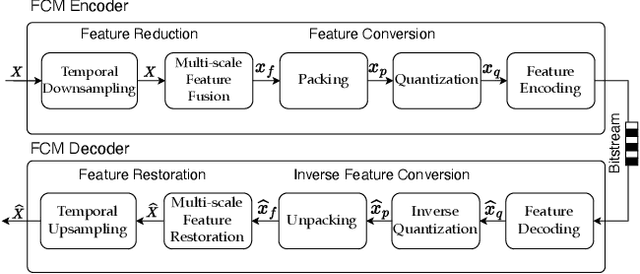
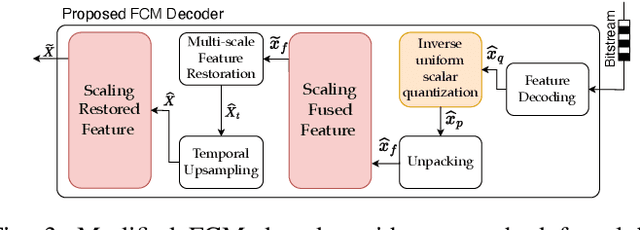
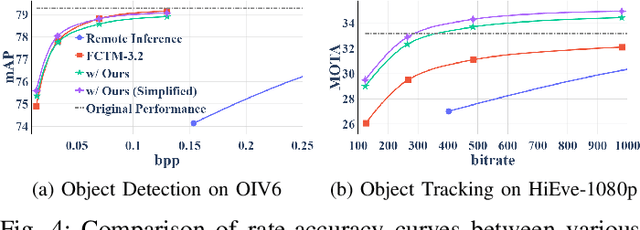
The split-inference paradigm divides an artificial intelligence (AI) model into two parts. This necessitates the transfer of intermediate feature data between the two halves. Here, effective compression of the feature data becomes vital. In this paper, we employ Z-score normalization to efficiently recover the compressed feature data at the decoder side. To examine the efficacy of our method, the proposed method is integrated into the latest Feature Coding for Machines (FCM) codec standard under development by the Moving Picture Experts Group (MPEG). Our method supersedes the existing scaling method used by the current standard under development. It both reduces the overhead bits and improves the end-task accuracy. To further reduce the overhead in certain circumstances, we also propose a simplified method. Experiments show that using our proposed method shows 17.09% reduction in bitrate on average across different tasks and up to 65.69% for object tracking without sacrificing the task accuracy.
Entropy Coding Improvement for Low-complexity Compressive Auto-encoders
Mar 10, 2023End-to-end image and video compression using auto-encoders (AE) offers new appealing perspectives in terms of rate-distortion gains and applications. While most complex models are on par with the latest compression standard like VVC/H.266 on objective metrics, practical implementation and complexity remain strong issues for real-world applications. In this paper, we propose a practical implementation suitable for realistic applications, leading to a low-complexity model. We demonstrate that some gains can be achieved on top of a state-of-the-art low-complexity AE, even when using simpler implementation. Improvements include off-training entropy coding improvement and encoder side Rate Distortion Optimized Quantization. Results show a 19% improvement in BDrate on basic implementation of fully-factorized model, and 15.3% improvement compared to the original implementation. The proposed implementation also allows a direct integration of such approaches on a variety of platforms.
End-to-end optimized image compression for multiple machine tasks
Mar 06, 2021
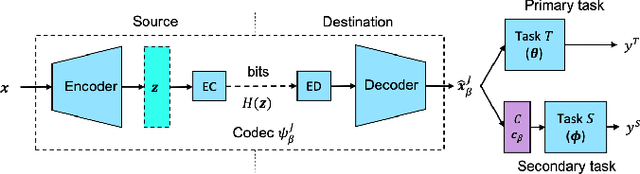
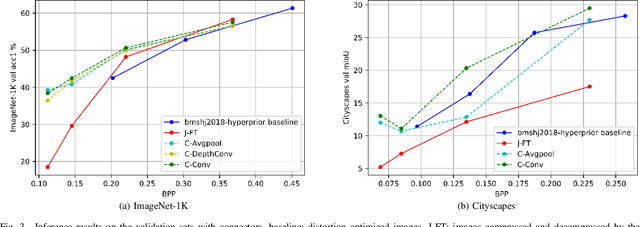

An increasing share of captured images and videos are transmitted for storage and remote analysis by computer vision algorithms, rather than to be viewed by humans. Contrary to traditional standard codecs with engineered tools, neural network based codecs can be trained end-to-end to optimally compress images with respect to a target rate and any given differentiable performance metric. Although it is possible to train such compression tools to achieve better rate-accuracy performance for a particular computer vision task, it could be practical and relevant to re-use the compressed bit-stream for multiple machine tasks. For this purpose, we introduce 'Connectors' that are inserted between the decoder and the task algorithms to enable a direct transformation of the compressed content, which was previously optimized for a specific task, to multiple other machine tasks. We demonstrate the effectiveness of the proposed method by achieving significant rate-accuracy performance improvement for both image classification and object segmentation, using the same bit-stream, originally optimized for object detection.
End-to-end optimized image compression for machines, a study
Nov 10, 2020

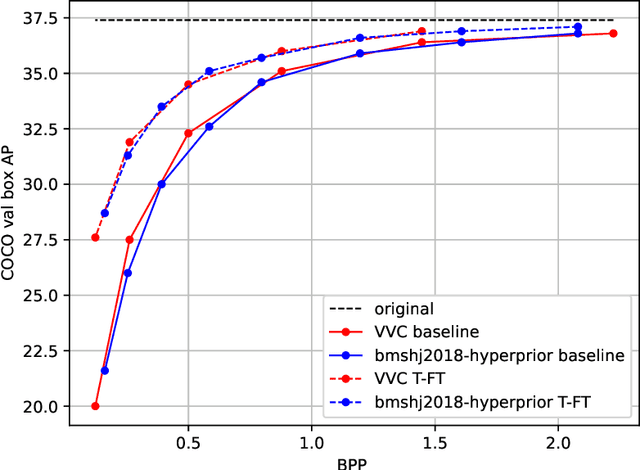
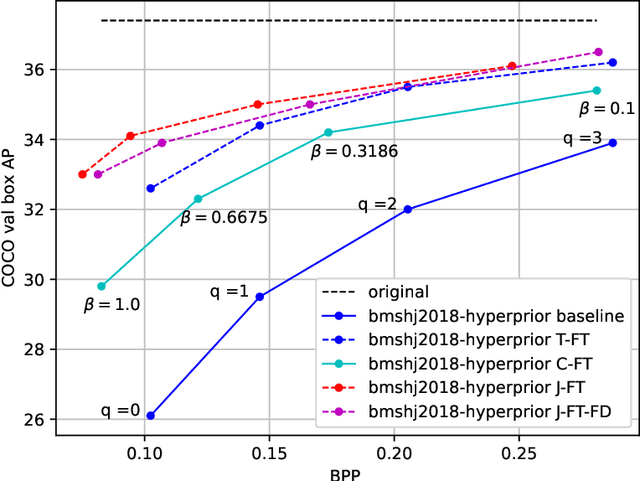
An increasing share of image and video content is analyzed by machines rather than viewed by humans, and therefore it becomes relevant to optimize codecs for such applications where the analysis is performed remotely. Unfortunately, conventional coding tools are challenging to specialize for machine tasks as they were originally designed for human perception. However, neural network based codecs can be jointly trained end-to-end with any convolutional neural network (CNN)-based task model. In this paper, we propose to study an end-to-end framework enabling efficient image compression for remote machine task analysis, using a chain composed of a compression module and a task algorithm that can be optimized end-to-end. We show that it is possible to significantly improve the task accuracy when fine-tuning jointly the codec and the task networks, especially at low bit-rates. Depending on training or deployment constraints, selective fine-tuning can be applied only on the encoder, decoder or task network and still achieve rate-accuracy improvements over an off-the-shelf codec and task network. Our results also demonstrate the flexibility of end-to-end pipelines for practical applications.
CompressAI: a PyTorch library and evaluation platform for end-to-end compression research
Nov 05, 2020
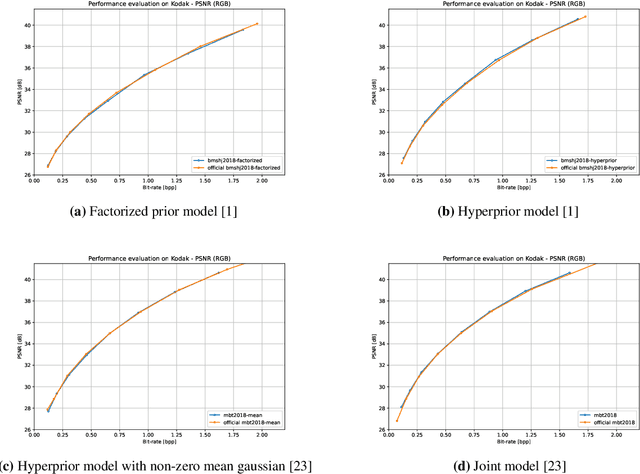

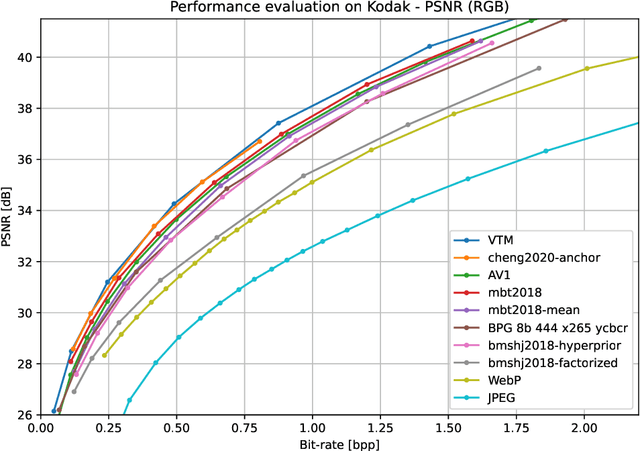
This paper presents CompressAI, a platform that provides custom operations, layers, models and tools to research, develop and evaluate end-to-end image and video compression codecs. In particular, CompressAI includes pre-trained models and evaluation tools to compare learned methods with traditional codecs. Multiple models from the state-of-the-art on learned end-to-end compression have thus been reimplemented in PyTorch and trained from scratch. We also report objective comparison results using PSNR and MS-SSIM metrics vs. bit-rate, using the Kodak image dataset as test set. Although this framework currently implements models for still-picture compression, it is intended to be soon extended to the video compression domain.