 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting Latent Properties to Optimize Neural Codecs
Jan 02, 2025



End-to-end image and video codecs are becoming increasingly competitive, compared to traditional compression techniques that have been developed through decades of manual engineering efforts. These trainable codecs have many advantages over traditional techniques, such as their straightforward adaptation to perceptual distortion metrics and high performance in specific fields thanks to their learning ability. However, current state-of-the-art neural codecs do not fully exploit the benefits of vector quantization and the existence of the entropy gradient in decoding devices. In this paper, we propose to leverage these two properties (vector quantization and entropy gradient) to improve the performance of off-the-shelf codecs. Firstly, we demonstrate that using non-uniform scalar quantization cannot improve performance over uniform quantization. We thus suggest using predefined optimal uniform vector quantization to improve performance. Secondly, we show that the entropy gradient, available at the decoder, is correlated with the reconstruction error gradient, which is not available at the decoder. We therefore use the former as a proxy to enhance compression performance. Our experimental results show that these approaches save between 1 to 3% of the rate for the same quality across various pretrained methods. In addition, the entropy gradient based solution improves traditional codec performance significantly as well.
Designs and Implementations in Neural Network-based Video Coding
Sep 13, 2023
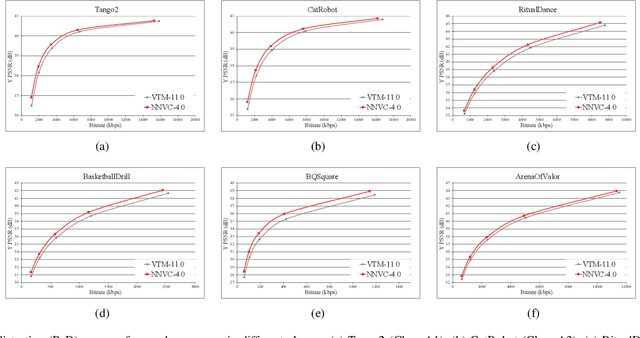
The past decade has witnessed the huge success of deep learning in well-known artificial intelligence applications such as face recognition, autonomous driving, and large language model like ChatGPT. Recently, the application of deep learning has been extended to a much wider range, with neural network-based video coding being one of them. Neural network-based video coding can be performed at two different levels: embedding neural network-based (NN-based) coding tools into a classical video compression framework or building the entire compression framework upon neural networks. This paper elaborates some of the recent exploration efforts of JVET (Joint Video Experts Team of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC29) in the name of neural network-based video coding (NNVC), falling in the former category. Specifically, this paper discusses two major NN-based video coding technologies, i.e. neural network-based intra prediction and neural network-based in-loop filtering, which have been investigated for several meeting cycles in JVET and finally adopted into the reference software of NNVC. Extensive experiments on top of the NNVC have been conducted to evaluate the effectiveness of the proposed techniques. Compared with VTM-11.0_nnvc, the proposed NN-based coding tools in NNVC-4.0 could achieve {11.94%, 21.86%, 22.59%}, {9.18%, 19.76%, 20.92%}, and {10.63%, 21.56%, 23.02%} BD-rate reductions on average for {Y, Cb, Cr} under random-access, low-delay, and all-intra configurations respectively.
Latent-Shift: Gradient of Entropy Helps Neural Codecs
Aug 01, 2023
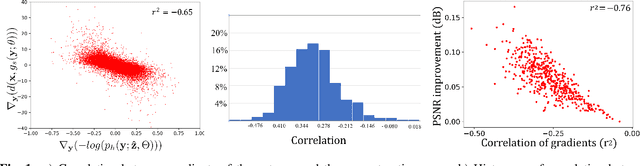
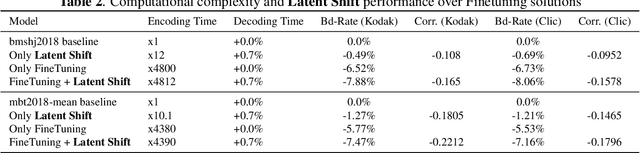
End-to-end image/video codecs are getting competitive compared to traditional compression techniques that have been developed through decades of manual engineering efforts. These trainable codecs have many advantages over traditional techniques such as easy adaptation on perceptual distortion metrics and high performance on specific domains thanks to their learning ability. However, state of the art neural codecs does not take advantage of the existence of gradient of entropy in decoding device. In this paper, we theoretically show that gradient of entropy (available at decoder side) is correlated with the gradient of the reconstruction error (which is not available at decoder side). We then demonstrate experimentally that this gradient can be used on various compression methods, leading to a $1-2\%$ rate savings for the same quality. Our method is orthogonal to other improvements and brings independent rate savings.
Entropy Coding Improvement for Low-complexity Compressive Auto-encoders
Mar 10, 2023End-to-end image and video compression using auto-encoders (AE) offers new appealing perspectives in terms of rate-distortion gains and applications. While most complex models are on par with the latest compression standard like VVC/H.266 on objective metrics, practical implementation and complexity remain strong issues for real-world applications. In this paper, we propose a practical implementation suitable for realistic applications, leading to a low-complexity model. We demonstrate that some gains can be achieved on top of a state-of-the-art low-complexity AE, even when using simpler implementation. Improvements include off-training entropy coding improvement and encoder side Rate Distortion Optimized Quantization. Results show a 19% improvement in BDrate on basic implementation of fully-factorized model, and 15.3% improvement compared to the original implementation. The proposed implementation also allows a direct integration of such approaches on a variety of platforms.
RQAT-INR: Improved Implicit Neural Image Compression
Mar 06, 2023
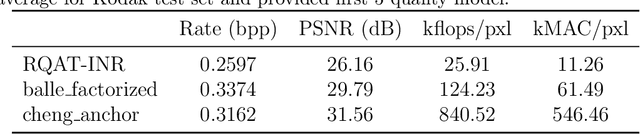
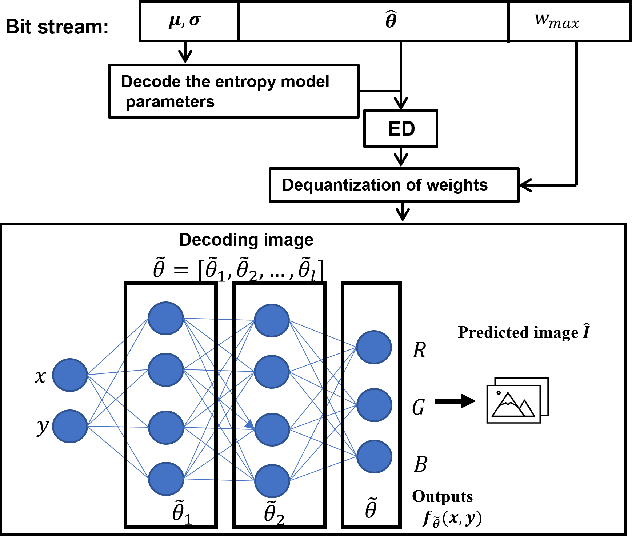
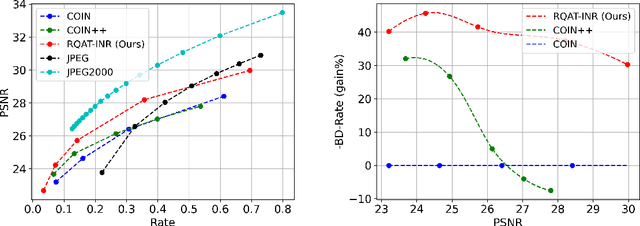
Deep variational autoencoders for image and video compression have gained significant attraction in the recent years, due to their potential to offer competitive or better compression rates compared to the decades long traditional codecs such as AVC, HEVC or VVC. However, because of complexity and energy consumption, these approaches are still far away from practical usage in industry. More recently, implicit neural representation (INR) based codecs have emerged, and have lower complexity and energy usage to classical approaches at decoding. However, their performances are not in par at the moment with state-of-the-art methods. In this research, we first show that INR based image codec has a lower complexity than VAE based approaches, then we propose several improvements for INR-based image codec and outperformed baseline model by a large margin.
Revisiting the Sample Adaptive Offset post-filter of VVC with Neural-Networks
Jul 11, 2022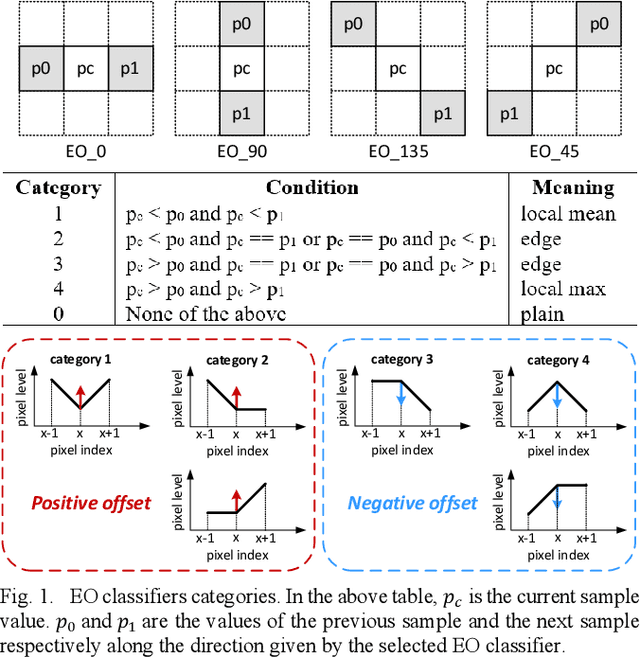
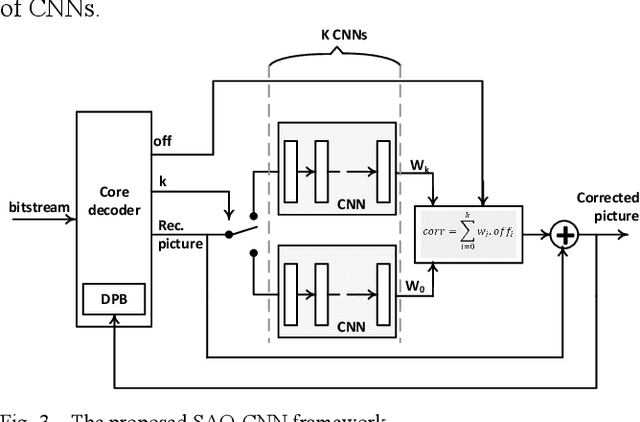
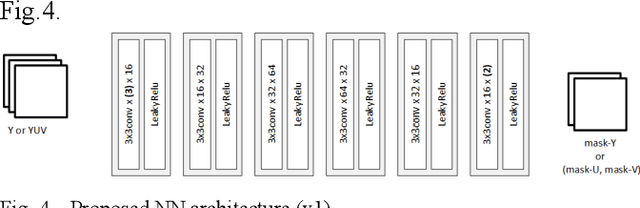
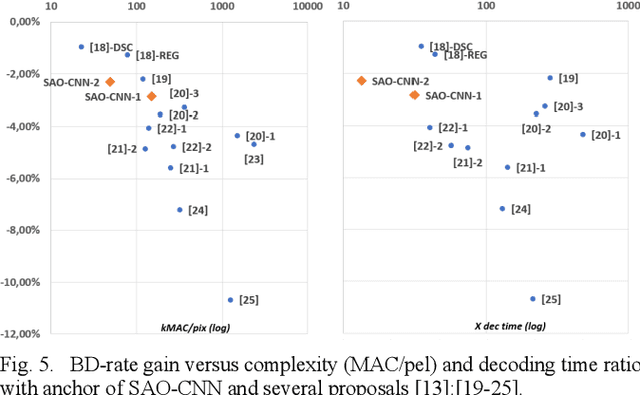
The Sample Adaptive Offset (SAO) filter has been introduced in HEVC to reduce general coding and banding artefacts in the reconstructed pictures, in complement to the De-Blocking Filter (DBF) which reduces artifacts at block boundaries specifically. The new video compression standard Versatile Video Coding (VVC) reduces the BD-rate by about 36% at the same reconstruction quality compared to HEVC. It implements an additional new in-loop Adaptive Loop Filter (ALF) on top of the DBF and the SAO filter, the latter remaining unchanged compared to HEVC. However, the relative performance of SAO in VVC has been lowered significantly. In this paper, it is proposed to revisit the SAO filter using Neural Networks (NN). The general principles of the SAO are kept, but the a-priori classification of SAO is replaced with a set of neural networks that determine which reconstructed samples should be corrected and in which proportion. Similarly to the original SAO, some parameters are determined at the encoder side and encoded per CTU. The average BD-rate gain of the proposed SAO improves VVC by at least 2.3% in Random Access while the overall complexity is kept relatively small compared to other NN-based methods.
Neural Network based Inter bi-prediction Blending
Jan 26, 2022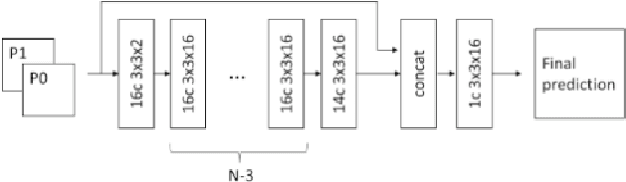



This paper presents a learning-based method to improve bi-prediction in video coding. In conventional video coding solutions, the motion compensation of blocks from already decoded reference pictures stands out as the principal tool used to predict the current frame. Especially, the bi-prediction, in which a block is obtained by averaging two different motion-compensated prediction blocks, significantly improves the final temporal prediction accuracy. In this context, we introduce a simple neural network that further improves the blending operation. A complexity balance, both in terms of network size and encoder mode selection, is carried out. Extensive tests on top of the recently standardized VVC codec are performed and show a BD-rate improvement of -1.4% in random access configuration for a network size of fewer than 10k parameters. We also propose a simple CPU-based implementation and direct network quantization to assess the complexity/gains tradeoff in a conventional codec framework.
Combined neural network-based intra prediction and transform selection
Aug 18, 2021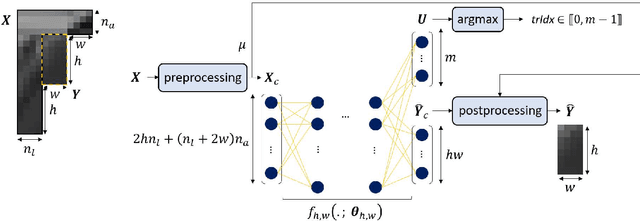
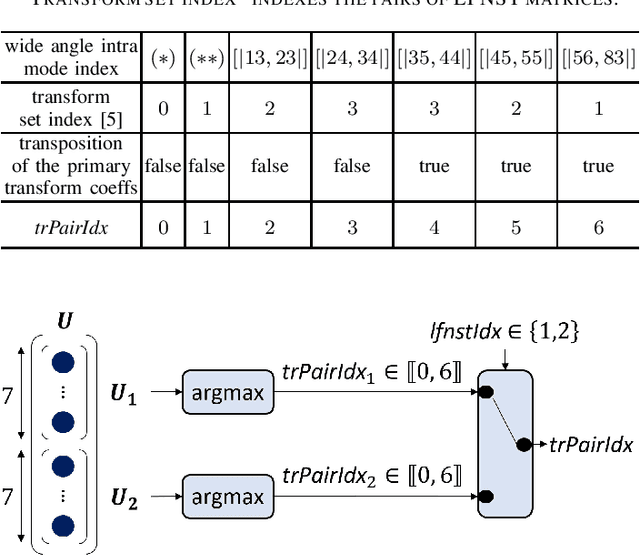
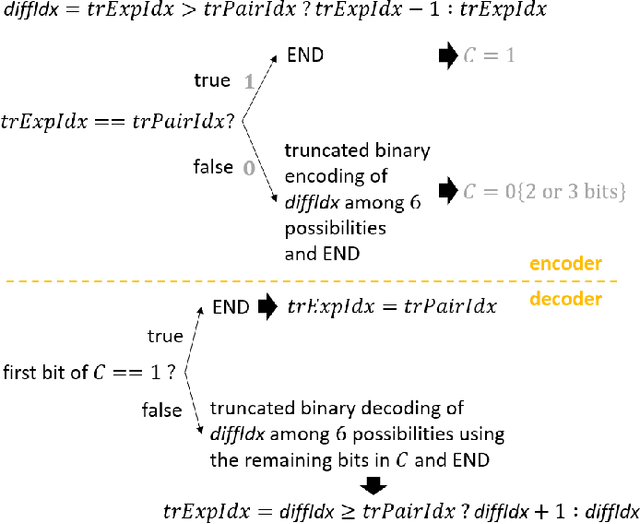
The interactions between different tools added successively to a block-based video codec are critical to its rate-distortion efficiency. In particular, when deep neural network-based intra prediction modes are inserted into a block-based video codec, as the neural network-based prediction function cannot be easily characterized, the adaptation of the transform selection process to the new modes can hardly be performed manually. That is why this paper presents a combined neural network-based intra prediction and transform selection for a block-based video codec. When putting a single neural network-based intra prediction mode and the learned prediction of the selected LFNST pair index into VTM-8.0, -3.71%, -3.17%, and -3.37% of mean BD-rate reduction in all-intra is obtained.
Machine Learning based Efficient QT-MTT Partitioning Scheme for VVC Intra Encoders
Mar 10, 2021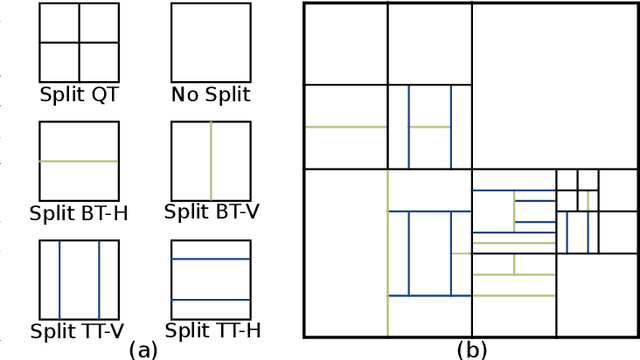
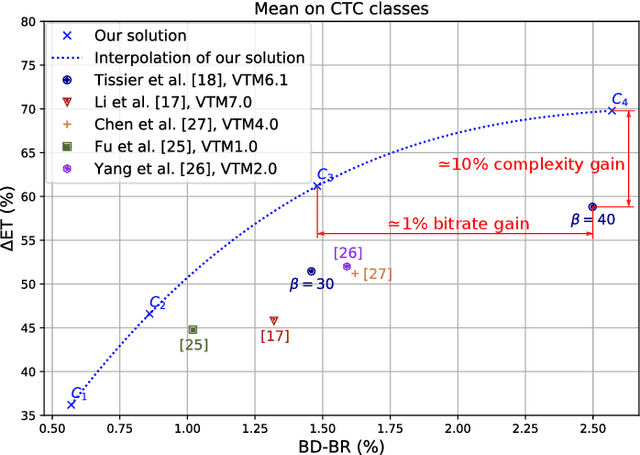
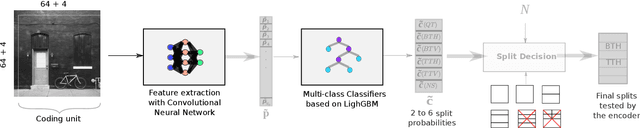
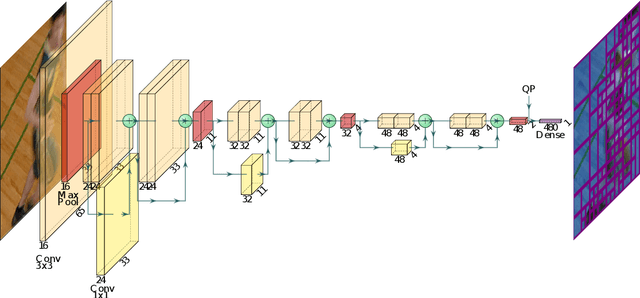
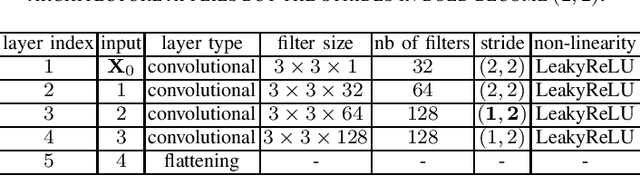
The next-generation Versatile Video Coding (VVC) standard introduces a new Multi-Type Tree (MTT) block partitioning structure that supports Binary-Tree (BT) and Ternary-Tree (TT) splits in both vertical and horizontal directions. This new approach leads to five possible splits at each block depth and thereby improves the coding efficiency of VVC over that of the preceding High Efficiency Video Coding (HEVC) standard, which only supports Quad-Tree (QT) partitioning with a single split per block depth. However, MTT also has brought a considerable impact on encoder computational complexity. In this paper, a two-stage learning-based technique is proposed to tackle the complexity overhead of MTT in VVC intra encoders. In our scheme, the input block is first processed by a Convolutional Neural Network (CNN) to predict its spatial features through a vector of probabilities describing the partition at each 4x4 edge. Subsequently, a Decision Tree (DT) model leverages this vector of spatial features to predict the most likely splits at each block. Finally, based on this prediction, only the N most likely splits are processed by the Rate-Distortion (RD) process of the encoder. In order to train our CNN and DT models on a wide range of image contents, we also propose a public VVC frame partitioning dataset based on existing image dataset encoded with the VVC reference software encoder. Our proposal relying on the top-3 configuration reaches 46.6% complexity reduction for a negligible bitrate increase of 0.86%. A top-2 configuration enables a higher complexity reduction of 69.8% for 2.57% bitrate loss. These results emphasis a better trade-off between VTM intra coding efficiency and complexity reduction compared to the state-of-the-art solutions.
Iterative training of neural networks for intra prediction
Mar 15, 2020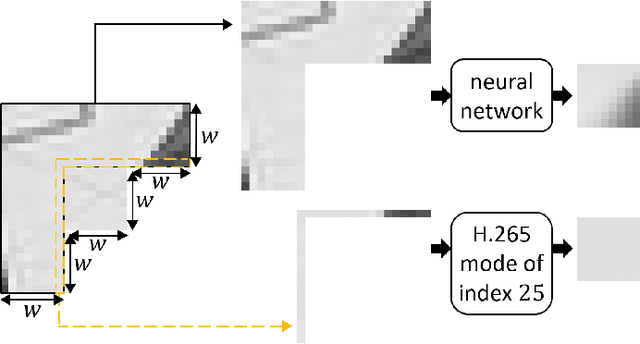



This paper presents an iterative training of neural networks for intra prediction in a block-based image and video codec. First, the neural networks are trained on blocks arising from the codec partitioning of images, each paired with its context. Then, iteratively, blocks are collected from the partitioning of images via the codec including the neural networks trained at the previous iteration, each paired with its context, and the neural networks are retrained on the new pairs. Thanks to this training, the neural networks can learn intra prediction functions that both stand out from those already in the initial codec and boost the codec in terms of rate-distortion. Moreover, the iterative process allows the design of training data cleansings essential for the neural network training. When the iteratively trained neural networks are put into H.265 (HM-16.15), -4.2% of mean dB-rate reduction is obtained, that is -1.8% above the state-of-the-art. By moving them into H.266 (VTM-5.0), the mean dB-rate reduction reaches -1.9%.