 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesigning Object Detection Models for TinyML: Foundations, Comparative Analysis, Challenges, and Emerging Solutions
Aug 11, 2025



Object detection (OD) has become vital for numerous computer vision applications, but deploying it on resource-constrained IoT devices presents a significant challenge. These devices, often powered by energy-efficient microcontrollers, struggle to handle the computational load of deep learning-based OD models. This issue is compounded by the rapid proliferation of IoT devices, predicted to surpass 150 billion by 2030. TinyML offers a compelling solution by enabling OD on ultra-low-power devices, paving the way for efficient and real-time processing at the edge. Although numerous survey papers have been published on this topic, they often overlook the optimization challenges associated with deploying OD models in TinyML environments. To address this gap, this survey paper provides a detailed analysis of key optimization techniques for deploying OD models on resource-constrained devices. These techniques include quantization, pruning, knowledge distillation, and neural architecture search. Furthermore, we explore both theoretical approaches and practical implementations, bridging the gap between academic research and real-world edge artificial intelligence deployment. Finally, we compare the key performance indicators (KPIs) of existing OD implementations on microcontroller devices, highlighting the achieved maturity level of these solutions in terms of both prediction accuracy and efficiency. We also provide a public repository to continually track developments in this fast-evolving field: https://github.com/christophezei/Optimizing-Object-Detection-Models-for-TinyML-A-Comprehensive-Survey.
Can LLMs Revolutionize the Design of Explainable and Efficient TinyML Models?
Apr 13, 2025



This paper introduces a novel framework for designing efficient neural network architectures specifically tailored to tiny machine learning (TinyML) platforms. By leveraging large language models (LLMs) for neural architecture search (NAS), a vision transformer (ViT)-based knowledge distillation (KD) strategy, and an explainability module, the approach strikes an optimal balance between accuracy, computational efficiency, and memory usage. The LLM-guided search explores a hierarchical search space, refining candidate architectures through Pareto optimization based on accuracy, multiply-accumulate operations (MACs), and memory metrics. The best-performing architectures are further fine-tuned using logits-based KD with a pre-trained ViT-B/16 model, which enhances generalization without increasing model size. Evaluated on the CIFAR-100 dataset and deployed on an STM32H7 microcontroller (MCU), the three proposed models, LMaNet-Elite, LMaNet-Core, and QwNet-Core, achieve accuracy scores of 74.50%, 74.20% and 73.00%, respectively. All three models surpass current state-of-the-art (SOTA) models, such as MCUNet-in3/in4 (69.62% / 72.86%) and XiNet (72.27%), while maintaining a low computational cost of less than 100 million MACs and adhering to the stringent 320 KB static random-access memory (SRAM) constraint. These results demonstrate the efficiency and performance of the proposed framework for TinyML platforms, underscoring the potential of combining LLM-driven search, Pareto optimization, KD, and explainability to develop accurate, efficient, and interpretable models. This approach opens new possibilities in NAS, enabling the design of efficient architectures specifically suited for TinyML.
3R-INN: How to be climate friendly while consuming/delivering videos?
Mar 18, 2024



The consumption of a video requires a considerable amount of energy during the various stages of its life-cycle. With a billion hours of video consumed daily, this contributes significantly to the greenhouse gas emission. Therefore, reducing the end-to-end carbon footprint of the video chain, while preserving the quality of experience at the user side, is of high importance. To contribute in an impactful manner, we propose 3R-INN, a single light invertible network that does three tasks at once: given a high-resolution grainy image, it Rescales it to a lower resolution, Removes film grain and Reduces its power consumption when displayed. Providing such a minimum viable quality content contributes to reducing the energy consumption during encoding, transmission, decoding and display. 3R-INN also offers the possibility to restore either the high-resolution grainy original image or a grain-free version, thanks to its invertibility and the disentanglement of the high frequency, and without transmitting auxiliary data. Experiments show that, while enabling significant energy savings for encoding (78%), decoding (77%) and rendering (5% to 20%), 3R-INN outperforms state-of-the-art film grain synthesis and energy-aware methods and achieves state-of-the-art performance on the rescaling task on different test-sets.
Video Quality Assessment and Coding Complexity of the Versatile Video Coding Standard
Oct 19, 2023



In recent years, the proliferation of multimedia applications and formats, such as IPTV, Virtual Reality (VR, 360-degree), and point cloud videos, has presented new challenges to the video compression research community. Simultaneously, there has been a growing demand from users for higher resolutions and improved visual quality. To further enhance coding efficiency, a new video coding standard, Versatile Video Coding (VVC), was introduced in July 2020. This paper conducts a comprehensive analysis of coding performance and complexity for the latest VVC standard in comparison to its predecessor, High Efficiency Video Coding (HEVC). The study employs a diverse set of test sequences, covering both High Definition (HD) and Ultra High Definition (UHD) resolutions, and spans a wide range of bit-rates. These sequences are encoded using the reference software encoders of HEVC (HM) and VVC (VTM). The results consistently demonstrate that VVC outperforms HEVC, achieving bit-rate savings of up to 40% on the subjective quality scale, particularly at realistic bit-rates and quality levels. Objective quality metrics, including PSNR, SSIM, and VMAF, support these findings, revealing bit-rate savings ranging from 31% to 40%, depending on the video content, spatial resolution, and the selected quality metric. However, these improvements in coding efficiency come at the cost of significantly increased computational complexity. On average, our results indicate that the VVC decoding process is 1.5 times more complex, while the encoding process becomes at least eight times more complex than that of the HEVC reference encoder. Our simultaneous profiling of the two standards sheds light on the primary evolutionary differences between them and highlights the specific stages responsible for the observed increase in complexity.
Customizing Number Representation and Precision
Dec 08, 2022



There is a growing interest in the use of reduced-precision arithmetic, exacerbated by the recent interest in artificial intelligence, especially with deep learning. Most architectures already provide reduced-precision capabilities (e.g., 8-bit integer, 16-bit floating point). In the context of FPGAs, any number format and bit-width can even be considered.In computer arithmetic, the representation of real numbers is a major issue. Fixed-point (FxP) and floating-point (FlP) are the main options to represent reals, both with their advantages and drawbacks. This chapter presents both FxP and FlP number representations, and draws a fair a comparison between their cost, performance and energy, as well as their impact on accuracy during computations.It is shown that the choice between FxP and FlP is not obvious and strongly depends on the application considered. In some cases, low-precision floating-point arithmetic can be the most effective and provides some benefits over the classical fixed-point choice for energy-constrained applications.
Deep-based Film Grain Removal and Synthesis
Jun 15, 2022



In this paper, deep learning-based techniques for film grain removal and synthesis that can be applied in video coding are proposed. Film grain is inherent in analog film content because of the physical process of capturing images and video on film. It can also be present in digital content where it is purposely added to reflect the era of analog film and to evoke certain emotions in the viewer or enhance the perceived quality. In the context of video coding, the random nature of film grain makes it both difficult to preserve and very expensive to compress. To better preserve it while compressing the content efficiently, film grain is removed and modeled before video encoding and then restored after video decoding. In this paper, a film grain removal model based on an encoder-decoder architecture and a film grain synthesis model based on a \ac{cgan} are proposed. Both models are trained on a large dataset of pairs of clean (grain-free) and grainy images. Quantitative and qualitative evaluations of the developed solutions were conducted and showed that the proposed film grain removal model is effective in filtering film grain at different intensity levels using two configurations: 1) a non-blind configuration where the film grain level of the grainy input is known and provided as input, 2) a blind configuration where the film grain level is unknown. As for the film grain synthesis task, the experimental results show that the proposed model is able to reproduce realistic film grain with a controllable intensity level specified as input.
OpenVVC: a Lightweight Software Decoder for the Versatile Video Coding Standard
May 24, 2022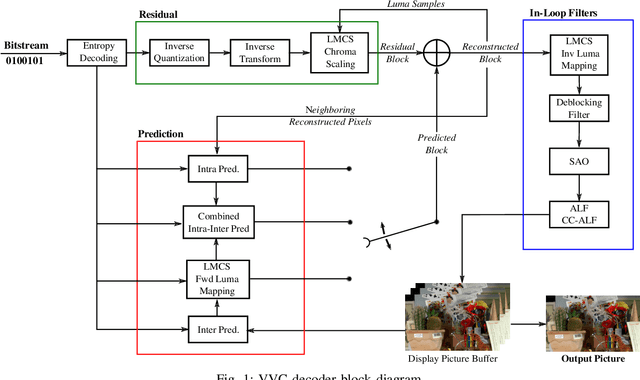
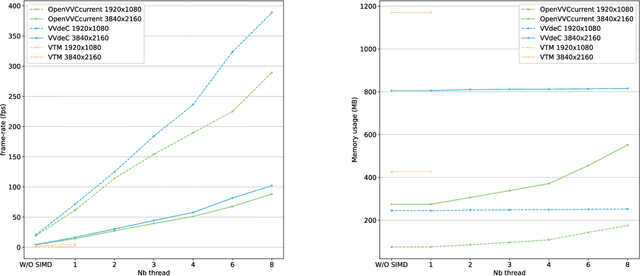
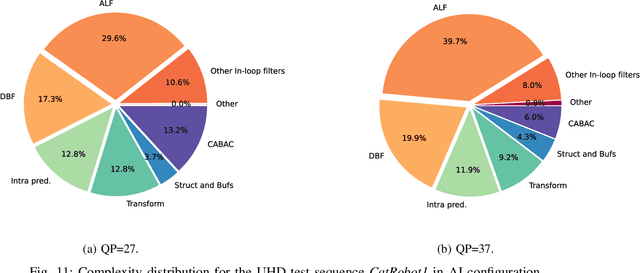
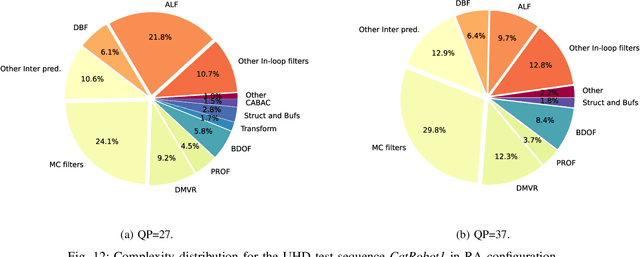
In the recent years, users requirements for higher resolution, coupled with the apparition of new multimedia applications, have created the need for a new video coding standard. The new generation video coding standard, called Versatile Video Coding (VVC), has been developed by the Joint Video Experts Team, and offers coding capability beyond the previous generation High Efficiency Video Coding (HEVC) standard. Due to the incorporation of more advanced and complex tools, the decoding complexity of VVC standard compared to HEVC has approximately doubled. This complexity increase raises new research challenges to achieve live software decoding. In this context, we developed OpenVVC, an open-source software decoder that supports a broad range of VVC functionalities. This paper presents the OpenVVC software architecture, its parallelism strategy as well as a detailed set of experimental results. By combining extensive data level parallelism with frame level parallelism, OpenVVC achieves real-time decoding of UHD video content. Moreover, the memory required by OpenVVC is remarkably low, which presents a great advantage for its integration on embedded platforms with low memory resources. The code of the OpenVVC decoder is publicly available at https://github.com/OpenVVC/OpenVVC
Versatile Video Coding Standard: A Review from Coding Tools to Consumers Deployment
Jun 27, 2021
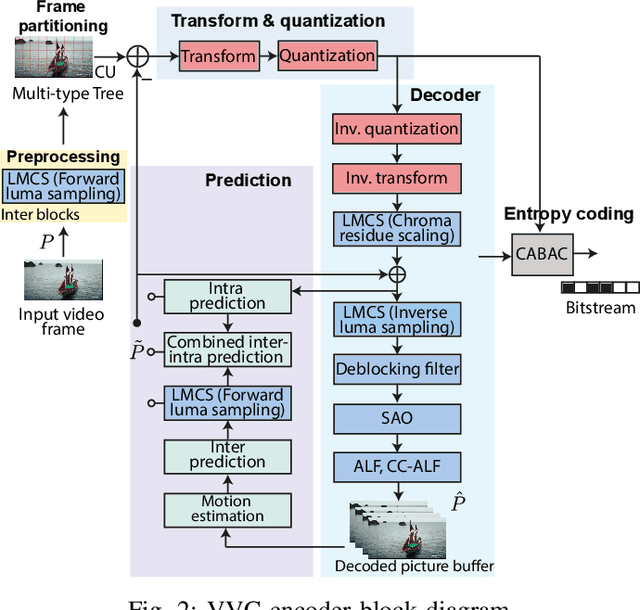

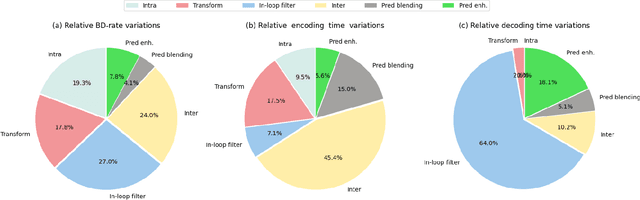
The amount of video content and the number of applications based on multimedia information increase each day. The development of new video coding standards is a challenge to increase the compression rate and other important features with a reasonable increase in the computational load. Video Experts Team (JVET) of ITU-T and the JCT group within ISO/IEC have worked together to standardize the Versatile Video Coding, approved finally in July 2020 as ITU-T H.266 | MPEG-I - Part 3 (ISO/IEC 23090-3) standard. This paper overviews some interesting consumer electronic use cases, the compression tools described in the standard, the current available real time implementations and the first industrial trials done with this standard.
Machine Learning based Efficient QT-MTT Partitioning Scheme for VVC Intra Encoders
Mar 10, 2021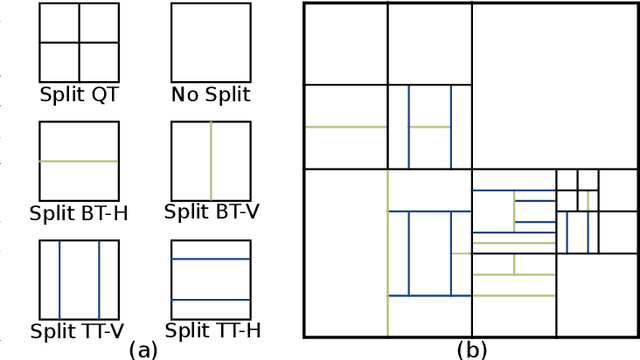
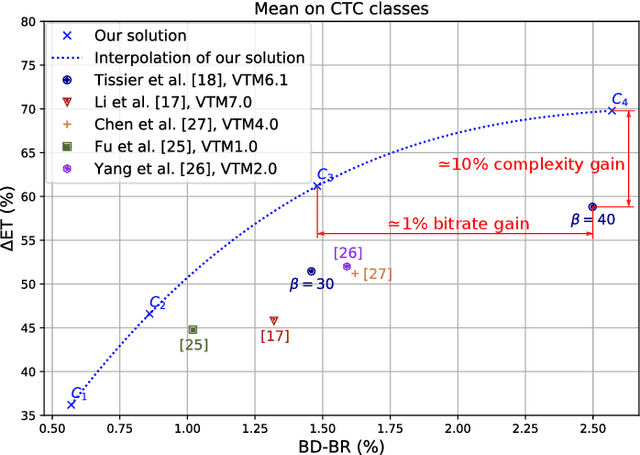
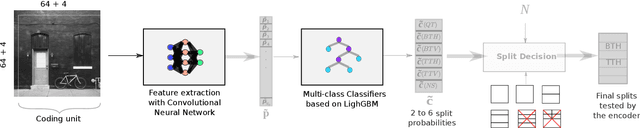
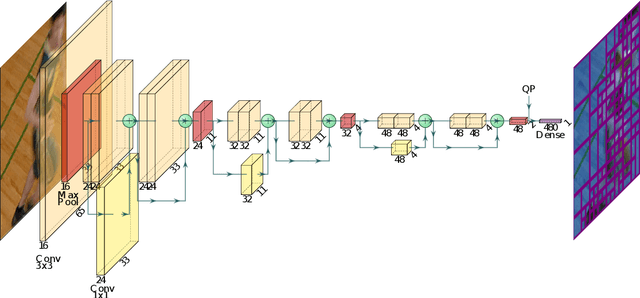
The next-generation Versatile Video Coding (VVC) standard introduces a new Multi-Type Tree (MTT) block partitioning structure that supports Binary-Tree (BT) and Ternary-Tree (TT) splits in both vertical and horizontal directions. This new approach leads to five possible splits at each block depth and thereby improves the coding efficiency of VVC over that of the preceding High Efficiency Video Coding (HEVC) standard, which only supports Quad-Tree (QT) partitioning with a single split per block depth. However, MTT also has brought a considerable impact on encoder computational complexity. In this paper, a two-stage learning-based technique is proposed to tackle the complexity overhead of MTT in VVC intra encoders. In our scheme, the input block is first processed by a Convolutional Neural Network (CNN) to predict its spatial features through a vector of probabilities describing the partition at each 4x4 edge. Subsequently, a Decision Tree (DT) model leverages this vector of spatial features to predict the most likely splits at each block. Finally, based on this prediction, only the N most likely splits are processed by the Rate-Distortion (RD) process of the encoder. In order to train our CNN and DT models on a wide range of image contents, we also propose a public VVC frame partitioning dataset based on existing image dataset encoded with the VVC reference software encoder. Our proposal relying on the top-3 configuration reaches 46.6% complexity reduction for a negligible bitrate increase of 0.86%. A top-2 configuration enables a higher complexity reduction of 69.8% for 2.57% bitrate loss. These results emphasis a better trade-off between VTM intra coding efficiency and complexity reduction compared to the state-of-the-art solutions.
Quality-Driven Dynamic VVC Frame Partitioning for Efficient Parallel Processing
Dec 29, 2020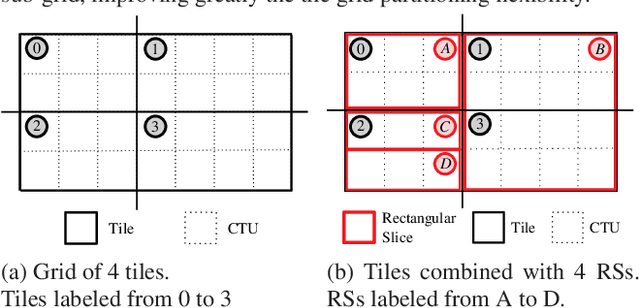
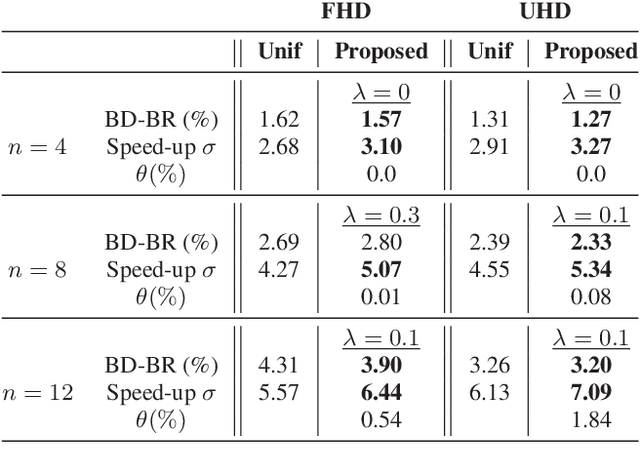

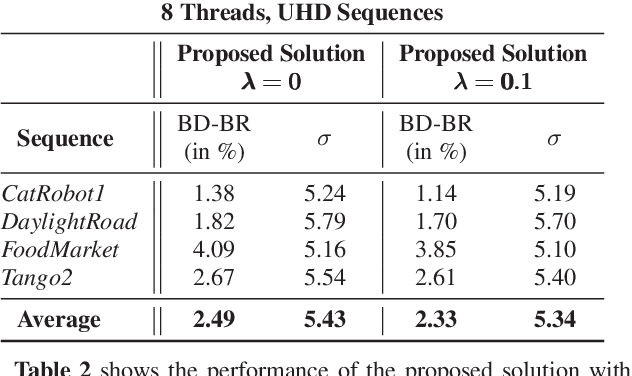
VVC is the next generation video coding standard, offering coding capability beyond HEVC standard. The high computational complexity of the latest video coding standards requires high-level parallelism techniques, in order to achieve real-time and low latency encoding and decoding. HEVC and VVC include tile grid partitioning that allows to process simultaneously rectangular regions of a frame with independent threads. The tile grid may be further partitioned into a horizontal sub-grid of Rectangular Slices (RSs), increasing the partitioning flexibility. The dynamic Tile and Rectangular Slice (TRS) partitioning solution proposed in this paper benefits from this flexibility. The TRS partitioning is carried-out at the frame level, taking into account both spatial texture of the content and encoding times of previously encoded frames. The proposed solution searches the best partitioning configuration that minimizes the trade-off between multi-thread encoding time and encoding quality loss. Experiments prove that the proposed solution, compared to uniform TRS partitioning, significantly decreases multi-thread encoding time, with slightly better encoding quality.