 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFGA-NN: Film Grain Analysis Neural Network
Jun 17, 2025

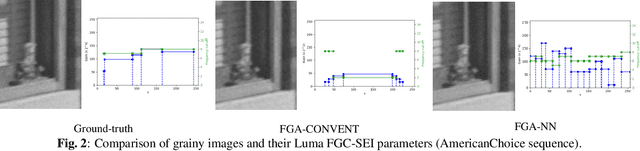
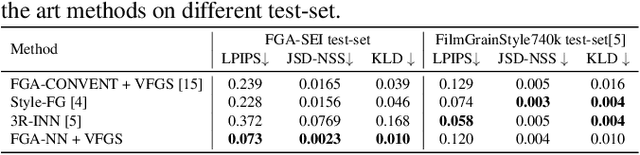
Film grain, once a by-product of analog film, is now present in most cinematographic content for aesthetic reasons. However, when such content is compressed at medium to low bitrates, film grain is lost due to its random nature. To preserve artistic intent while compressing efficiently, film grain is analyzed and modeled before encoding and synthesized after decoding. This paper introduces FGA-NN, the first learning-based film grain analysis method to estimate conventional film grain parameters compatible with conventional synthesis. Quantitative and qualitative results demonstrate FGA-NN's superior balance between analysis accuracy and synthesis complexity, along with its robustness and applicability.
3R-INN: How to be climate friendly while consuming/delivering videos?
Mar 18, 2024



The consumption of a video requires a considerable amount of energy during the various stages of its life-cycle. With a billion hours of video consumed daily, this contributes significantly to the greenhouse gas emission. Therefore, reducing the end-to-end carbon footprint of the video chain, while preserving the quality of experience at the user side, is of high importance. To contribute in an impactful manner, we propose 3R-INN, a single light invertible network that does three tasks at once: given a high-resolution grainy image, it Rescales it to a lower resolution, Removes film grain and Reduces its power consumption when displayed. Providing such a minimum viable quality content contributes to reducing the energy consumption during encoding, transmission, decoding and display. 3R-INN also offers the possibility to restore either the high-resolution grainy original image or a grain-free version, thanks to its invertibility and the disentanglement of the high frequency, and without transmitting auxiliary data. Experiments show that, while enabling significant energy savings for encoding (78%), decoding (77%) and rendering (5% to 20%), 3R-INN outperforms state-of-the-art film grain synthesis and energy-aware methods and achieves state-of-the-art performance on the rescaling task on different test-sets.
Deep-based Film Grain Removal and Synthesis
Jun 15, 2022



In this paper, deep learning-based techniques for film grain removal and synthesis that can be applied in video coding are proposed. Film grain is inherent in analog film content because of the physical process of capturing images and video on film. It can also be present in digital content where it is purposely added to reflect the era of analog film and to evoke certain emotions in the viewer or enhance the perceived quality. In the context of video coding, the random nature of film grain makes it both difficult to preserve and very expensive to compress. To better preserve it while compressing the content efficiently, film grain is removed and modeled before video encoding and then restored after video decoding. In this paper, a film grain removal model based on an encoder-decoder architecture and a film grain synthesis model based on a \ac{cgan} are proposed. Both models are trained on a large dataset of pairs of clean (grain-free) and grainy images. Quantitative and qualitative evaluations of the developed solutions were conducted and showed that the proposed film grain removal model is effective in filtering film grain at different intensity levels using two configurations: 1) a non-blind configuration where the film grain level of the grainy input is known and provided as input, 2) a blind configuration where the film grain level is unknown. As for the film grain synthesis task, the experimental results show that the proposed model is able to reproduce realistic film grain with a controllable intensity level specified as input.