 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3R-INN: How to be climate friendly while consuming/delivering videos?
Mar 18, 2024



The consumption of a video requires a considerable amount of energy during the various stages of its life-cycle. With a billion hours of video consumed daily, this contributes significantly to the greenhouse gas emission. Therefore, reducing the end-to-end carbon footprint of the video chain, while preserving the quality of experience at the user side, is of high importance. To contribute in an impactful manner, we propose 3R-INN, a single light invertible network that does three tasks at once: given a high-resolution grainy image, it Rescales it to a lower resolution, Removes film grain and Reduces its power consumption when displayed. Providing such a minimum viable quality content contributes to reducing the energy consumption during encoding, transmission, decoding and display. 3R-INN also offers the possibility to restore either the high-resolution grainy original image or a grain-free version, thanks to its invertibility and the disentanglement of the high frequency, and without transmitting auxiliary data. Experiments show that, while enabling significant energy savings for encoding (78%), decoding (77%) and rendering (5% to 20%), 3R-INN outperforms state-of-the-art film grain synthesis and energy-aware methods and achieves state-of-the-art performance on the rescaling task on different test-sets.
Where to look at the movies : Analyzing visual attention to understand movie editing
Feb 26, 2021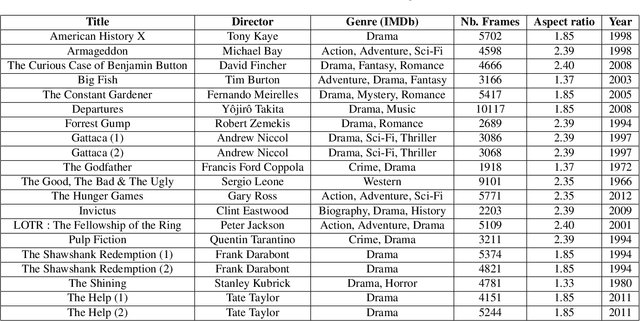
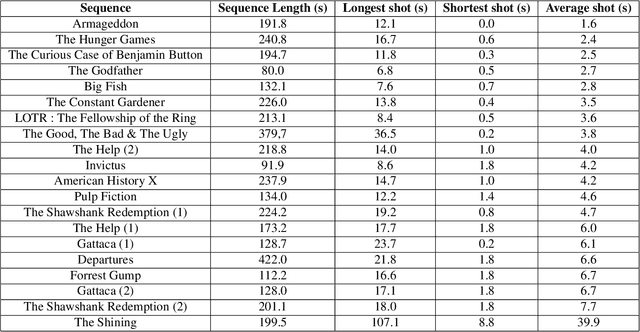


In the process of making a movie, directors constantly care about where the spectator will look on the screen. Shot composition, framing, camera movements or editing are tools commonly used to direct attention. In order to provide a quantitative analysis of the relationship between those tools and gaze patterns, we propose a new eye-tracking database, containing gaze pattern information on movie sequences, as well as editing annotations, and we show how state-of-the-art computational saliency techniques behave on this dataset. In this work, we expose strong links between movie editing and spectators scanpaths, and open several leads on how the knowledge of editing information could improve human visual attention modeling for cinematic content. The dataset generated and analysed during the current study is available at https://github.com/abruckert/eye_tracking_filmmaking
Deep Saliency Models : The Quest For The Loss Function
Jul 04, 2019

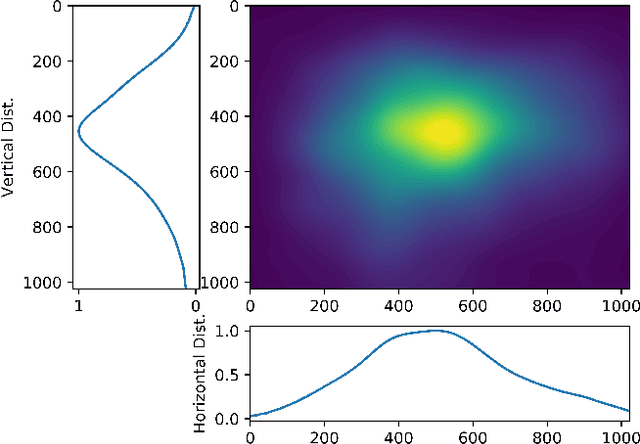
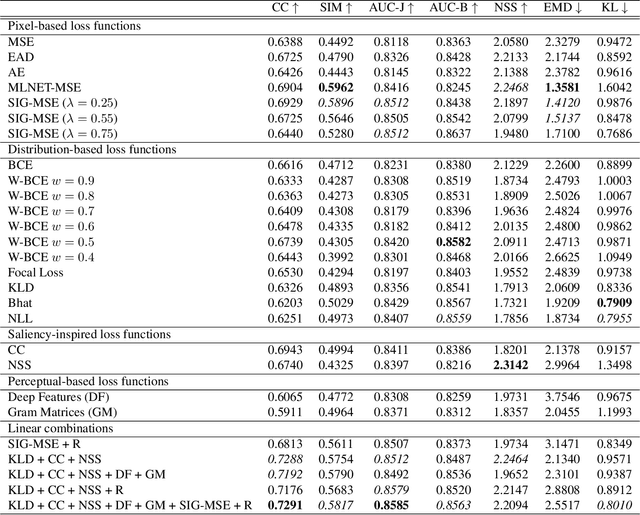
Recent advances in deep learning have pushed the performances of visual saliency models way further than it has ever been. Numerous models in the literature present new ways to design neural networks, to arrange gaze pattern data, or to extract as much high and low-level image features as possible in order to create the best saliency representation. However, one key part of a typical deep learning model is often neglected: the choice of the loss function. In this work, we explore some of the most popular loss functions that are used in deep saliency models. We demonstrate that on a fixed network architecture, modifying the loss function can significantly improve (or depreciate) the results, hence emphasizing the importance of the choice of the loss function when designing a model. We also introduce new loss functions that have never been used for saliency prediction to our knowledge. And finally, we show that a linear combination of several well-chosen loss functions leads to significant improvements in performances on different datasets as well as on a different network architecture, hence demonstrating the robustness of a combined metric.
Computational Model for Predicting Visual Fixations from Childhood to Adulthood
Feb 15, 2017


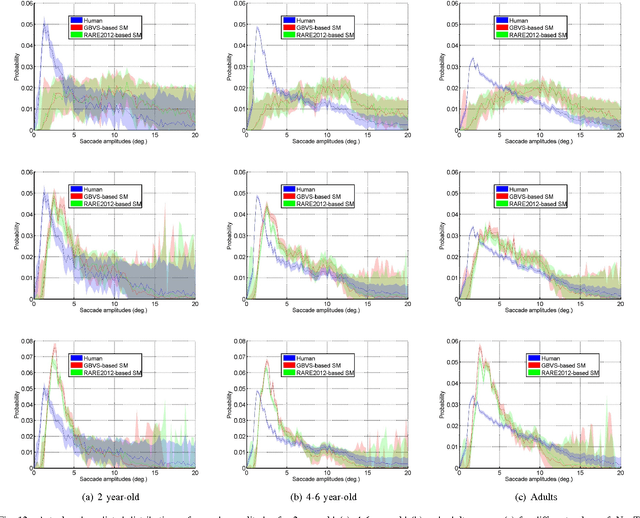
How people look at visual information reveals fundamental information about themselves, their interests and their state of mind. While previous visual attention models output static 2-dimensional saliency maps, saccadic models aim to predict not only where observers look at but also how they move their eyes to explore the scene. Here we demonstrate that saccadic models are a flexible framework that can be tailored to emulate observer's viewing tendencies. More specifically, we use the eye data from 101 observers split in 5 age groups (adults, 8-10 y.o., 6-8 y.o., 4-6 y.o. and 2 y.o.) to train our saccadic model for different stages of the development of the human visual system. We show that the joint distribution of saccade amplitude and orientation is a visual signature specific to each age group, and can be used to generate age-dependent scanpaths. Our age-dependent saccadic model not only outputs human-like, age-specific visual scanpath, but also significantly outperforms other state-of-the-art saliency models. In this paper, we demonstrate that the computational modelling of visual attention, through the use of saccadic model, can be efficiently adapted to emulate the gaze behavior of a specific group of observers.