 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCapturing and Explaining Trajectory Singularities using Composite Signal Neural Networks
Mar 24, 2020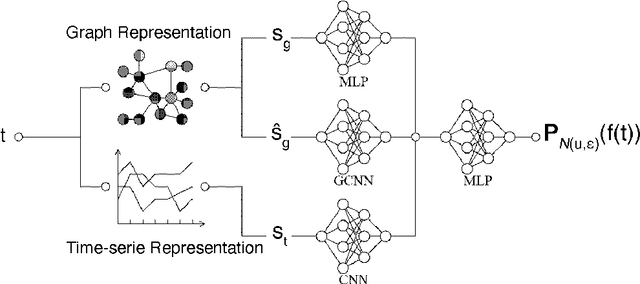
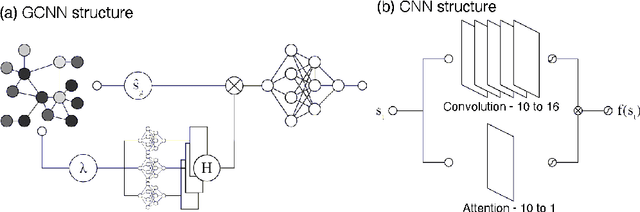
Spatial trajectories are ubiquitous and complex signals. Their analysis is crucial in many research fields, from urban planning to neuroscience. Several approaches have been proposed to cluster trajectories. They rely on hand-crafted features, which struggle to capture the spatio-temporal complexity of the signal, or on Artificial Neural Networks (ANNs) which can be more efficient but less interpretable. In this paper we present a novel ANN architecture designed to capture the spatio-temporal patterns characteristic of a set of trajectories, while taking into account the demographics of the navigators. Hence, our model extracts markers linked to both behaviour and demographics. We propose a composite signal analyser (CompSNN) combining three simple ANN modules. Each of these modules uses different signal representations of the trajectory while remaining interpretable. Our CompSNN performs significantly better than its modules taken in isolation and allows to visualise which parts of the signal were most useful to discriminate the trajectories.
Computational Model for Predicting Visual Fixations from Childhood to Adulthood
Feb 15, 2017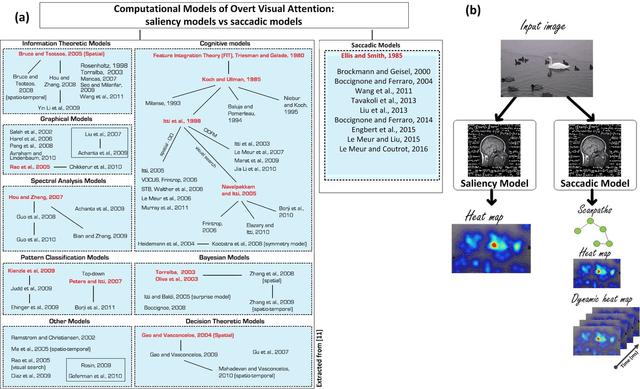


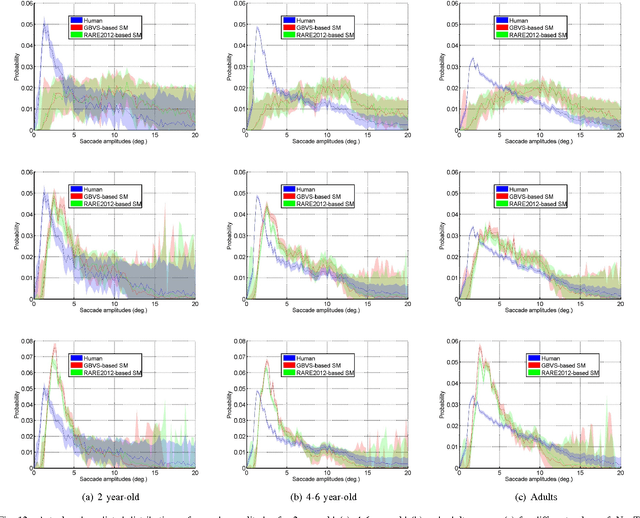
How people look at visual information reveals fundamental information about themselves, their interests and their state of mind. While previous visual attention models output static 2-dimensional saliency maps, saccadic models aim to predict not only where observers look at but also how they move their eyes to explore the scene. Here we demonstrate that saccadic models are a flexible framework that can be tailored to emulate observer's viewing tendencies. More specifically, we use the eye data from 101 observers split in 5 age groups (adults, 8-10 y.o., 6-8 y.o., 4-6 y.o. and 2 y.o.) to train our saccadic model for different stages of the development of the human visual system. We show that the joint distribution of saccade amplitude and orientation is a visual signature specific to each age group, and can be used to generate age-dependent scanpaths. Our age-dependent saccadic model not only outputs human-like, age-specific visual scanpath, but also significantly outperforms other state-of-the-art saliency models. In this paper, we demonstrate that the computational modelling of visual attention, through the use of saccadic model, can be efficiently adapted to emulate the gaze behavior of a specific group of observers.
Learning a time-dependent master saliency map from eye-tracking data in videos
Feb 02, 2017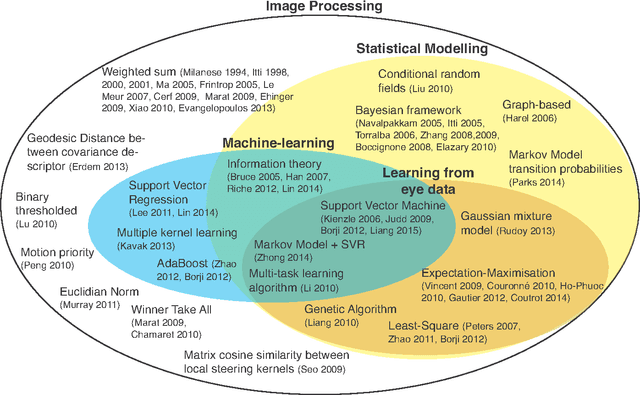
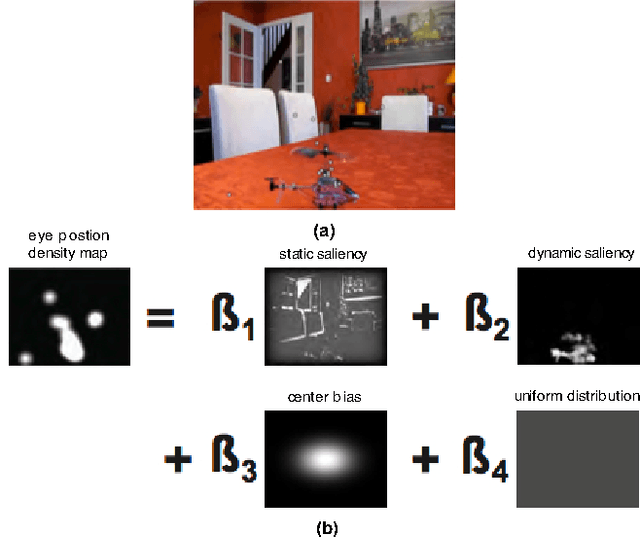
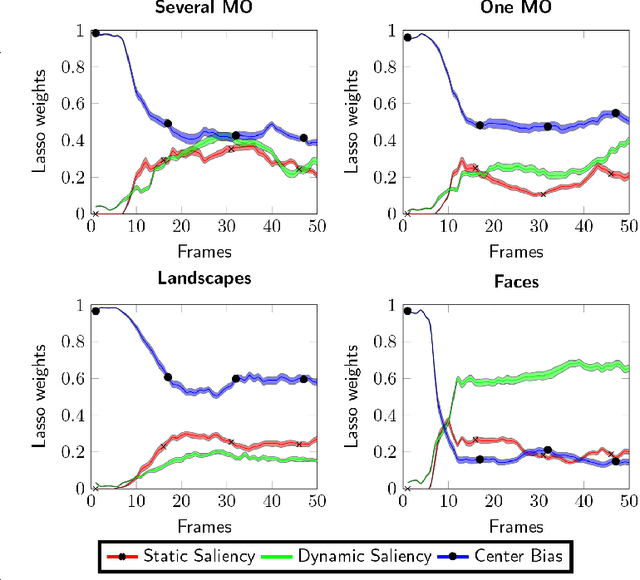
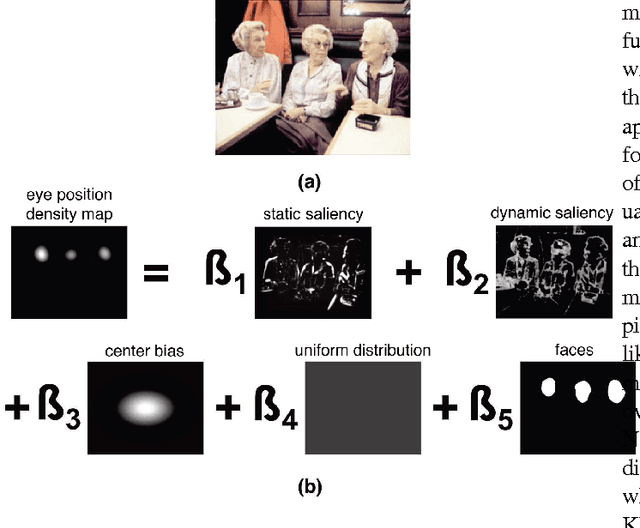
To predict the most salient regions of complex natural scenes, saliency models commonly compute several feature maps (contrast, orientation, motion...) and linearly combine them into a master saliency map. Since feature maps have different spatial distribution and amplitude dynamic ranges, determining their contributions to overall saliency remains an open problem. Most state-of-the-art models do not take time into account and give feature maps constant weights across the stimulus duration. However, visual exploration is a highly dynamic process shaped by many time-dependent factors. For instance, some systematic viewing patterns such as the center bias are known to dramatically vary across the time course of the exploration. In this paper, we use maximum likelihood and shrinkage methods to dynamically and jointly learn feature map and systematic viewing pattern weights directly from eye-tracking data recorded on videos. We show that these weights systematically vary as a function of time, and heavily depend upon the semantic visual category of the videos being processed. Our fusion method allows taking these variations into account, and outperforms other state-of-the-art fusion schemes using constant weights over time. The code, videos and eye-tracking data we used for this study are available online: http://antoinecoutrot.magix.net/public/research.html