 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning a time-dependent master saliency map from eye-tracking data in videos
Feb 02, 2017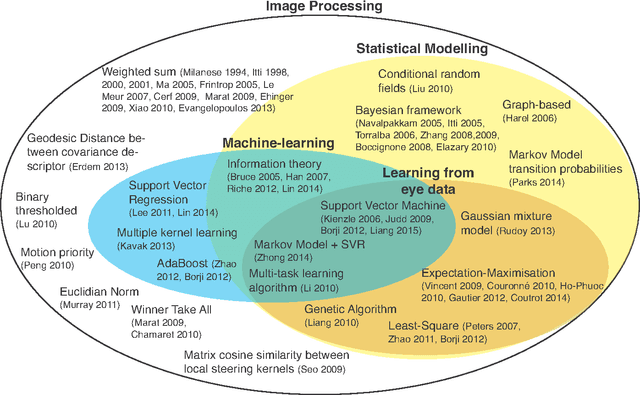
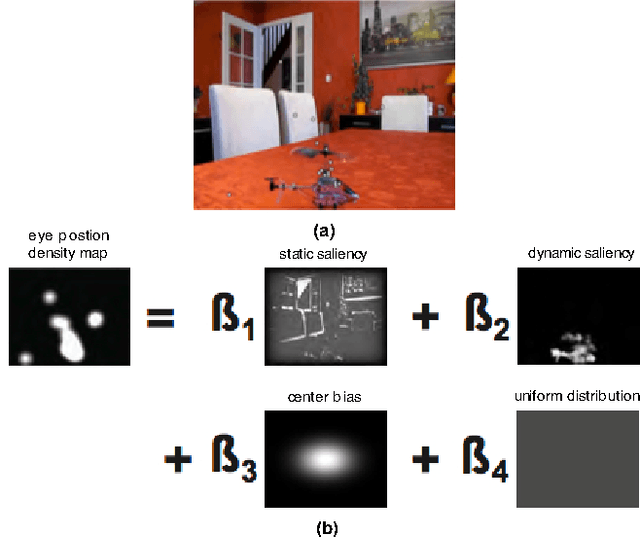
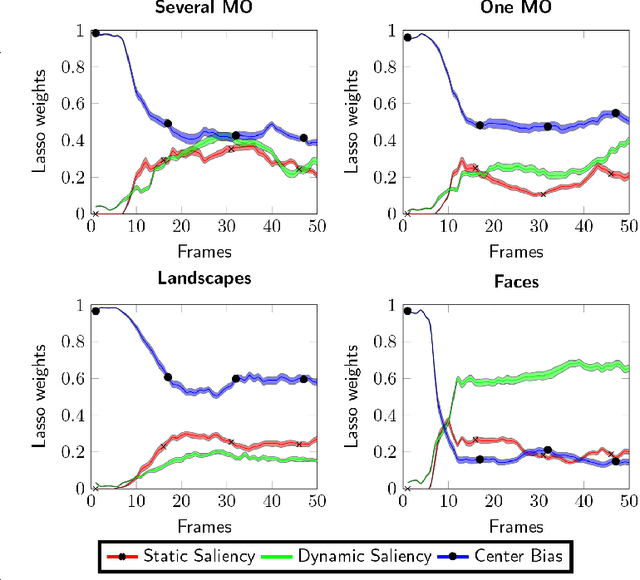
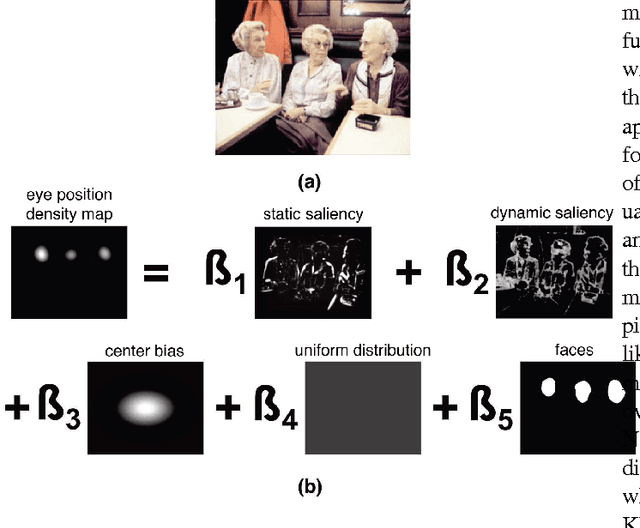
To predict the most salient regions of complex natural scenes, saliency models commonly compute several feature maps (contrast, orientation, motion...) and linearly combine them into a master saliency map. Since feature maps have different spatial distribution and amplitude dynamic ranges, determining their contributions to overall saliency remains an open problem. Most state-of-the-art models do not take time into account and give feature maps constant weights across the stimulus duration. However, visual exploration is a highly dynamic process shaped by many time-dependent factors. For instance, some systematic viewing patterns such as the center bias are known to dramatically vary across the time course of the exploration. In this paper, we use maximum likelihood and shrinkage methods to dynamically and jointly learn feature map and systematic viewing pattern weights directly from eye-tracking data recorded on videos. We show that these weights systematically vary as a function of time, and heavily depend upon the semantic visual category of the videos being processed. Our fusion method allows taking these variations into account, and outperforms other state-of-the-art fusion schemes using constant weights over time. The code, videos and eye-tracking data we used for this study are available online: http://antoinecoutrot.magix.net/public/research.html