 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKANtize: Exploring Low-bit Quantization of Kolmogorov-Arnold Networks for Efficient Inference
Mar 18, 2026Kolmogorov-Arnold Networks (KANs) have gained attention for their potential to outperform Multi-Layer Perceptrons (MLPs) in terms of parameter efficiency and interpretability. Unlike traditional MLPs, KANs use learnable non-linear activation functions, typically spline functions, expressed as linear combinations of basis splines (B-splines). B-spline coefficients serve as the model's learnable parameters. However, evaluating these spline functions increases computational complexity during inference. Conventional quantization reduces this complexity by lowering the numerical precision of parameters and activations. However, the impact of quantization on KANs, and especially its effectiveness in reducing computational complexity, is largely unexplored, particularly for quantization levels below 8 bits. The study investigates the impact of low-bit quantization on KANs and its impact on computational complexity and hardware efficiency. Results show that B-splines can be quantized to 2-3 bits with negligible loss in accuracy, significantly reducing computational complexity. Hence, we investigate the potential of using low-bit quantized precomputed tables as a replacement for the recursive B-spline algorithm. This approach aims to further reduce the computational complexity of KANs and enhance hardware efficiency while maintaining accuracy. For example, ResKAN18 achieves a 50x reduction in BitOps without loss of accuracy using low-bit-quantized B-spline tables. Additionally, precomputed 8-bit lookup tables improve GPU inference speedup by up to 2.9x, while on FPGA-based systolic-array accelerators, reducing B-spline table precision from 8 to 3 bits cuts resource usage by 36%, increases clock frequency by 50%, and enhances speedup by 1.24x. On a 28nm FD-SOI ASIC, reducing the B-spline bit-width from 16 to 3 bits achieves 72% area reduction and 50% higher maximum frequency.
A Hard-Label Cryptanalytic Extraction of Non-Fully Connected Deep Neural Networks using Side-Channel Attacks
Nov 15, 2024During the past decade, Deep Neural Networks (DNNs) proved their value on a large variety of subjects. However despite their high value and public accessibility, the protection of the intellectual property of DNNs is still an issue and an emerging research field. Recent works have successfully extracted fully-connected DNNs using cryptanalytic methods in hard-label settings, proving that it was possible to copy a DNN with high fidelity, i.e., high similitude in the output predictions. However, the current cryptanalytic attacks cannot target complex, i.e., not fully connected, DNNs and are limited to special cases of neurons present in deep networks. In this work, we introduce a new end-to-end attack framework designed for model extraction of embedded DNNs with high fidelity. We describe a new black-box side-channel attack which splits the DNN in several linear parts for which we can perform cryptanalytic extraction and retrieve the weights in hard-label settings. With this method, we are able to adapt cryptanalytic extraction, for the first time, to non-fully connected DNNs, while maintaining a high fidelity. We validate our contributions by targeting several architectures implemented on a microcontroller unit, including a Multi-Layer Perceptron (MLP) of 1.7 million parameters and a shortened MobileNetv1. Our framework successfully extracts all of these DNNs with high fidelity (88.4% for the MobileNetv1 and 93.2% for the MLP). Furthermore, we use the stolen model to generate adversarial examples and achieve close to white-box performance on the victim's model (95.8% and 96.7% transfer rate).
AdaQAT: Adaptive Bit-Width Quantization-Aware Training
Apr 22, 2024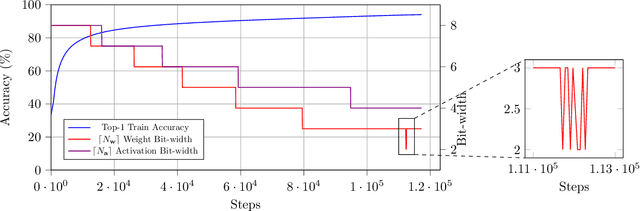
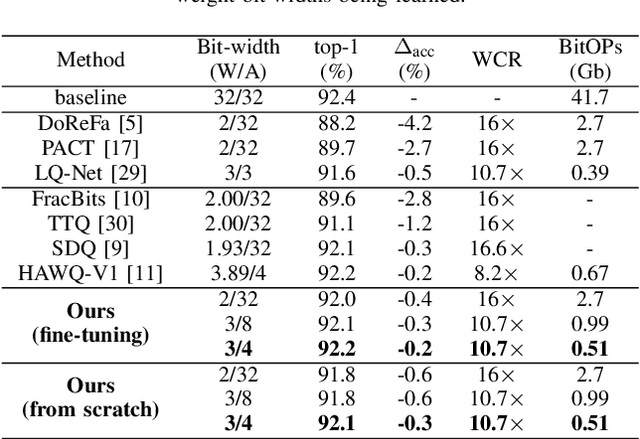
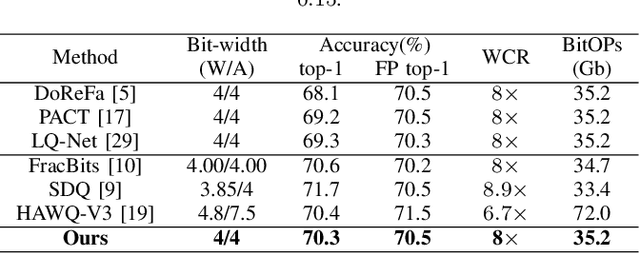
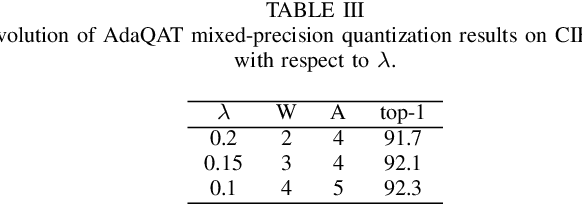
Large-scale deep neural networks (DNNs) have achieved remarkable success in many application scenarios. However, high computational complexity and energy costs of modern DNNs make their deployment on edge devices challenging. Model quantization is a common approach to deal with deployment constraints, but searching for optimized bit-widths can be challenging. In this work, we present Adaptive Bit-Width Quantization Aware Training (AdaQAT), a learning-based method that automatically optimizes weight and activation signal bit-widths during training for more efficient DNN inference. We use relaxed real-valued bit-widths that are updated using a gradient descent rule, but are otherwise discretized for all quantization operations. The result is a simple and flexible QAT approach for mixed-precision uniform quantization problems. Compared to other methods that are generally designed to be run on a pretrained network, AdaQAT works well in both training from scratch and fine-tuning scenarios.Initial results on the CIFAR-10 and ImageNet datasets using ResNet20 and ResNet18 models, respectively, indicate that our method is competitive with other state-of-the-art mixed-precision quantization approaches.
When Side-Channel Attacks Break the Black-Box Property of Embedded Artificial Intelligence
Nov 23, 2023Artificial intelligence, and specifically deep neural networks (DNNs), has rapidly emerged in the past decade as the standard for several tasks from specific advertising to object detection. The performance offered has led DNN algorithms to become a part of critical embedded systems, requiring both efficiency and reliability. In particular, DNNs are subject to malicious examples designed in a way to fool the network while being undetectable to the human observer: the adversarial examples. While previous studies propose frameworks to implement such attacks in black box settings, those often rely on the hypothesis that the attacker has access to the logits of the neural network, breaking the assumption of the traditional black box. In this paper, we investigate a real black box scenario where the attacker has no access to the logits. In particular, we propose an architecture-agnostic attack which solve this constraint by extracting the logits. Our method combines hardware and software attacks, by performing a side-channel attack that exploits electromagnetic leakages to extract the logits for a given input, allowing an attacker to estimate the gradients and produce state-of-the-art adversarial examples to fool the targeted neural network. Through this example of adversarial attack, we demonstrate the effectiveness of logits extraction using side-channel as a first step for more general attack frameworks requiring either the logits or the confidence scores.
Low-Precision Floating-Point for Efficient On-Board Deep Neural Network Processing
Nov 18, 2023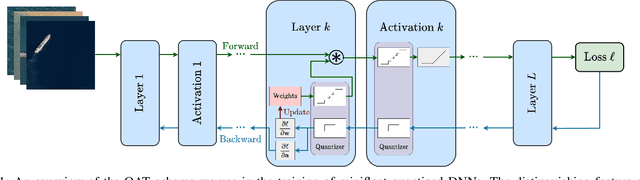
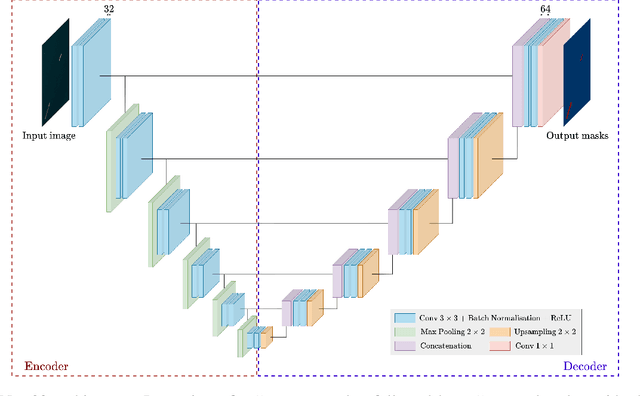
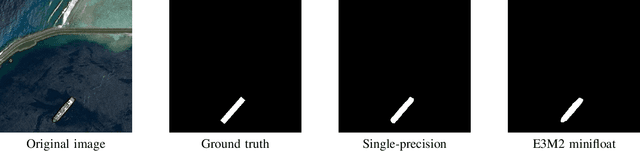

One of the major bottlenecks in high-resolution Earth Observation (EO) space systems is the downlink between the satellite and the ground. Due to hardware limitations, on-board power limitations or ground-station operation costs, there is a strong need to reduce the amount of data transmitted. Various processing methods can be used to compress the data. One of them is the use of on-board deep learning to extract relevant information in the data. However, most ground-based deep neural network parameters and computations are performed using single-precision floating-point arithmetic, which is not adapted to the context of on-board processing. We propose to rely on quantized neural networks and study how to combine low precision (mini) floating-point arithmetic with a Quantization-Aware Training methodology. We evaluate our approach with a semantic segmentation task for ship detection using satellite images from the Airbus Ship dataset. Our results show that 6-bit floating-point quantization for both weights and activations can compete with single-precision without significant accuracy degradation. Using a Thin U-Net 32 model, only a 0.3% accuracy degradation is observed with 6-bit minifloat quantization (a 6-bit equivalent integer-based approach leads to a 0.5% degradation). An initial hardware study also confirms the potential impact of such low-precision floating-point designs, but further investigation at the scale of a full inference accelerator is needed before concluding whether they are relevant in a practical on-board scenario.
Customizing Number Representation and Precision
Dec 08, 2022



There is a growing interest in the use of reduced-precision arithmetic, exacerbated by the recent interest in artificial intelligence, especially with deep learning. Most architectures already provide reduced-precision capabilities (e.g., 8-bit integer, 16-bit floating point). In the context of FPGAs, any number format and bit-width can even be considered.In computer arithmetic, the representation of real numbers is a major issue. Fixed-point (FxP) and floating-point (FlP) are the main options to represent reals, both with their advantages and drawbacks. This chapter presents both FxP and FlP number representations, and draws a fair a comparison between their cost, performance and energy, as well as their impact on accuracy during computations.It is shown that the choice between FxP and FlP is not obvious and strongly depends on the application considered. In some cases, low-precision floating-point arithmetic can be the most effective and provides some benefits over the classical fixed-point choice for energy-constrained applications.
Approximations in Deep Learning
Dec 08, 2022The design and implementation of Deep Learning (DL) models is currently receiving a lot of attention from both industrials and academics. However, the computational workload associated with DL is often out of reach for low-power embedded devices and is still costly when run on datacenters. By relaxing the need for fully precise operations, Approximate Computing (AxC) substantially improves performance and energy efficiency. DL is extremely relevant in this context, since playing with the accuracy needed to do adequate computations will significantly enhance performance, while keeping the quality of results in a user-constrained range. This chapter will explore how AxC can improve the performance and energy efficiency of hardware accelerators in DL applications during inference and training.