 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Quality Assessment and Coding Complexity of the Versatile Video Coding Standard
Oct 19, 2023



In recent years, the proliferation of multimedia applications and formats, such as IPTV, Virtual Reality (VR, 360-degree), and point cloud videos, has presented new challenges to the video compression research community. Simultaneously, there has been a growing demand from users for higher resolutions and improved visual quality. To further enhance coding efficiency, a new video coding standard, Versatile Video Coding (VVC), was introduced in July 2020. This paper conducts a comprehensive analysis of coding performance and complexity for the latest VVC standard in comparison to its predecessor, High Efficiency Video Coding (HEVC). The study employs a diverse set of test sequences, covering both High Definition (HD) and Ultra High Definition (UHD) resolutions, and spans a wide range of bit-rates. These sequences are encoded using the reference software encoders of HEVC (HM) and VVC (VTM). The results consistently demonstrate that VVC outperforms HEVC, achieving bit-rate savings of up to 40% on the subjective quality scale, particularly at realistic bit-rates and quality levels. Objective quality metrics, including PSNR, SSIM, and VMAF, support these findings, revealing bit-rate savings ranging from 31% to 40%, depending on the video content, spatial resolution, and the selected quality metric. However, these improvements in coding efficiency come at the cost of significantly increased computational complexity. On average, our results indicate that the VVC decoding process is 1.5 times more complex, while the encoding process becomes at least eight times more complex than that of the HEVC reference encoder. Our simultaneous profiling of the two standards sheds light on the primary evolutionary differences between them and highlights the specific stages responsible for the observed increase in complexity.
CAESR: Conditional Autoencoder and Super-Resolution for Learned Spatial Scalability
Feb 01, 2022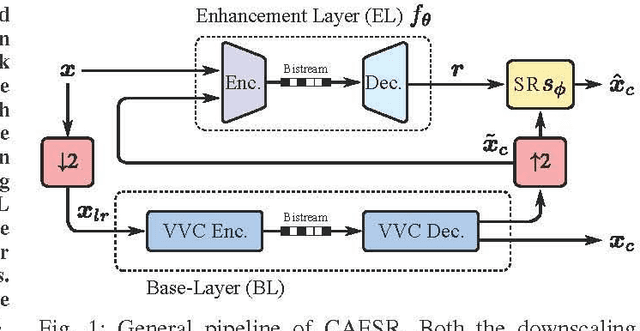
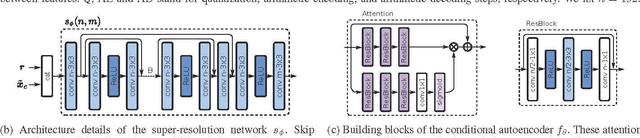
In this paper, we present CAESR, an hybrid learning-based coding approach for spatial scalability based on the versatile video coding (VVC) standard. Our framework considers a low-resolution signal encoded with VVC intra-mode as a base-layer (BL), and a deep conditional autoencoder with hyperprior (AE-HP) as an enhancement-layer (EL) model. The EL encoder takes as inputs both the upscaled BL reconstruction and the original image. Our approach relies on conditional coding that learns the optimal mixture of the source and the upscaled BL image, enabling better performance than residual coding. On the decoder side, a super-resolution (SR) module is used to recover high-resolution details and invert the conditional coding process. Experimental results have shown that our solution is competitive with the VVC full-resolution intra coding while being scalable.
Perceptual Quality Assessment of HEVC and VVC Standards for 8K Video
Sep 17, 2021

With the growing data consumption of emerging video applications and users requirement for higher resolutions, up to 8K, a huge effort has been made in video compression technologies. Recently, versatile video coding (VVC) has been standardized by the moving picture expert group (MPEG), providing a significant improvement in compression performance over its predecessor high efficiency video coding (HEVC). In this paper, we provide a comparative subjective quality evaluation between VVC and HEVC standards for 8K resolution videos. In addition, we evaluate the perceived quality improvement offered by 8K over UHD 4K resolution. The compression performance of both VVC and HEVC standards has been conducted in random access (RA) coding configuration, using their respective reference software, VVC test model (VTM-11) and HEVC test model (HM-16.20). Objective measurements, using PSNR, MS-SSIM and VMAF metrics have shown that the bitrate gains offered by VVC over HEVC for 8K video content are around 31%, 26% and 35%, respectively. Subjectively, VVC offers an average of 40% of bitrate reduction over HEVC for the same visual quality. A compression gain of 50% has been reached for some tested video sequences regarding a Student t-test analysis. In addition, for most tested scenes, a significant visual difference between uncompressed 4K and 8K has been noticed.
Multitask Learning for VVC Quality Enhancement and Super-Resolution
May 03, 2021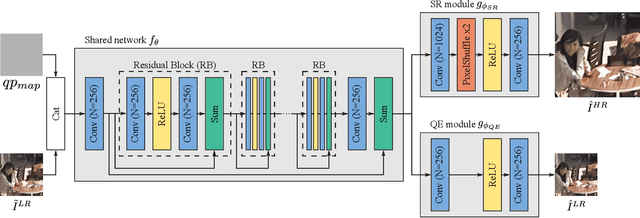
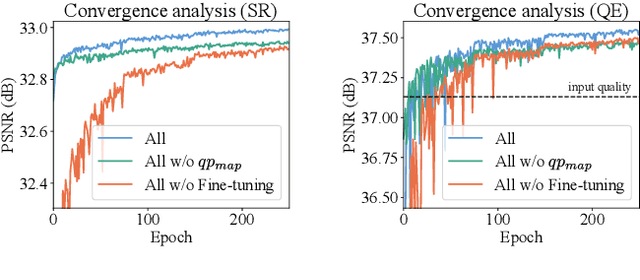

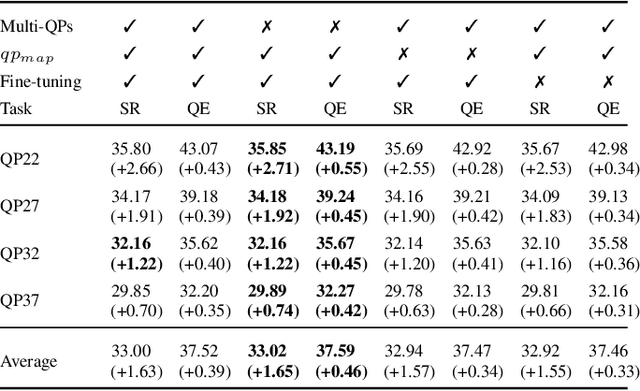
The latest video coding standard, called versatile video coding (VVC), includes several novel and refined coding tools at different levels of the coding chain. These tools bring significant coding gains with respect to the previous standard, high efficiency video coding (HEVC). However, the encoder may still introduce visible coding artifacts, mainly caused by coding decisions applied to adjust the bitrate to the available bandwidth. Hence, pre and post-processing techniques are generally added to the coding pipeline to improve the quality of the decoded video. These methods have recently shown outstanding results compared to traditional approaches, thanks to the recent advances in deep learning. Generally, multiple neural networks are trained independently to perform different tasks, thus omitting to benefit from the redundancy that exists between the models. In this paper, we investigate a learning-based solution as a post-processing step to enhance the decoded VVC video quality. Our method relies on multitask learning to perform both quality enhancement and super-resolution using a single shared network optimized for multiple degradation levels. The proposed solution enables a good performance in both mitigating coding artifacts and super-resolution with fewer network parameters compared to traditional specialized architectures.